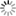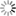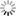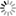Bibliografická metadata v sémantickém webu
Klíčová slova: metadata, sémantický web, bibliografická metadata, propojená bibliografická data, propojená knihovní data
Summary: The study offers a current view on bibliographic metadata, integrated into the broader context of the global information environment of the Semantic Web. It points out the relative nature of metadata definition and their intersection with related entities. It presents the theoretical problems of defining the concept of metadata caused by the missing generally accepted definitions of data, information resource and document. It describes important aspects from which to look at metadata: metadata as a structure, including the structure of the metadata in the Semantic Web, metadata as a function, language, and model. It proposes a general metadata typology based on facet analysis. Attention is paid to bibliographic metadata, which are created by memory and fund institutions. Possibilities of integrating bibliographic metadata created by libraries into Semantic Web are considered.
Keywords: metadata, Semantic Web, bibliographic metadata, linked bibliographic data, library linked data
PhDr. Helena Kučerová, Ph.D. / Ústav informačních studií a knihovnictví FF UK v Praze (Institute of Information Studies and Librarianship, Faculty of Arts, Charles University in Prague), Filozofická fakulta Univerzity Karlovy, U Kříže 8, 158 00 Praha 5 – Jinonice

V moderní éře všudypřítomné výpočetní techniky se metadata stala infrastrukturou jako elektrická síť nebo dálniční systém.
Jeffrey Pomerantz, 2015
Pokud máte dostatek metadat, opravdu nepotřebujete obsah.1
Stewart Baker, 2014
Úvod
Není těžké zformulovat důvody potvrzující klíčový význam metadat pro komunikaci informací ve společnosti. Stejně jako to Jeffrey Pomerantz konstatoval o výpočetní technice, lze i o metadatech prohlásit, že jsou všudypřítomná. Stačí jen připomenout, že bez metadat se neobejdou paměťové a fondové instituce ani veřejné či podnikové informační a komunikační systémy. Závisí na nich fungování informačního, kreativního a mediálního průmyslu a obchodu. Metadata tvoří nedílnou součást datových úložišť všeho druhu, jakož i digitálních knihoven a repozitářů a v neposlední řadě jsou ústřední komponentou sémantického webu. Navíc oblast použití metadat není jen široká, je i nesmírně rozmanitá. Výroky uvedené v mottu dokládají tuto pestrost už osobami svých autorů: Jeffrey Pomerantz je informační vědec, univerzitní profesor a konzultant, zatímco Stewart Baker byl v letech 1992–1994 generálním radou americké Národní bezpečnostní agentury (NSA). Jejich výroky pak ve zkratce výstižně charakterizují dva základní rysy metadat, jež by bylo možné v analogii ke dvěma způsobům reprezentace znalostí označit jako procedurální a deklarativní.
Pomerantz charakterizuje metadata procedurálně jako infrastrukturu společenské komunikace, tedy jako nástroj umožňující komunikaci v nejširším slova smyslu (nejen přenos a uchování v prostoru i v čase, ale i sdílení a společnou práci umožněnou sdílenými informacemi) (Pomerantz, 2015, s. 3). Metadata v procedurálním pohledu umožňují plnit funkce informačních zdrojů a provádět s nimi veškeré potřebné operace.
Poněkud provokativní vyjádření Stewarta Bakera o náhradě obsahu metadaty bylo motivováno zveřejněním skutečnosti, že metadata o telefonních hovorech jsou využívána americkou zpravodajskou službou při bezpečnostních analýzách.2 V obecnějším smyslu však upozorňuje na další významnou úlohu metadat, jíž je reprezentace samotného zdroje. Metadata v deklarativním neboli popisném slova smyslu jsou tedy vytvářena s cílem zastupovat či dokonce doplňovat informační zdroj nebo jeho část včetně jeho obsahu.
V tom, že metadata jsou zásadní složkou jakékoli formy komunikace informací a jsou podmínkou vyhledávání, zpřístupňování a namnoze i smysluplného využití informací, panuje tedy všeobecný konsenzus. Překvapivé obtíže ale nastávají při pokusu o jednoznačné vymezení obsahu tohoto pojmu. Příčinou problémů s definováním metadat je jednak již zmíněná šíře a rozmanitost oblastí jejich použití, jednak jejich sepětí s informačním zdrojem, jenž postrádá jednoznačnou obecně přijímanou definici. V tomto článku se pokusíme pokročit za hranice populárního tvrzení „metadata jsou data o datech“ a navázat na pionýrskou studii Evy Bratkové (1999), která problematiku metadat a jejich tehdejších aplikací představila české odborné veřejnosti již v roce 1999. Zaměříme se na tyto cíle:
1) Přispět ke zformulování obecné definice metadat prostřednictvím jejich zevrubné charakteristiky.
2) Začlenit bibliografická metadata produkovaná knihovnami do kontextu ostatních typů metadat.
3) Posoudit možnost použití bibliografických metadat vytvářených knihovnami v prostředí sémantického webu.
V souvislosti s prvním vytčeným cílem se může naskytnout otázka, zda je vůbec potřebné formulovat obecně akceptovanou definici metadat. Zdůvodnění kladné odpovědi je stejné jako v případě dokumentu nebo informačního zdroje: tyto pojmy v praxi prostupují všemi obory teoretickými i aplikovanými, jakož i všemi oblastmi praktické činnosti. Sjednocení výkladu by tedy usnadnilo komunikaci inter- i transdisciplinární (a navíc i komunikaci strojů, protože sémantická interoperabilita je základní podmínkou realizace vize sémantického webu). Ale který z představitelů těch mnoha různých komunit, jež metadata vytvářejí, zpracovávají a využívají, by měl jejich obecnou definici vytvořit? Jsme přesvědčeni, že stejně jako v případě dokumentu a informačního zdroje to je jednoznačná úloha pro informační vědu.
Text článku je členěn do tří částí. V první části podáme přehled nejvýznamnějších stávajících definic metadat a s pomocí jejich kritického rozboru ukážeme, jaké aspekty metadat tyto definice vystihují. Druhá část je věnována podrobné charakteristice metadat, jež je vedena snahou o vícehlediskový přístup a má tudíž fasetovou strukturu. Třetí část se zaměřuje na významnou skupinu bibliografických metadat.
Vzhledem k limitovanému rozsahu danému formátem časopiseckého článku není v textu možné zabíhat do podrobností a praktických ukázek. Pokud by případný zájemce o detailnější a zejména konkrétnější pohled na metadata chtěl vybrat z dnes již nesmírně rozsáhlého korpusu literatury na toto téma jedinou publikaci, lze mu doporučit podrobné a v době psaní tohoto textu stále aktuální zpracování problematiky v monografii Metadata Marcii Zengové a Jian Quinové (2016).
1 Definice metadat
Zřejmě první užití termínu metadata v angličtině pochází z oblasti informatiky; je doloženo v Oxfordském slovníku angličtiny a datováno rokem 19683. Vyskytuje se ve zprávě počítačového odborníka Philipa R. Bagleyho, který formuluje následující charakteristiku datových prvků: „Stejně důležitá jako schopnost kombinovat datové prvky pro vytvoření kompozitního datového prvku je schopnost explicitně spojit datový prvek s druhým datovým prvkem, který představuje data ‚o‘ prvním datovém prvku. Tento druhý datový prvek můžeme označit jako ‚metadatový prvek‘ “ (Bagley, 1968, s. 26). Tato definice je předobrazem četných následných variací na formulaci „metadata jsou data o datech (v počítači)“. Jak ale ukáže rozbor definic v následujících částech, většina takto formulovaných vymezení metadat jsou v podstatě metonymií (celek je v nich zastoupen svou částí) a jejich autoři i uživatelé je intuitivně chápou v širším významu. Uměleckými prostředky takové širší pojetí metadat než jen „data o datech“ naznačuje stejnojmenný animovaný film, natočený v roce 1971.4 Datum jeho vytvoření svědčí mimo jiné o tom, že už v počátcích používání termínu bylo téma metadat aktuální i za hranicemi komunity informatiků.
V prvním oddílu této části poukážeme na zásadní problémy definování metadat: definice kruhem, příliš úzké a příliš široké definice. Část 1.2 je přehledem nejvýznamnějších aspektů, z jejichž perspektivy je možné uvažovat o metadatech. V závěrečném oddílu zformulujeme pracovní definici metadat pro účely tohoto článku.
1.1 Problémy definování metadat
1.1.1 Definice kruhem
Tvrzení, že metadata jsou data o datech, případně informace o informacích, mají nespornou výhodu ve své lapidárnosti. Problémem takových definic však je, že jsou to definice kruhem – předmět se pokouší vymezit pomocí jeho samého. Většina definic metadat, jež jsou založeny na této konstrukci, se proto snaží doplnit specifika té podmnožiny dat, kterou je možné prohlásit za metadata. Specifika, doplňovaná k základní rekurzívní konstrukci, však jsou většinou formulována extenzionálně výčtem a nikoli intenzionálně prostřednictvím podstatných vlastností. Výčet charakteristik se navíc liší v závislosti na konkrétní dílčí oblasti, pro niž je příslušná definice zformulována.
Typickým příkladem takového způsobu vymezení metadat jsou výklady termínu metadata v mezinárodních terminologických normách pro oblast informace a dokumentace a informačních technologií: norma ISO 5127 (2017) definuje metadata jako „data o jiných datech, dokumentech nebo záznamech, která popisují jejich obsah, kontext, strukturu, datový formát, provenienci a/nebo s nimi spojená práva“. V mezinárodní normě ISO/IEC 2382 (2015) jsou metadata definována jako „data o datech nebo o datových prvcích, s možností uvádět jejich popisy a údaje o vlastnictví, přístupových cestách, přístupových právech a volatilitě (nestálosti)“.
1.1.2 Příliš úzká definice metadat
Problém příliš úzkých definic je zřejmý – nepokrývají celý rozsah (extenzi) definovaného pojmu. V případě definic metadat se lze nejčastěji setkat s těmito typy omezení: omezení zahrnutých entit na data (v krajním případě dokonce pouze na data v počítači) a omezení funkcí metadat na popis nebo na charakteristiku obsahu.
Omezení zahrnutých entit na data
Omezení rozsahu uvažovaných entit na data se může týkat jak entit, které jsou považovány za metadata, tak entit, k nimž se metadata mohou vztahovat. Pojetí metadat zúžené na data uplatňuje významná sada mezinárodních norem ISO/IEC 11179 věnovaná registrům metadat, která výslovně uvádí, že se zaměřuje pouze na „data, která definují nebo popisují jiná data“ (ISO/IEC 11179-1, 2015, s. 9), nikoli na obecné pojetí metadat. Je nesporné, že v četných oblastech zpracování dat je takové vymezení dostačující. Názorným příkladem registru metadat, který je v souladu s normou ISO/IEC 11179, je Statistický metainformační systém5 Českého statistického úřadu, přesněji řečeno jeho část Ukazatele6, která zahrnuje přehled metadat doprovázejících tzv. statistické ukazatele, kvantitativně vyjadřující obsah statistikou sledovaných hromadných jevů. Na obrázku 1 je ukázka uživatelské prezentace metadat pro údaj o počtu knihovních jednotek v knihovnách Pardubického kraje v roce 2017.
Obr. 1 Ukázka statistických metadat
(Zdroj: Český statistický úřad, Veřejná databáze, Statistiky, Kultura, sport, tabulka Knihovny – územní srovnání, údaje za rok 2017 [cit. 2019-09-26])
Metadata a to, k čemu se vztahují, však nejsou jen data7, přinejmenším v tom smyslu, jak je chápe informační věda. Data jsou v informační vědě chápána jako údaj, který lze zpracovávat nebo komunikovat, aniž by se uvažoval jeho obsah. Data, která sdělují nějaký obsah a mají pro někoho smysl, jsou už považována za informaci. V pojetí informační vědy tedy metadata nepředstavují data, ale informaci, která je buď použitelná pro zpracování či komunikaci „dat“, nebo pro popis či vysvětlení jejich obsahu (a tím pro jejich transformaci na informaci). Entita, která obsahuje informaci a tvoří samostatnou jednotku z hlediska komunikace nebo zpracování, je označována jako informační zdroj. Významnou skupinu informačních zdrojů tvoří dokumenty, za něž jsou považovány ty informační zdroje, jež obsahují hmotně fixované informace a tvoří samostatnou jednotku z hlediska obsahu. Avšak právě informační zdroj, který prodělal pod vlivem nových komunikačních technologií v uplynulých desetiletích dramatické změny, čeká teprve na svoje důkladné prozkoumání. Je určitým paradoxem, že informační věda již má k dispozici referenční pojmový model metadat (viz část 3.4), ale nemá obdobný model „dat“, tj. model informačního zdroje.
Vzhledem k absenci obecně přijímané definice informačního zdroje se omezíme na předběžné úvahy. Domníváme se, že pro vymezení toho, co jsou metadata a k čemu se vztahují, je vhodné chápat informační zdroj nikoli jako objekt, ale jako predikát, tj. z perspektivy jeho vlastnosti či funkce „být informačním zdrojem“. Takové chápání umožní zahrnout do úvah kromě objektu či události, jež mohou sloužit jako zdroj informací (např. kniha, telefonní hovor), i další entitu (např. čtenář knihy, volaný účastník telefonního hovoru), vůči níž je funkce „být informačním zdrojem“ realizována. Funkce „být informačním zdrojem“ není s objektem spojena trvale – například určitá osoba může být pro určitý subjekt zdrojem informací, zatímco pro jiný nikoli. To platí i pro dokumenty – již klasickým příkladem to vystihla Susanne Brietová (1951, s. 7): živé zvíře není dokument, ale zvíře vystavené v zoo už podle ní dokumentem je. Obdobným způsobem lze přistoupit k vymezení metadat. Výše zmíněná norma ISO/IEC 11179 to vyjadřuje slovy, že „metadata jsou data a data se stanou metadaty, pokud jsou použita tímto způsobem. To se děje za zvláštních okolností, pro konkrétní účely a s určitými perspektivami, protože ne každá data jsou vždy metadata. Soubor okolností, účelů nebo perspektiv, pro které jsou některá data používána jako metadata, se nazývá kontext. Metadata jsou tedy data o datech v určitém kontextu“ (ISO/IEC 11179-1, 2015, s. 9).
Užitečný pohled na metadata nabízí Jeffrey Pomerantz, který považuje za metadata jakýkoli výrok o informačním zdroji 8. Taková specifikace se elegantně vyhýbá definici kruhem a stejně jako v případě výše uvedeného omezení na data zahrnuje bezesporu rozsáhlou podmnožinu metadat. Typickým příkladem jsou výroky typu „kniha X má autora Y“. Je ovšem zapotřebí upřesnit, že toto vymezení se týká jen určitého typu výroků, a to výroků deklarativních, jež mají formu oznamovací věty. Ostatní typy výroků – tázací, zvolací a příkazové (rozkazovací) nejsou jako metadata vnímány. Dalším problémem této definice je, že ji lze jen obtížně vztáhnout na rozsáhlejší texty plnící funkci metadat, například na abstrakty nebo recenze, neredukovatelné na jednotlivé výroky.
Omezení funkcí metadat na popis
Již bylo zmíněno, že v definicích metadat se obvykle vyskytuje omezený výčet jejich funkcí. Tou nejčastěji uváděnou funkcí je popis. Kupříkladu český archivní zákon definuje metadata jako „data popisující souvislosti, obsah a strukturu dokumentů a jejich správu v průběhu času“.9 Taková definice však platí jen pro (byť velmi významnou) podmnožinu popisných metadat. Jak bude ukázáno v části 2.1, popis informačního zdroje zdaleka není jediným účelem metadat. K rozšířenému pohledu na funkce metadat pomůže i lingvistický pohled na etymologii předpony meta-.
Ať už byl tvůrcem termínu metadata Philip R. Bagley nebo někdo jiný, měl rozhodně šťastnou ruku při volbě předpony meta-, která svou víceznačností umožňuje rozšiřovat původní význam, úzce svázaný s počítačovými technikami zpracování dat. Nejčastější interpretací významu předpony meta- v termínu metadata je „o“; v obdobném smyslu se v lingvistice pro jazyk popisující jazyk používá termín metajazyk. To je ovšem opět pohled omezující funkci metadat pouze na popis obsahu zdroje, nicméně na metadata lze aplikovat i další významy předpony meta-: „za“ (příklady z jiných oborů jsou metafyzika jako věda zkoumající to, co přesahuje fyzické objekty, nebo metastáza jako druhotné ložisko nádorových buněk), „nad“ (viz metavyhledávání jako vyhledávání nad větším počtem různých zdrojů, metasystém jako systém na vyšší logické úrovni než původní systém, metastudie jako studie analyzující nikoli primární data, ale již publikované údaje), „(společně) s“ (v tomto smyslu se předpona meta- používá v chemii k označení některých prvků sloučenin), změna (nejznámějšími termíny tohoto typu jsou metamorfóza – změna vzhledu a metafora – změna významu, resp. denotátu).
Metadata ve významu „za“ evokují přesah prostorový, časový, rozsahem i obsahem. Příkladem jsou metadata s doplňujícími informacemi, například interpretace, hodnocení, vysvětlení informačního zdroje.
Metadata ve významu „nad“ označují vyšší stupeň nebo vyšší úroveň či vrstvu. Kupříkladu v rámci analýzy diskurzu lze metadata uvažovat jako specifickou vrstvu diskurzu nad vlastní promluvou nebo textem, propojenou s ostatními analyzovanými komponentami synchronními i diachronními vztahy (blíže v části 1.2.3).
Metadata ve smyslu „společně s“ lze chápat jako významnou součást kontextu informačního zdroje. Někdy je tento rys vyjadřován i předponou para-. Kupříkladu v pedagogice jsou termínem paradata označovány údaje o používání zdrojů pro výuku (např. e-learningových kurzů) studenty. Někdy se tak označují i doprovodná metadata s informacemi o metodách a technikách získání dat pro daný průzkum.
Význam předpony meta- ve smyslu změna poukazuje na to, že metadata stejně jako informace jsou jak pasivním odrazem, tak aktivním činitelem ovlivňujícím vztah subjektu k informačnímu zdroji. Je známo, že pro návštěvníky muzejních expozic hrají často klíčovou roli při chápání významu exponátů jejich popisky. Obdobně různé popisy či hodnocení téhož zdroje mohou mít vliv na rozdílné hodnocení jejich relevance uživatelem.
1.1.3 Příliš široká definice metadat
Ve snaze dospět k obecné definici metadat zahrnují někteří autoři do rozsahu pojmu i další, ne-informační zdroje, případně pojem metadata aplikují na příbuzné fenomény, jejichž terminologická základna byla historicky ustavena ještě před počátkem používání termínu metadata.
První přístup obvykle ztotožňuje metadata s reprezentací, popisem, modelem čehokoli, nejen informačního zdroje. Tak někteří autoři za metadata pokládají například i údaje na etiketě prodávaných produktů či považují údaje na mapě za metadata o zemském povrchu. Typické v tomto směru je pojetí Jenn Rileyové, která v instruktážním materiálu americké národní organizace pro normy v oblasti informací NISO10 podává toto obšírné vymezení: „Zamyslete se nad tím, jak obchodníci ukládají informace o svých produktech a o svých zákaznících; zaměstnavatelé o svých zaměstnancích a jejich činnostech; organizace o událostech, které pořádají; výzkumné instituce o trendech a významných lidech v jejich oboru; knihovny, archivy a muzea o materiálech v jejich péči; vlády o svých občanech, svých spojencích a svých nepřátelích – to všechno jsou metadata.“ (Riley, 2017, s. 1)
Tento přístup založený na hypotéze, že cokoli se může stát informačním zdrojem, má určité racionální opodstatnění. Pokud uznáme informaci o počtu prodaných výtisků nebo o ceně knihy za metadata, proč nepřiznat status metadat i analogickým informacím o ne-informačních objektech, například o potravinách? Kupříkladu Amazon dnes prodává nejen informační zdroje, a tytéž typy shodně strukturovaných údajů o prodávaných produktech by měly být jednou považovány za metadata a podruhé nikoli? Ale přestože v praxi se s těmito entitami nakládá stejně a jsou často považovány za ekvivalentní, jsme toho názoru, že teoretická rovina vymezení metadat by se měla omezit na data, která se vztahují k informačním zdrojům.
Dalším důvodem k pokušení rozšířit pojetí metadat jsou příbuzné fenomény, které se s metadaty zcela nevylučují, ale částečně se s nimi překrývají, jak to schematicky naznačuje obrázek 2: popis, seznam, fakt, metatext a sekundární informace. V následujícím komentáři se pokusíme doložit, že pro metadata a dané pojmy skutečně platí stav naznačený na obrázku jako množinový průnik. Ve všech případech lze konstatovat, že kromě podmnožiny společných jevů zahrnuje každý z příslušné dvojice pojmů ještě další fenomény, jež nespadají do významového spektra druhého z nich.

Obr. 2 Kontext metadat
Metadata a/vs. popis
Výstižné vymezení popisu v rámci poetiky a estetiky, jež lze zobecnit i na popisy vyskytující se mimo tento kontext, popisem rozumí „záznam pozorování určitého objektu, výčet jeho vlastností a znaků“ 11. V souladu s omezením, k němuž jsme se přiklonili výše, však může být objektem popisovaným metadaty jen informační zdroj, tedy ne všechny popisy jsou metadata. Navíc, přestože významná část metadat má popisný charakter, nelze funkci metadat omezovat pouze na popis informačních zdrojů.
Metadata a/vs. seznam
Seznamy, nazývané v různých oblastech svého použití i registry, indexy, evidence nebo katalogy, zahrnují samozřejmě i seznamy metadat. Umberto Eco ve své knize Bludiště seznamů rozlišuje mezi seznamem praktickým a seznamem poetickým, přičemž označení „poetický“ používá pro seznam vytvářený s uměleckým záměrem. Praktické seznamy, mezi něž Eco zahrnuje i katalogy knihoven, charakterizuje následovně: mají referenční funkci, zahrnují reálné objekty a jsou neměnné (Eco, 2009, s. 113–129). Taková charakteristika je nesporně aplikovatelná i na metadata. Ovšem ani každý praktický seznam nemusí být tvořen metadaty, viz například registr silničních vozidel tvořený daty o vozidlech, obchodní rejstřík s daty o firmách, katalog pracovních pozic zahrnující popisy funkcí nebo evidence docházky zaměstnanců s údaji o osobách a čase, jenž tyto osoby strávily na pracovišti. Termín metadata lze tedy vztáhnout pouze na seznamy informačních zdrojů, například na seznam děl nedostupných na trhu, vedený Národní knihovnou ČR (https://www.nkp.cz/digitalni-knihovna/dalsi-odkazy/seznam-del-nedostupnych-na-trhu). V části 1.2.1 bude dále ukázáno, že metadata nemusejí nutně tvořit nějakou množinu, jak je tomu v případě seznamu, ale lze za ně považovat i samostatný prvek.
Metadata a/vs. fakta
Termínem fakt se označuje skutečnost, událost, jev či nevyvratitelný pravdivý poznatek, případně empirický údaj. Do této kategorie spadají také vědecké důkazy a znalosti. Určit, kde končí fakta/vědecké důkazy a kde začínají metadata, je opět problematické, míra překrývání je značná. Stejně jako v předchozích případech se domníváme, že o metadatech má smysl mluvit jen tehdy, pokud se daná fakta a vědecké důkazy týkají informačních zdrojů.
Metadata a/vs. metatext
Podle Petra Mareše (2017) se za metatext považují „znakové jevy, jejichž denotá tem není vnější skutečnost (ležící vně znaku), ale znakový jev sám“. Analogicky k již několikrát zmíněné definici metadat lze tedy metatext zkratkovitě definovat jako text o textu. V širším pojetí může jít o jakýkoli text odvozený z jiného textu, například konspekt, resumé, rejstřík, poznámkový aparát. Vzhledem ke značnému podílu textových informačních zdrojů lze konstatovat překrývání významu pojmů metadata a metatext, nicméně při bližším zkoumání opět vyvstanou jejich rozdíly. Zatímco účelem metatextu je být textem, účel metadat je vymezen komunikační nebo reprezentativní funkcí. A dále, přestože textové zdroje tvoří významnou součást informačních zdrojů, je zapotřebí připomenout i existenci zdrojů netextových (obrazy, audio, video, geodata ad.), pro něž se samozřejmě rovněž vytvářejí metadata.
Metadata a/vs. sekundární informace
Ztotožnění metadat se sekundárními informacemi bylo poměrně častým jevem v počátcích zavádění termínu do slovníku knihovníků. Opět se ovšem ukazuje, že rozsah pojmu sekundární informace je širší; například články ve Wikipedii, vycházející z již publikovaných zdrojů, jsou sekundární informace, ale nikoli metadata. Kromě významu, který se kryje s metadaty, zahrnují sekundární informace navíc i informace odvozené z primárních dat a informace získané z informačního zdroje, tj. v podstatě cokoli kromě empirických údajů.
1.2 Aspekty metadat
V této části podáme přehled nejdůležitějších hledisek, s nimiž se lze setkat v definicích metadat: hledisko struktury a funkce a dále hlediska jazyka a modelu.
Úvodem považujeme za potřebné poukázat na to, že „data“ a metadata jsou relativní pojmy. Tato relativita byla konstatována již v části 1.1. To, zda určitý objekt prohlásíme za informační zdroj nebo za metadata, vyplývá spíše z daného kontextu než z nějakých vnitřních vlastností příslušných objektů. Tenkou linii mezi daty a metadaty demonstrují například plnotextové indexové soubory: slovo, tj. „data“, se automaticky konvertuje na termín indexu, tj. na metadata. Rozdíl tkví zjevně nikoli v obsahu, ale v účelu, k němuž dané slovo slouží. Jedno a totéž slovo v textu jsou „data“, ale v indexovém souboru jsou to metadata.
Na obrázku 3 je znázorněn informační zdroj, konkrétně kniha, a pět s ním souvisejících metadatových objektů. Prvním metadatovým objektem je bibliografická citace dané knihy. Další dva objekty (dc:creator a dc:title, což jsou prvky metadatového schématu Dublin Core) určují typ dílčích údajů v bibliografické citaci jako jméno tvůrce a název knihy. Vzhledem k těmto objektům lze tedy bibliografickou citaci chápat jako informační zdroj. Metadatový prvek dc:title je doplněn definicí svého významu, vůči níž opět vystupuje v roli informačního zdroje, a totéž lze prohlásit o vztahu dvojice jména tvůrce Jana Zábrany a jeho identifikátoru ve virtuálním souboru autorit VIAF. Naznačeným úrovním a pojmům slovník metadat a metadatové schéma, uvedeným v obrázku 3, se budeme věnovat v částech 1.2.1 a 1.2.3.

Obr. 3 Relativita „dat“ a metadat
1.2.1 Metadata jako struktura
Strukturu tvoří množina prvků a jejich vzájemných vztahů. Pod tímto úhlem pohledu se na metadata pohlíží jako na objekt, který má svoji vnitřní strukturu a zároveň jako na prvek, který vstupuje do vztahů s jinými prvky komunikačního systému. Na tento rys metadat se zaměřuje Výbor pro katalogizaci Asociace amerických knihoven (ALA CC:DA), jenž ve zprávě z roku 2000 věnované metadatům zformuloval následující definici: „Metadata jsou strukturovaná, zakódovaná data, která popisují vlastnosti entit obsahujících informace, jež pomáhají při identifikaci, zjišťování, hodnocení a správě popsaných entit“ (ALCTS, 2012).
Metadata jako prvek s vlastní strukturou
Základní struktura metadatového prvku je velmi jednoduchá, tvoří ji dvojice složená z vlastnosti informačního zdroje a z její hodnoty. Vztah těchto dvou komponent je vztahem více–více, tj. jedna vlastnost, například jméno tvůrce, může mít více hodnot. Zároveň platí, že jedna hodnota může být přiřazena k více vlastnostem, například název města může být hodnotou místa narození tvůrce nebo místa vydání knihy.
Metadata jako vztah
Metadatové prvky vstupují do dvou základních typů vztahů. Prvním je vztah metadat a informačního zdroje, druhým typem jsou vzájemné vztahy metadatových prvků.
Vztah metadata–informační zdroj
Násobnost vztahu metadata–informační zdroj je typu více–více, tj. k jednomu informačnímu zdroji může existovat více metadatových prvků (např. bibliografická citace, abstrakt, název, datum a čas vytvoření, podmínky přístupu ad.) a jeden metadatový prvek (např. jméno tvůrce, název producenta) může souviset s více informačními zdroji.
Dále lze konstatovat, že tento vztah lze při určitém úhlu pohledu považovat za rekurzívní, protože i metadata splňují podmínky pro to, aby byla označována jako informační zdroj. V každém případě se ovšem jedná o vztah asymetrický, každá ze zúčastněných entit v něm hraje jinou roli. Například popisná metadata popisují informační zdroj, ale zdroj nemůže popisovat metadata – ta lze popsat jen dalšími metadaty. Z informačního zdroje lze buď manuálně nebo strojově (například automatickou indexací) odvodit či vytvořit metadata, ale naopak to není možné. Metadata lze použít pouze k odkazu na informační zdroj, nikoli k vytvoření jeho obsahu.
Vztah metadata–metadata
Prvním z významných typů vzájemných vztahů metadat je vztah agregace. Jednotlivé dvojice vlastností informačních zdrojů a jejich hodnot, tj. metadatové prvky, lze sdružovat do větších celků: tak v knihovnách jsou údaje týkající se popisované knihovní jednotky tradičně sdružovány do katalogizačních záznamů. Tyto záznamy se pak sdružují do dalších celků, kterými jsou katalogy. V různých aplikačních oblastech mohou mít metadatové agregáty různá označení, kromě katalogů se nejčastěji se mluví o souborech, kolekcích, bázích dat, datových sadách či registrech metadat. Jejich struktura může být lineární, relační, hierarchická nebo síťová.
Dalším významným typem je vztah metadat různé úrovně. Tento vztah je možné zaznamenat již v příkladu na obrázku 1. Statistický ukazatel počtu knihovních jednotek v knihovnách Pardubického kraje lze považovat za metadata, vztažená k této množině informačních zdrojů. Metadata v okně „Informace o hodnotě“ jsou potom vlastně meta-metadata. Tutéž úvahu lze provést nad obrázkem 3. Bibliografická citace je soubor metadatových údajů o knize. Informace o typu jednotlivých údajů (jméno tvůrce, název knihy) jsou meta-metadata. To samé platí pro identifikátor jména autora. Definice významu prvku dc:title jsou pak meta-meta-metadata, a tak by bylo možné pokračovat ad infinitum. Obvyklým přístupem většiny autorů však je, že na takové přesné rozlišení jednotlivých úrovní rezignují; předpony meta- se nekumulují a veškeré typy se označují jednotně jako metadata. Tento zjednodušující přístup ovšem může být někdy na překážku přesnosti. Pokud by si všechny dvojice typu vlastnost–hodnota měly být rovny, jak potom rozeznat, zda se v daném kontextu vztahují k informačnímu zdroji nebo k metadatům? Jak poznat, jestli metadata popisují bibliografický soupis nebo bibliografii bibliografií? Jak odlišit seznam prvků od seznamu seznamů? A dále, podle čeho poznat, zda daný metadatový prvek vyjadřuje hodnotu vlastnosti informačního zdroje nebo zda je součástí slovníku metadat nebo metadatového schématu? V následující části ukážeme, zda a jak se s tímto problémem dokážou vypořádat metadata v prostředí sémantického webu.
Struktura metadat v sémantickém webu
Na platformu sémantického webu se aktuálně přesouvají mnohé informační systémy z původních oblastí použití, vznikají ovšem i zcela nové systémy, obvykle demokratickým způsobem „zdola“, například Wikidata (https://www.wikidata.org/). Charakteristiky sémantického webu lze shrnout do následujících tří okruhů:
1) Obsahuje „chytrá data“ srozumitelná strojům, tj. to, co je v tradičních systémech umělé inteligence označováno jako systém reprezentace znalostí nebo znalostní báze. Znalostní bázi sémantického webu tvoří webové zdroje opatřené sémantickými metadaty. Na rozdíl od systémů umělé inteligence mohou zdroje v sémantickém webu obsahovat jak rigorózně formalizované znalosti, tak znalosti vyjádřené neformálně.
2) Strukturu tvoří propojená data, tj. data s jemnější granularitou (místo webu dokumentů se mluví o webu dat). Propojená otevřená data „zviditelňují“ obsah tzv. neviditelného či hlubokého webu, který je uložen v databázích. Znalosti na sémantickém webu jsou obsaženy v distribuovaných webových zdrojích a jejich typickou vlastností je diverzita.
3) V porovnání s tradičními informačními systémy vykazuje sémantický web významná specifika, jež lapidárně vyjadřují anglické zkratky OWA, AAA a NUNA (Allemang a Hendler, 2011, s. 13).
Princip OWA (z angl. open world assumption) označuje předpoklad otevřeného světa v tom smyslu, že výroky nezahrnuté v sémantickém webu nejsou považovány za nepravdivé, věci nezastoupené na webu nejsou považovány za neexistující. Univerzum poznání, reprezentované prostřednictvím webových zdrojů, je chápáno jako dynamicky se měnící. Mění se nejen suma dostupných znalostí (nové zdroje se objevují, stávající zdroje mizí), ale i vztahy mezi nimi. Žádné tvrzení se nepovažuje za definitivní.
Princip AAA (z angl. anyone can say anything about anything – kdokoli může říci cokoli o čemkoli) konstatuje, že jedna věc může být chápána a vyjádřena různými způsoby, tj. jedna věc může mít více významů. O stejném předmětu mohou být k dispozici různá tvrzení. Tato tvrzení nemusejí být navzájem konzistentní, ale nemusejí se ani vylučovat.
Princip NUNA (z angl. non-unique naming assumption – nepravdivost předpokladu jedinečných jmen) vychází z předpokladu nejednotného pojmenování a připouští, že jedna věc může mít více označení.
Výše uvedené charakteristiky platí stejnou měrou pro informační zdroje sémantického webu i pro metadata. Tim Berners-Lee definuje metadata na webu jako „počítači srozumitelné informace o webových zdrojích nebo jiných věcech“ (Berners-Lee, 1997). V současnosti jsou k dispozici dva způsoby, jak dostat metadata na (sémantický) web: 1) Fyzické začlenění metadat do informačního zdroje prostředky HTML, CSS, XML, RDFa nebo mikroformátů a 2) osamostatnění metadat pomocí výroků v jazyce RDF (W3C RDF Working Group, 2014). Druhý způsob se aktuálně jeví jako perspektivní, proto se mu budeme věnovat podrobněji.
Název Resource description framework, tj. rámec popisu zdrojů, sugeruje chápání RDF jako jazyka popisných metadat. V současné době se však RDF vymezuje šířeji jako jazyk pro reprezentaci znalostí v sémantickém webu. V konstrukci jazyka je patrná inspirace predikátovou logikou. Ve výrocích predikátové logiky se předmětům buď připisují nějaké vlastnosti, nebo se určují vztahy mezi nimi. Vlastnosti jsou vyjádřené jednomístnými predikáty, vztahy předmětů vyjadřují dvou a vícemístné predikáty.
Výroky jazyka RDF tvoří tři komponenty: subjekt (obdoba podmětu ve větě), predikát (obdoba větného přísudku) a objekt (obdoba předmětu ve větě). Výroky RDF jsou vždy binární a orientované a lze je stejně jako věty přirozeného jazyka sdružovat do větších celků. Analogií k textovým odstavcům, jež tvoří množina vět či k záznamům v databázi, sestávajícím z množiny polí, je v RDF síťová struktura grafu, tvořeného množinou trojic RDF. Uzly grafu RDF tvoří subjekty a objekty identifikované prostřednictvím URI a hrany grafu představují predikáty rovněž identifikované pomocí URI. Pokud je subjektem informační zdroj, je možné predikát použít k označení vlastnosti tohoto zdroje a objektem vyjádřit její hodnotu. Jazyk RDF je tedy přímo použitelný k „zakódování“ metadat do jazyka sémantického webu.
Tim Berners-Lee tvrdí, že tato základní struktura, založená na protokolu HTTP, identifikátorech URI a na výrocích RDF, je podstatou fraktální povahy sémantického webu. To znamená, že umožňuje neomezené opakování stejné struktury v libovolně škálovatelné síti. Stejná struktura výroků umožňuje jejich vzájemnou propojitelnost, aniž by bylo nutné vytvářet jednotnou globální ontologii neboli slovník. Navíc jednotlivé dílčí slovníky (stejně jako komunity jejich uživatelů) nemusejí být vzájemně disjunktní, ale mohou se překrývat (Berners-Lee a Kagal, 2008).
Další strukturou, která doplňuje základní syntaxi jazyka RDF, je struktura slovníků (v sémantickém webu jsou často nazývány ontologie), v nichž je specifikována sémantika prvků použitých v trojicích RDF. Pro tyto účely se používá jazyk RDF Schema, který umožňuje vytvořit pojmový model webových zdrojů obdobným způsobem, jako to umožňuje entitně-relační model pro záznamy v databázi. RDF Schema umožňuje každý predikát charakterizovat definičním oborem (angl. domain) a oborem hodnot (angl. range) v podobě tříd možných objektů a subjektů, jež predikát může propojovat. Komplexnější nástroje pro tvorbu ontologií poskytuje jazyk OWL (Web ontology language), který mj. umožňuje logické odvozování.
1.2.2 Metadata jako funkce
Jeden z nejčastějších pohledů na metadata směřuje k jejich funkci. Uplatňuje ho i Karen Coyleová, která se ve svém pojetí zaměřuje na metadata digitální, vytvářená a zpracovávaná pomocí softwarových aplikací. Prohlašuje o nich, že jsou konstruovaná (tj. jsou to artefakty uměle vytvořené člověkem nebo strojem), konstruktivní (jsou vytvořená za určitým cílem, s určitým záměrem) a „vykonatelná“ (angl. actionable), tj. už ne jenom strojem zpracovatelná, ale i strojem použitelná k vykonání nějaké úlohy směřující k uspokojení nějaké potřeby (Coyle, 2010, s. 6).
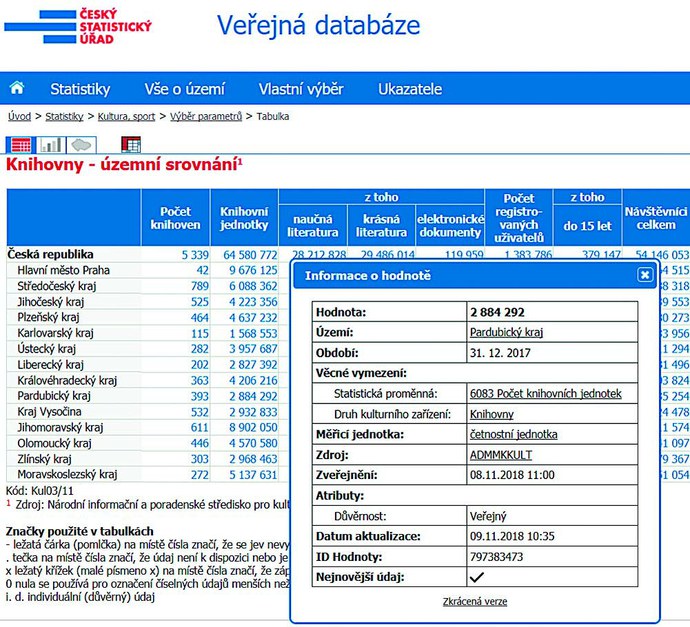
Často je funkční aspekt metadat použit jako základ jejich typologie. V rámci výkladu termínu metadata v TDKIV lze najít i pasáž vymezující funkce a typy metadat: „Funkce metadat je popisná, selekční a archivační. V souvislosti s těmito funkcemi se rozlišují metadata pro účely popisu, správy, právních nároků, technické funkčnosti, užití a archivace.“ 12 V tabulce 1 je uveden přehled funkčních typologií metadat, které zpracovali autoři významných monografií a příruček Priscilla Caplanová (2003, s. 3–5), Anne J. Gillilandová (2016), Jenn Rileyová (2017, s. 6), Jeffrey Pomerantz (2015, s. 17–18) a Richard Gartner (2016, s. 6–8). Jak je z obsahu tabulky patrné, přístupy jednotlivých autorů nejsou shodné, lze však pozorovat významné překrývání – všichni autoři ve svých výčtech uvádějí metadata popisná, administrativní, archivační a strukturální.
Poznámka: Někteří autoři svoji typologii ještě jemněji hierarchicky člení – to je v tabulce naznačeno zarovnáním značky x k pravému okraji (např. Priscilla Caplanová definuje hodnotící metadata jako typ popisných metadat).
Tab. 1 Funkce metadat
K problematice funkčnosti metadat se ještě vrátíme v části 2.1.
1.2.3 Metadata jako jazyk
Tento pohled na metadata, který lze označit jako sémanticko-lingvistický, chápe metadata jako promluvu nebo jako text. Z rozsáhlého aparátu lingvistiky se pro účely charakteristiky metadat jeví jako užitečná metoda analýzy diskurzu, protože uvažuje jazyk v kontextu dalších faktorů, tvořících komplex společenské komunikace informací. Podle Jiřího Nekvapila je diskurz „soubor jazykových (obecně: znakových) reprezentací nějaké ho aspektu světa, spojený s určitým věděním, charakteristický pro určitou společenskou skupinu či instituci, která kontrolovaným produkováním těchto (a ne jiných) reprezentací zároveň přispívá k produkování sebe sama“ (Nekvapil, Hoffmannová a Hajičová, 2017).
Během analýzy diskurzu lze uplatnit dvě různá kritéria členění, jež lingvistika označuje jako synchronní a diachronní. V synchronním „řezu“ se metadata uvádějí do kontextu s dalšími prvky diskurzu, které tvoří součást konkrétní výpovědi. Obvyklým způsobem je členění do úrovní nebo vrstev. V úvodu bylo uvedeno, že Jeffrey Pomerantz považuje metadata za infrastrukturu, tj. za spodní vrstvu, na jejímž základě probíhá společenská komunikace. Alternativním pohledem lze vidět metadata jako vrstvu nad textem či promluvou, tj. jako hyperstrukturu, tvořenou například hypertextovými odkazy, jež umožňují navigaci v síti webových zdrojů. Na nejnižší úrovni si lze z této perspektivy představit reálné objekty či události a nad nimi pak vrstvu promluvy či textu, tj. informačních zdrojů, jež o nich vypovídají. Následující vyšší vrstvu komunikace by pak tvořila metadata, sestávající z výpovědí vztahujících se k informačním zdrojům. V části 1.2.1 byla zmíněna potřebnost slovníků metadat, označovaných jako seznamy metadatových prvků, ontologie nebo systémy organizace znalostí. Tyto slovníky definují sémantiku metadat a lze si je představit jako samostatnou vrstvu nad metadaty. V současné době by již bylo možné obsadit i další vrstvu, kterou tvoří metadatová schémata a pojmové modely metadat (např. IFLA LRM).
Diachronní řez diskurzem umožňuje zaměřit se na proměny struktury a funkce metadat v čase. Lze sledovat jejich změny v různých časových obdobích, případně v různých fázích životního cyklu informačního zdroje.
Model chápeme jako účelově vytvářený artefakt, který je ve vztahu korespondence s jinou entitou, jež se obvykle nazývá originál. Modelový přístup je jednou z možností, jak pohlížet na komplikovaný fenomén informace. Informaci lze z tohoto úhlu pohledu chápat jako model (odraz, reprezentaci) reality. Protože informace je též součástí reality, může být i ona předmětem informačního modelování – výsledkem jsou potom metadata.
Pokusíme-li se aplikovat tyto obecné premisy na vztah metadat a informačních zdrojů, narazíme na určité potíže. Tvrzení, že metadata jsou modelem informačního zdroje, platí jen pro omezenou množinu popisných metadat. Tak lze obsahovou charakteristiku knihy považovat za její model, těžko už ale tuto roli přisoudit údajům o počtu prodaných výtisků nebo o jejím vlastníkovi či tvůrci. To, co metadata ve vztahu k informačnímu zdroji modelují, totiž není zdroj jako celek či některá z jeho částí, ale jeho vlastnosti, tj. atributy, funkce či vztahy.
V úvodu článku jsme metadata předběžně rozčlenili do dvou základních kategorií – deklarativních a procedurálních. Deklarativní metadata (například název nebo prostorový identifikátor) jsou modelem statickým a vyznačují se tím, že mohou kromě toho, že modelují vlastnost informačního zdroje, vystupovat i v roli reprezentace celého zdroje či jeho části. Procedurální metadata jsou modelem dynamickým, modelují operace s informačním zdrojem nebo s jeho částí. V obecném slova smyslu modelují komunikační funkce informačního zdroje. Takovou úlohu plní například datové typy položek v databázovém schématu, jež určují, jaké operace bude možné s hodnotou položky vykonávat (například matematické operace s číselnými typy, abecední řazení s texty) nebo metadata charakterizující možný způsob prezentace obsahu zdroje (například zobrazení textu nebo přehrání zvukového záznamu).
1.3 Pracovní definice metadat
Autorka jedné z prvních monografií o metadatech určené knihovníkům Priscilla Caplanová kategoricky prohlašuje, že jednoznačnou a obecně platnou definici metadat nelze vytvořit. „Mělo by být naprosto jasné, že neexistuje žádná správná nebo nesprávná interpretace metadat, ale že každý, kdo používá tento termín, si musí být vědom, že může být chápán odlišně v závislosti na komunitě a kontextu, ve kterém je používán.“ (Caplan, 2003, s. 2–3) Ve světle problémů naznačených v předchozích částech se takové konstatování jeví jako realistické. Ani my se tedy nebudeme pokoušet o všeobecně platnou definici a omezíme se na vlastní pracovní vymezení pojmu metadat, tak jak s ním budeme dále pracovat v textu tohoto článku.
V části 1.1.2 jsme zamítli zužující pojetí metadat jako dat o datech a přiklonili jsme se k názoru, že základní jednotkou metadat je informační zdroj. Rozšířené pojetí metadat přesahující rámec informačních zdrojů jsme rovněž navrhli odmítnout. V části 1.1.3 jsme ukázali, že pro informace či výroky o neinformačních entitách jsou k dispozici propracované teorie a ustálené pojmové soustavy s historickými kořeny a specializovanými komunitami, jež s nimi pracují.
Chápat metadata jako informační zdroj se vztahem k jinému informačnímu zdroji je však příliš široké vymezení, pak by totiž pojem musel zahrnout třeba i adaptace, pokračování, překlady nebo agregáty, jako jsou sborníky. Bude tedy ještě zapotřebí upřesnění. K tomu využijeme významnou souvislost metadat a modelu, konstatovanou v části 1.2.4, a pro účely tohoto článku přijmeme následující pracovní definici:
Metadata jsou informační zdroj se specifickým typem vztahu k jinému informačnímu zdroji. Specifika tohoto vztahu spadají do jedné z těchto kategorií: 1) metadata jako reprezentace vlastnosti informačního zdroje a 2) metadata jako nástroj komunikace informačního zdroje.
2 Typologie metadat
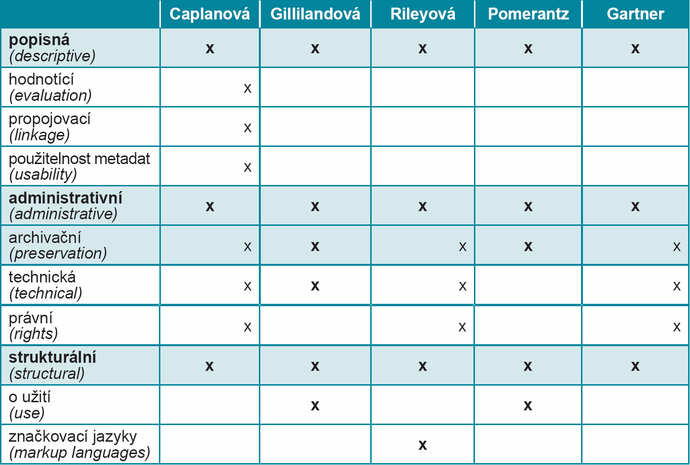
V této části se zaměříme na zevrubnou charakteristiku metadat prostřednictvím popisu jejich nejvýznamnějších typů. V části 1.2 jsme ukázali, že na metadata lze nahlížet z různých aspektů, a tuto vícehlediskovost uplatníme i v návrhu vlastní typologie, která má fasetový charakter. Přehled faset a jejich obsahu je shrnut v tabulce 2. Obsah jednotlivých faset je vzájemně kombinovatelný, takže umožňuje vytvořit poměrně detailní charakteristiku konkrétních instancí metadat s využitím šesti hlavních kritérií; počet možných charakteristik ještě zvyšuje skutečnost, že čtyři fasety jsou vnitřně členěny pomocí subfaset (v tabulce jsou vyznačeny špičatými závorkami).
Tab. 2 Fasetová typologie metadat
2.1 Funkčnost
Jak bylo demonstrováno v části 1.2.2, je kategorizace metadat odvozená z jejich funkčnosti používána mnoha autory. Jejím určitým problémem ovšem je, že funkčnost (účel, případ užití) metadat není statickou vlastností, ale může se dynamicky proměňovat v čase. To, za jakým účelem byla metadata navržena například v metadatovém schématu, nemusí být totožné s tím, za jakým účelem byla vytvořena a k jakému účelu jsou reálně využívána. Kupříkladu údaj o rozměru knihy může být využit k informování čtenáře, ale i k návrhu optimální výšky polic ve skladu. Dalším příkladem je druhotné využití popisných metadat či metadat o užití zdroje v bibliometrii a v citační analýze.
Níže se pokusíme vyjmenovat nejvýznamnější funkce metadat, jejich seznam však rozhodně neaspiruje na úplnost. Je pravděpodobné, že v každé konkrétní aplikační oblasti by bylo možné a potřebné doplnit další funkce a případy užití.
Identifikace
Primárním cílem identifikace je odlišení informačního zdroje od ostatních zdrojů, například pomocí URI nebo souřadnic GPS. Digitální identifikační metadata často patří do skupiny, kterou Karen Coyleová označuje jako „vykonatelná“. Jejich specifickou vlastností je tzv. rozklíčování (angl. resolving, resolution) dalších údajů souvisejících se zdrojem, čímž umožňují přístup k dalším metadatům nebo přímo přístup ke zdroji.
Popis
Cílem popisu je reprezentace informačního zdroje prostřednictvím charakteristiky jeho vlastností. Popis může sloužit jako náhrada (surogát) zdroje, případně jako náhrada znalosti existence nebo charakteristiky zdroje. Popis může zahrnovat i informace doplňující obsah zdroje.
Přístup ke zdroji
Metadata tohoto typu umožňují fyzický nebo intelektuální (kognitivní, sémantický) přístup ke zdroji. Typická přístupová metadata mají identifikační povahu a obsahují informace o umístění informačního zdroje nebo jeho označení.14 Dalším obsahem této kategorie metadat jsou informace o oprávněních a podmínkách přístupu ke zdroji.
Strukturování
Strukturní metadata slouží k označování částí informačního zdroje a k případnému určení jejich vztahů, kupříkladu definují podkapitolu jako část kapitoly. Strukturní metadata byla historicky prvním typem údajů označovaných jako metadata. Zásluhou oboru informatiky se strukturní metadata z původních jednoduchých datových slovníků vyvinula do podoby abstraktních datových modelů a schémat, použitelných i pro tvorbu pojmových modelů (entitně-relační modely, objektově orientované diagramy tříd v UML, hierarchicky strukturované modely v jazycích DTD a XML Schema, síťové modely v jazyce RDF Schema a ontologie v jazyce OWL).
Prezentace
Prezentační metadata jsou podobná metadatům strukturním. Obsahují informace o tom, jak prezentovat jednotlivé části informačního zdroje uživatelům (např. typ písma, umístění poznámkového aparátu), aby je bylo možné vnímat lidskými smysly. Typickým reprezentantem jsou výroky v jazyce CSS, popisující způsob vizuálního zobrazení webových zdrojů.
Hodnocení
Příklady metadat sloužících k hodnocení informačního zdroje jsou počet lajků, údaje o relevanci, spolehlivosti, aktuálnosti, důvěryhodnosti.
Správa
Metadata pro správu informačních zdrojů tvoří rozsáhlou skupinu, zahrnující např. údaje s pravidly pro uchování, autorská či průmyslová práva, obchodní údaje, údaje o užití zdroje.
Poznámka: Prakticky všechny výše uvedené případy užití se mohou vztahovat i na metadata. Běžným případem jsou metadata popisující jiná metadata, strukturní metadata o metadatech tvoří metadatová schémata. Dalšími příkladem meta-případu užití je správa metadat zahrnující jejich evidenci, dokumentaci, verzování, změny, rušení, definování vztahů metadat v rámci jednoho schématu i mezi schématy (mapování či propojování metadat).
2.2 Čas vytvoření nebo transformace
Jak ukázal již obsah fasety funkčnost, metadata jsou využívána během všech událostí v životním cyklu informačního zdroje (např. reprezentace znalostí / tvorba informačního zdroje / organizace / zpracování / uložení / přenos / vyhledávání / přístup / využití). Totéž lze konstatovat o událostech, během nichž jsou metadata vytvořena nebo trans formována. V této souvislosti je vhodné připomenout, že čas vytvoření či transformace metadat nemusí být shodný s časem, kdy byl vytvořen či transformován informační zdroj. Metadata lze vytvářet dokonce ještě před vznikem samotného informačního zdroje; příkladem jsou abstrakty příspěvků, navrhovaných k přednesení na konferenci. Stejně tak je možné tvorbu či úpravy metadat realizovat i poté, co už zdroj přestal existovat.
2.3 Závislost na informačním zdroji
Lze rozlišit dva typy závislosti metadat na informačním zdroji – obsahovou a fyzickou. V obou případech se pak metadata člení na závislá a nezávislá.
Obsahově (sémanticky) závislá metadata existují jako nesamostatný zdroj, který dává smysl pouze se zdrojem, k němuž se metadata vztahují. Typickým příkladem jsou značkovací jazyky, například HTML. Metadata obsahově nezávislá jsou využitelná jako samostatný informační zdroj. Příkladem je využití abstraktů v bibliografických databázích pro posouzení relevance zdroje.
Fyzicky (syntakticky) závislá metadata jsou fyzicky začleněná do zdroje (například značkovací jazyky, tiráž, ex libris). Fyzicky nezávislá metadata představují samostatnou jednotku přičleněnou ke zdroji nebo odkazující na zdroj (například katalogizační záznam, bibliografická citace, URL, termín tezauru, třídník MDT).
2.4 Způsob vytvoření
Z hlediska způsobu tvorby metadat se nabízejí dvě vzájemně kombinovatelná hlediska. Podle typu agenta lze rozlišit metadata vytvářená manuálně a strojově či automaticky. Další kritérium rozlišuje nově vytvářená metadata (angl. from scratch) a metadata opětovně použitá jiným uživatelem nebo pro jiný účel. Kombinací těchto dvou hledisek pak lze vytvořit kupříkladu kategorii manuálně nově tvořených metadat (například tzv. originální katalogizace v knihovnách) a kategorii automaticky tvořených nových metadat (například pro fotografie pořízené digitálními fotoaparáty). Příkladem manuálního opětovného použití již existujících metadat je sdílená katalogizace v knihovnách, automatizované opětovné použití metadat probíhá během tzv. sklízení metadat (angl. metadata harvesting) pro účely jejich archivace.
2.5 Agenti
V rámci fasety Agenti jsou opět použita dvě kritéria členění. Podle role, kterou zastávají při interakci s metadaty, lze rozlišovat tvůrce, správce, zpracovatele a uživatele, přičemž tyto role se mohou libovolně překrývat nebo kumulovat. Další způsob člení metadata podle typu agentů, již s nimi vstupují do interakce, na lidské a strojové. Skupinu osob lze ještě členit na profesionály a laiky. V éře tištěných dokumentů byla tvorba metadat typicky vyhrazena profesionálům a laici byli jejich uživateli. Vlivem dostupných nástrojů pro tvorbu metadat například na sociálních sítích se zejména od nástupu éry tzv. webu 2.0 laici stále aktivněji zapojují i do procesů tvorby metadat.
Požadavky lidských a strojových agentů na metadata se liší. Lidé očekávají kromě relevance, kvality a důvěryhodnosti především uživatelský komfort. Předpokladem pro efektivní interakci strojů s metadaty v současném heterogenním prostředí webu je syntaktická i sémantická interoperabilita, podmíněná formalizací jejich struktury i obsahu. Technologie sémantického webu nabízejí pro dosažení těchto cílů nástroje v podobě propojených otevřených dat a propojených slovníků či ontologií.
Rozdílné požadavky lidských a strojových uživatelů na metadata se projevují i v jejich rozdílném vzhledu a uspořádání, jak názorně ukazuje obrázek 4. Příklad 1 je ukázkou laicky vytvářených metadat v online portálu Databáze knih (https://www.databazeknih.cz/) v uživatelském rozhraní určeném lidem. Příklady 2 a 3 ukazují metadata pro tentýž zdroj, vytvořená profesionály a určená pro strojové zpracování. Příklad 2 zobrazuje metadata ve formátu MARC21, převzatá z online katalogu Národní knihovny ČR, a příklad 3 obsahuje metadata ve formátu RDF, dostupná v experimentální aplikaci OCLC WorldCat Linked data explorer (https://www.worldcat.org/).


Obr. 4 Metadata určená lidem a metadata pro stroje
2.6 Granularita
Termín granularita se používá k vyjádření velikosti jednotky, jež je předmětem zájmu. Tento pohled lze uplatnit jak na metadata, tak na informační zdroje, k nimž se metadata vztahují.
Již bylo uvedeno, že minimální jednotkou metadat je trojice zdroj – atribut – hodnota v podobě výroku přirozeného nebo formalizovaného jazyka. Další jednotkou je záznam, tj. množina metadatových výroků vztahujících se k jednomu zdroji. V různých aplikačních oblastech se pro záznamy používají různá označení, například bibliografický popis, katalogizační záznam, metadatový záznam, metadatový popis, profil uživatele, soubor popisných prvků (angl. description set). Množina metadat vztahujících se k více různým informačním zdrojům se dnes nejčastěji označuje jako kolekce nebo datová sada, tradičně se označovala jako katalog, bibliografie nebo index. Specifickým termínem znalostní báze se označují metadata o kolekcích elektronických zdrojů nabízených knihovnami uživatelům (např. http://pez.cuni.cz/).
Škálu granularity informačních zdrojů zahajují na nejjemnější úrovni jejich části, nazývané obvykle prvky či elementy, jimiž mohou být třeba v případě jazykových korpusů i jednotlivé slovní tvary v textu. Následuje úroveň celého zdroje a konečně stejně jako v případě metadat kolekce, sbírky, fondy, databáze a datové sady zahrnující množiny zdrojů.
3 Bibliografická metadata
Cílem této části je začlenit bibliografická metadata15 produkovaná knihovnami do kontextu ostatních typů metadat včetně bibliografických metadat vytvářených jinými tvůrci, než jsou knihovny. Úvodem lze konstatovat, že ne všechna metadata produkovaná knihovnami jsou bibliografická metadata a ne všechna bibliografická metadata jsou produkovaná knihovnami. V době před nástupem internetu se historicky vyprofilovaly dvě hlavní skupiny bibliografických metadat: 1) metadata pro přístup k informačním zdrojům a pro jejich využití, vytvářená knihovnami a dalšími fondovými a paměťovými institucemi, a 2) metadata pro obchod s informačními zdroji, vytvářená jejich producenty, vydavateli a obchodníky. Specifickou podskupinou jsou bibliografická metadata ve funkci obchodní komodity. Jejich tvůrci jsou producenti placených katalogizačních a rešeršních služeb, referátových časopisů a magnetopáskových a online databází s bibliografickými údaji.
Obvyklé intuitivní rozlišení bibliografických a nebibliografických metadat se zaměřuje na první z výše uvedených skupin metadat a vychází z určení jejich tvůrců, případně správců informačních zdrojů, pro něž jsou metadata vytvářena. Pokud jsou takovými správci zdrojů nebo tvůrci metadat knihovny nebo v poněkud širším pohledu paměťové a fondové instituce, jsou dotyčná metadata považována za bibliografická. Jejich tvůrci jsou pak označováni jako katalogizátoři a bibliografové, nově se objevuje profesní označení „metadatový knihovník“ (angl. metadata librarian). Takový pragmatický přístup sice může stačit pro potřeby každodenní praxe, postrádá však teoretickou bázi. Proto se v následujícím textu pokusíme o teoretický přístup k vymezení bibliografických metadat. K tomu využijeme pojmy bibliografická kontrola, bibliografická entita a bibliografické univerzum v pojetí Patricka Wilsona a Elaine Svenoniové a propojíme je s pojmovým aparátem modelu IFLA LRM.
3.1 Bibliografická kontrola
Bibliografická kontrola je obecný souhrnný pojem, zastřešující veškeré dílčí funkce bibliografických metadat. V TDKIV je definována poměrně široce jako „proces tvorby, výměny, uchování a využití dat o informačních zdrojích“.16 Pracovní skupina Kongresové knihovny pro budoucnost bibliografické kontroly ji vymezuje jako „organizaci knihovních materiálů pro usnadnění objevování, správy, identifikace a přístupu“ (Library of Congress, 2008, s. 6).
Patrick Wilson v rozsáhlé eseji věnované bibliografické kontrole interpretuje význam anglického control ve smyslu řízení a ovládání a zaměřuje se na účel, k němuž „ovládání“ informačních zdrojů slouží. Poukazuje na to, že účelem bibliografické kontroly není pouhá evidence či katalogizace zdrojů (abychom věděli), ale především tvorba nástrojů (abychom mohli), jež pomohou vybrat z existujících zdrojů ty hodnotné a relevantní. „Objevování hodnotného v množství většinou bezcenného a nezajímavého je hlavní složkou problému bibliografické kontroly“ (Wilson, 1968, s. 1). Pro hodnocení systému bibliografické kontroly nabízí Wilson několik dimenzí: počet uživatelů, jimž slouží, spolehlivost, rozsah zdrojů, rozsah různých požadavků na zdroje, možnosti přístupu ke zdrojům, čas odezvy, snadnost použití.
Procesy bibliografické kontroly člení Wilson do dvou typů, jež jsou zhruba analogické k obecnému členění metadat na deklarativní a procedurální (viz část 1.2.2) – popisování a využívání. Proces popisování odpovídá deklarativním metadatům, proces využívání metadatům procedurálním. Zatímco popisování vidí Wilson jako víceméně neutrální shrnutí rysů informačního zdroje (i v tomto případě ovšem doprovázené procesy výběru, protože ne všechna fakta vztahující se ke zdrojům jsou podle něj bibliografická fakta), proces využívání zahrnuje hodnocení a posouzení relevance zdroje vzhledem k jeho předpokládanému využití. K funkčnímu pohledu Wilson doplňuje ještě pohled strukturální. „To, co my vidíme jako problémy kontroly, jiní viděli jako problémy organizace. Lze říci, že organizace je strukturální pojem, zatímco kontrola je funkční pojem; organizace je něco, co věci mají nebo je jim dáno, kontrola je něco, co máme nebo čím věci ovládáme.“ (Wilson, 1968, s. 3) Cílem bibliografické kontroly je tedy organizace informačních zdrojů a zajištění přístupu k nim, umožňující jejich využití. Prostředkem k dosažení tohoto cíle jsou bibliografická metadata.
Tvorba bibliografických metadat v knihovnách se vyznačuje určitými specifiky. Typickým případem je, že zdroj, pro který jsou vytvářena metadata, už nějakou množinu metadat obsahuje. Tak většina publikovaných knih kromě svého textu obsahuje i údaje o názvu, o svých tvůrcích, identifikátor ISBN, údaje o datu a místě vydání a další. Tato metadata jsou pak beze změny nebo s drobnými úpravami danými pravidly (např. invertovaný tvar jména) kopírována a jsou z nich vytvářeny údaje, začleňované do knihovních katalogů. Z pohledu fasety, kterou jsme v části 2.4 nazvali Způsob vytvoření, se tedy jedná o opětovné použití metadat jiným uživatelem. V modelu IFLA LRM a v pravidlech RDA je pro tento účel definován atribut nazvaný údaj o provedení (angl. manifestation statement). Tento atribut je definován jako kontejner zahrnující veškeré údaje, „které se vyskytují v exemplářích provedení a jsou považovány za významné pro to, aby uživatelé pochopili, jak zdroj představuje (popisuje) sám sebe“ (IFLA, 2017b, s. 49–50). Takový postup ale nelze uplatnit vždy, protože metadata, jež má mít zdroj v sobě „napsána“, mohou chybět nebo být nesprávná. Pro tvůrčí přístup k tvorbě bibliografických metadat, spojený s výzkumnými metodami, se vžil název bibliografická heuristika. V TDKIV je definován jako „metodika zjišťování a ověřování bibliografických informací, korekce chybných a doplňování chybějících bibliografických údajů s využitím vhodné strategie, resp. logických operací a algoritmů“ 17.
3.2 Bibliografická entita a bibliografické univerzum
Pro teoretické vymezení bibliografických metadat je třeba stejně jako v případě obecné definice metadat jasně stanovit, k čemu se tato metadata vztahují. Elaine Svenoniová používá pro tento typ informačního zdroje název bibliografická entita18 a množinu všech bibliografických entit pak nazývá bibliografické univerzum. Jejich vymezení nastínila na semináři věnovaném bibliografickým záznamům, který pořádala IFLA v roce 1990 ve Stockholmu. Elaine Svenoniová zde vystoupila se zásadním příspěvkem, v jehož textu lze spatřovat základní koncepty budoucí studie o funkčních požadavcích na bibliografické záznamy (FRBR) a její aktuální verze v podobě referenčního pojmového modelu IFLA LRM. Vzhledem k tomu, že příspěvek byl přednesen v roce 1990, je celkem pochopitelné, že Svenoniová nepoužívá termín bibliografická metadata, ale bibliografické záznamy. Je ovšem zjevné, že tyto termíny jsou obsahově ekvivalentní. Na bibliografickou entitu popisovanou bibliografickým záznamem pak Svenoniová pohlíží ze tří úhlů pohledu jako na dílo, jeho vydání a na jednotlivý exemplář. V aktuálním pohledu založeném na modelu IFLA LRM lze toto pojetí bibliografické entity vymezit pomocí čtveřice vzájemně propojených entit dílo, vyjádření, provedení a jednotka. Elaine Svenoniová nazývá metadata popisující bibliografické entity „popisnými prvky“. Pro údaje v bibliografickém záznamu, jež popisují vztahy mezi bibliografickými entitami a vztahy k nebibliografickým entitám (například k osobám či institucím odpovědným za obsah díla), používá termín „organizační prvky“. Ty podle ní slouží ke strukturování bibliografického univerza (Svenonius, 1992, s. 7–8).
Patrick Wilson volí k vymezení bibliografického univerza obrazný personifikující přístup, který umožňuje vystihnout jeho dynamiku a složitost. Prvky bibliografického univerza nazývá jeho „obyvateli“ a vzájemné vztahy bibliografických entit přirovnává k neustále se vyvíjejícím složitým vztahům v rodině a obecně v lidském společenství. „Vytvořit dílo neznamená vyjmenovat všechny členy jeho rodiny, ale je to spíše založení rodiny, vytvoření jednoho nebo více textů, které se stanou předky pro další členy rodiny.“ (Wilson, 1968, s. 9) K ovládnutí obyvatel bibliografického univerza se pak podle Wilsona užívají nástroje bibliografické kontroly.
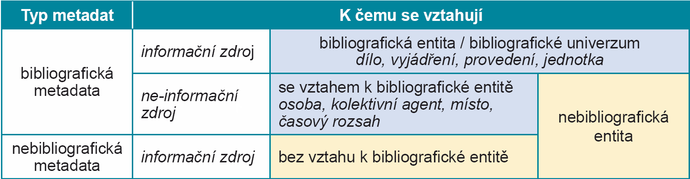
Bibliografická metadata tedy vymezíme jako metadata vztahující se k bibliografickým entitám (tj. dílo, vyjádření, provedení a jednotka) a k části nebibliografických entit s přímým vztahem k bibliografickým entitám.19 Rozsah takových nebibliografických entit opět vymezíme pomocí entit v modelu IFLA LRM: osoba – autor, uživatel atd.; kolektivní agent – vydavatel, zpracovatel atd.; místo – vydání, vytvoření, místa se vztahem k obsahu atd.; časový rozsah – vzniku, využití, transformace atd. V tabulce 3 je barevně odlišena ta podmnožina entit, k níž se vztahují bibliografická metadata.
Tab. 3 Bibliografická a nebibliografická metadata
3.3 Typologie bibliografických metadat
Z funkčního hlediska se obvykle za bibliografická metadata považují metadata identifikační, popisná a přístupová. V dokumentu IFLA LRM se výslovně uvádí, že model nezahrnuje administrativní metadata, tj. metadata umožňující správu informačních zdrojů. Ze strukturního hlediska lze bibliografická metadata členit na tři typy: formální, obsahová a kontextová.
Formální metadata zachycují vnitřní vlastnosti informačních zdrojů a v tradičním prostředí tištěných dokumentů popisují vlastnosti hmotného nosiče dokumentu. Někdy se označují jako popisná nebo identifikační, protože jejich hlavním cílem je odlišit daný informační zdroj od ostatních.
Obsahová metadata se vztahují k obsahové složce dokumentu. Jejich cílem je seskupit informační zdroje nebo jejich části s ekvivalentním obsahem. Typickými příklady jsou věcné rejstříky publikací nebo obsahové (věcné) údaje v katalozích a v bibliografických databázích. Tento typ metadat zahrnuje komplikovanou problematiku obsahové analýzy a označování obsahu informačních zdrojů (aboutness), pro niž nabízejí různí autoři různá řešení a podle svých přístupů se pak přiklánějí buď k tomu, že obsah je vnitřní charakteristikou (atributem) informačního zdroje, nebo že je zdroji přiřazen zvnějšku, arbitrárně. Obvyklou pomůckou pro jednotné vyjádření obsahových metadat jsou systémy organizace znalostí.
Kontextová metadata jsou vyjádřením formální nebo obsahové charakteristiky jiné entity, než je informační zdroj, k němuž se metadata vztahují. To může být buď jiná bibliografická entita (například románová předloha filmu) nebo libovolná nebibliografická entita (například osoba tvůrce nebo událost popisovaná v knize). Kontextová metadata jsou tedy vyjádřením vztahu a stejně jako metadata obsahová jsou použitelná k seskupování informačních zdrojů, například k vytvoření seznamu knih vydaných v určitém nakladatelství. Jejich další úlohou je navigace. Navigační systém umožňuje pohyb po předem stanovené dráze a má přinášet odpovědi na otázky: Kde jsem? Kam se odtud mohu dostat? Kudy se odtud dostanu tam, kde chci být? Kudy se vrátím tam, kde jsem byl (odkud jsem přišel)? Navigace je úlohou map, kontextová metadata lze tedy obrazně přirovnat k údajům na mapě bibliografického univerza. Nástrojem navigace jsou odkazy, v tradiční terminologii knihovních katalogů nazývané záhlaví, nyní označované jako přístupové body nebo selekční údaje.
Názornou ukázkou bibliografických metadat na obrázku 5 jsou záznamy v několika formátech, převzaté z katalogu Národní knihovny ČR, vytvořené pro čtyři vydání románu Vražda pro štěstí. Formální metadata jsou v polích MARC21 zvýrazněna tyrkysovou barvou, obsahová metadata žlutě a zelená barva zvýrazňuje kontextová metadata.




Obr. 5 Bibliografická metadata (Zdroj dat: Národní knihovna ČR, NKC – Online katalog NK ČR [cit. 2019-09-26])
3.4 Referenční pojmový model bibliografických metadat IFLA LRM
Již jsme konstatovali, že knihovny dnes disponují kvalitním referenčním pojmovým modelem bibliografických metadat IFLA LRM (IFLA, 2017b), který definuje jejich architekturu odvozenou z uživatelských potřeb. Potřeby uživatelů jsou formulovány v podobě úloh nalezení, určení, výběru, získání a objevování zdrojů. V rámci modelu je definováno 11 hierarchicky propojených entit. Na nejvyšší úrovni hierarchie se nachází entita res (z lat. označení pro věc), která zahrnuje všechny entity v rámci univerza diskurzu. Entita nomen (z lat. označení pro jméno) slouží k pojmenování či označení entit. Bibliografické entity reprezentuje ústřední čtveřice entit dílo, vyjádření, provedení a jednotka, podle svých anglických názvů označovaná iniciálovou zkratkou WEMI. Další entity, jež jsou předmětem popisu v bibliografických metadatech, představují entity agent s podtřídami osoba a kolektivní agent, místo a časový rozsah. V rámci IFLA LRM jsou tedy do jednoho modelu sjednoceny pojmy reprezentované v tzv. bibliografických datech i v tzv. autoritních datech. Tento referenční model by knihovny měly ve vlastním zájmu implementovat do bibliografických formátů a do datových modelů online knihovních katalogů.
Příklady na obrázku 5 lze využít i pro demonstraci toho, jakým přínosem se může stát aplikace referenčního pojmového modelu bibliografických metadat IFLA LRM do nových pravidel popisu RDA (Resource description and access). V pravidlech RDA se klade důraz na vyjádření vztahů, a to jak mezi popisnými prvky bibliografických entit navzájem (například vztahy dílo–vyjádření nebo vzájemné vztahy děl zahrnutých v agregovaném díle), tak vztahů propojujících bibliografické entity s popisy nebibliografických entit (například osoba agregátora) využívanými jako selekční údaje. Pravidla RDA jsou v knihovnách ČR uplatňována od roku 2015 pro nově vytvářené nebo modifikované záznamy, metadata v záznamech na obrázku 5 jsou ovšem z předchozích let, vytvořená bez aplikace modelu IFLA LRM a s omezenou mírou propojení dat.
Aniž bychom zabíhali do podrobností, připomeneme pouze, že obsahové údaje o zdroji i kontextové údaje o tvůrcích obsahu jsou v modelu IFLA LRM atributem entity dílo. Podle předchozích pravidel popisu byly tyto údaje zapisovány pro každé provedení. Je patrné, že taková praxe vede k nekonzistencím. V údajích o čtyřech různých vydáních stejného díla můžeme v polích s kódem 080 vidět různé třídníky Mezinárodního desetinného třídění (MDT), jež určitě nebyly diktovány změnou obsahu v jednotlivých vydáních, ale rozdílným subjektivním přístupem katalogizátorů. Nekonzistence možná poněkud překvapivě panuje i v údajích o autorství. V tomto případě ji způsobila objektivní příčina, již vysvětluje Josef Škvorecký20. Dílo vzniklo jako text dvou spoluautorů, z důvodů vynucených tehdejší politickou situací však v prvních třech vydáních bylo uvedeno jméno jen jednoho z nich – Jana Zábrany. V době čtvrtého vydání knihy byla tato skutečnost již známa a s uplatněním metod bibliografické heuristiky byla zachycena v metadatech tohoto provedení. V údajích o předchozích vydáních, pro něž tento fakt platí rovněž, však již změny provedeny nebyly. Pokud by v katalogizační politice Národní knihovny ČR byl už v té době uplatněn model IFLA LRM, stačilo by transformaci metadat na základě nově zjištěných skutečností provést pouze jednou do popisu díla, a aktualizované údaje by se uživatelům zobrazovaly u všech vydání. To je bezesporu efektivnější z hlediska vynaloženého času a samozřejmě i z hlediska kvality metadat.
Je nesporné, že implementace referenčního modelu IFLA LRM do konkrétního prostředí není jednoduchá. Model není určen k přímé implementaci v informačních systémech ve funkci datového modelu, ale představuje pojmovou základnu pro další specifické modely a normativní dokumenty, které je nutno vytvořit. Rovněž analýza popisovaných exemplářů podle modelu je intelektuálně obtížná, vyžaduje rozlišovat obsah od formy na různých úrovních abstrakce. Důraz na vyjádření vztahů jak mezi bibliografickými entitami, tak směrem k nebibliografickým entitám v jejich kontextu předpokládá další intenzivní a časově náročnou práci při budování souborů autorit. Jak ukazuje výše uvedený příklad, v mnoha případech popisu je zapotřebí uplatnit i bibliografickou heuristiku. Realizace představy, že by tyto intelektuálně náročné procesy bylo v dohledné době možné vykonávat strojově21, se jeví jako málo pravděpodobná, ne-li nemožná. Jsme nicméně toho názoru, že tvorba kvalitních bibliografických metadat je jedinou spolehlivou cestou směřující k naplnění úlohy paměťových a fondových institucí, jíž je zpřístupnění informačních zdrojů a uchování kulturního dědictví.
3.5 Propojená bibliografická (meta)data a sémantický web
Důvod pro transformaci bibliografických metadat z uzavřených proprietárních systémů, jež jsou dnes někdy hanlivě označovány jako datová sila, do otevřeného prostředí sémantického webu ve formě propojených bibliografických dat, resp. knihovních propojených dat, je jednoduchý: uživatelé opustili knihovní katalogy a přesunuli se na web. A protože návrat uživatelů k datům v katalozích není pravděpodobný, musí data „jít“ za uživateli na web.
Lze konstatovat, že knihovny přijaly koncept sémantického webu za svůj. Jejich ústřední organizace a četné výzkumné skupiny již zpracovaly návrhy a koncepce, směřující k transformaci dat z lineárních struktur formátu MARC do síťové struktury propojených otevřených dat. Koncepci transformace metadat produkovaných knihovnami pro prostředí sémantického webu publikovala pracovní skupina pro propojená data zřízená konsorciem W3C již v roce 2011 (Baker et al., 2011). V témže roce byly publikovány výsledky výzkumu Ronalda J. Murraye a Barbary B. Tillettové, kteří popsali změněné paradigma popisu zdrojů kulturního dědictví založené na teorii grafů (Murray a Tillett, 2011). Dynamiku vývoje v této oblasti výstižně ilustruje historie publikování pokynů IFLA s příklady dobré praxe pro národní bibliografické agentury v digitálním věku. V roce 2009 byla vydána tištěná publikace (Žumer, 2009) a okamžitě započaly přípravy nové verze. Ta už ale nevychází v tištěné podobě, ale má formát průběžně aktualizovaného webového zdroje (IFLA, 2017a).
Referenční pojmový model IFLA LRM byl již implementován do datového modelu pravidel RDA, jejichž popisné prvky mají definovány své identifikátory URI (například popisnému prvku „aggregator person of“, tj. osoba agregátora, byl přidělen identifikátor http://rdaregistry.info/Elements/a/P50528) a jsou tak připraveny pro tvorbu výroků v jazyce RDF, umožňujících tvorbu propojených bibliografických dat. Průzkum OCLC z roku 2018 provedený v 81 významných světových knihovnách, muzeích a vědeckých institucích ukázal, že tyto instituce realizují 104 projekty zaměřené na propojená data. Velikost jimi produkovaných datových sad obvykle přesahuje 1 milion trojic RDF, Europeana odhaduje množství svých dat na 5 miliard trojic, OCLC uvádí 108 miliard.22
Kromě bibliografických dat jsou již do sémantického webu začleněny i četné systémy organizace znalostí. Nejrozsáhlejším úložištěm systémů organizace znalostí ve formátu propojených dat, resp. propojených otevřených slovníků (LOV, linked open vocabularies), je repozitář Linked open vocabularies (https://lov.linkeddata.es/), v němž bylo k datu 25. 9. 2019 uloženo 682 slovníků metadat a metadatových schémat ve formátu propojených otevřených dat.
V průběhu výzkumných prací i ověřovacích projektů propojených bibliografických dat byly samozřejmě zaznamenány i četné problémy.
Martha Yeeová se domnívá, že aktuální struktura bibliografických metadat, jejíž základy se formovaly v době manuálního zpracování, je v některých ohledech příliš komplikovaná a její sémantika není plně „přeložitelná“ do jednoduchých struktur jazyka RDF. (Yee, 2009) To je i případ jazyka SKOS, umožňujícího převést do struktury propojených otevřených dat systémy organizace znalostí pomocí jejich reprezentace v RDF. Zatímco četné systémy s jednoduchou strukturou již jsou začleněny do sémantického webu, komplexní systémy jako je Deweyho desetinné třídění a Mezinárodní desetinné třídění zatím ve webu propojených dat chybí.
Thomas Baker se spoluautory se kriticky vyjadřují i k možnostem implementovat do sémantického webu pojmové modely bibliografických metadat FRBR, RDA a BIBFRAME, jejichž strukturu tvoří více entit (Baker, Coyle a Petiya, 2014).
Ukazuje se, že v mnoha případech musí být pro současný sémantický web bibliografická metadata zjednodušena. Tím se ovšem ztratí některé informace, jež byly zaznamenávány v tradičních katalozích. Na druhou stranu se získá možnost vyjádřit mnohem větší počet vztahů, což v tradičních lineárních strukturách nebylo možné. Philip Schreur k této výhodě doplňuje ještě výhodu flexibility. Na příkladu pravidel RDA ukazuje přechod od principu jedné sady pravidel, platné pro všechny typy zdrojů a jejich uživatelů, k modulární platformě pro tvorbu vlastních interpretací – katalogizačních politik a aplikačních profilů. (Schreur, 2018) Zdá se, že aplikace jednoduché struktury propojených dat je cestou, jak sladit potřebu jednotného standardu a individuálních řešení pro specifické domény a případy užití.
Závěr
V článku jsme se pokusili shrnout základní poznatky, k nimž dospěli odborníci z různých oblastí zabývající se metadaty. Je však zřejmé, že výzkum tohoto fenoménu se zatím nachází ve velmi raném stadiu. V zájmu pokroku v tomto směru se jeví jako nosné tyto výzkumné otázky:
- Jaká je ontologická povaha metadat? Jak odlišit „data“ od metadat?
- Jaká je obecná forma metadat? Musí mít metadata vždy formát výroku? Musí být metadata vždy strukturovaná? Pokud ano, jaká je optimální struktura metadat? Musí mít metadata vždy strukturu atribut–hodnota?
- Jaká jsou kritéria kvality a důvěryhodnosti metadat?
- Jak řešit heterogenitu (obsahu, formy, kvality, důvěryhodnosti atd.) metadat v sémantickém webu? Jak zajistit jejich interoperabilitu? Pravidly? Mapováním? Umělou inteligencí? Vzděláváním uživatelů?
- Který způsob správy metadat v sémantickém webu je nejvhodnější? Laicizace a anonymizace (směr bottom-up, vzor Wikidata, folksonomie, crowdsourcing, volná nebo žádná pravidla) nebo profesionalizace a autentizace (směr top-down, vzor knihovní katalog, označování původu a autorství, sledování změn, závazná pravidla)?
- Jak začlenit bibliografická metadata, vzniklá v uzavřeném prostředí specializovaných institucí, do sémantického webu, v němž platí předpoklad otevřeného světa?
Poslední otázku by bylo možné zformulovat i dramatičtějším způsobem, například: Jsou bibliografická metadata vytvářená knihovnami použitelná mimo tento kontext, tj. mimo knihovny? Mají intelektuálně vytvářená popisná metadata produkovaná informačními profesionály budoucnost? Ani na tuto otázku nenabízíme odpovědi, ale naznačíme několik předběžných hypotéz. Představu budoucího vývoje lze samozřejmě modelovat optimisticky i pesimisticky. Pesimistická prognóza by mohla vypadat tak, že knihovní bibliografická metadata zůstanou mimo sémantický web, budou sloužit pouze pro vnitřní evidenční potřebu knihoven a uživatelé o ně nebudou mít zájem. Další pesimistickou alternativou je začlenění bibliografických metadat do sémantického webu tím, že se přizpůsobí „laicizaci“ metadat a zřeknou se snahy o kvalitu a sémantickou sílu. Optimistická prognóza zní: Bibliografická metadata produkovaná knihovnami se stanou páteří sémantického webu a budou garantovat jeho kvalitu a důvěryhodnost.
Odpověď na otázku, zda se optimistickou prognózu podaří naplnit, by mohla znít ano, pokud knihovny:
- Budou prostřednictvím metadat skutečně přidávat hodnotu k informačním zdrojům. Přidaná hodnota nevznikne přepisováním údajů z titulního listu, ale je často výsledkem bibliografické heuristiky. Tvůrčí přístup je nutné uplatnit jak při interpretaci modelů a pravidel, tak během zjišťování údajů pro popis. V zásadě platí, že každý popisovaný zdroj má nějaká specifika a problémy při tvorbě metadat je vždy třeba řešit individuálně. Proces zjišťování údajů pro popis se tak může přiblížit badatelskému popisu muzejních exponátů či archiválií nebo vědeckému popisu faktů (včetně s tím spojených finančních nákladů).
- Budou propojovat vytvořená metadata s dalšími údaji. To není záležitost formy, ale obsahu, protože v koncepci propojených dat je prostřednictvím vztahů vyjádřena jejich sémantika.
- Budou vytvářet metadata ve vysoké kvalitě.
- Budou využívat veškerý potenciál vytvořených metadat prostřednictvím atraktivní prezentace umožňující, aby běžný uživatel profitoval z informací, jež jsou v nich obsaženy.
- Budou akceptovat, že nejsou monopolními tvůrci bibliografických metadat, a zajistí sémantickou interoperabilitu svých produktů především s profesionální sférou vydavatelů a knihkupců, ale i s metadaty, jež vytvářejí čtenáři, uživatelé a autoři.
Jsme přesvědčeni, že naplnit naznačenou optimistickou prognózu je pro knihovny nikoli možností, ale povinností. Stejně jako se tradičně věnují archivaci, zpracování a zpřístupňování informačních zdrojů, měly by se v budoucnu stát správci metadat, a to nejen jejich souborů v datových sadách, ale především jejich slovníků a schémat. Na rozdíl od informačních zdrojů, jež knihovny nevytvářejí, ale „pouze“ spravují a zprostředkovávají uživatelům, je tvorba a správa bibliografických metadat bezesporu hlavní tvůrčí činností knihoven. Princip otevřeného světa, uplatňovaný v sémantickém webu, by neměl být pro knihovny překážkou. Vzhledem k tomu, že mají takřka ve své DNA respekt k jevu známému jako literary warrant, který je analogií principu AAA (anyone can say anything about anything) v sémantickém webu, mají knihovny potenciál začlenit se do otevřeného prostředí sémantického webu. Vize Patricka Wilsona, který vidí budoucnost knihovnické profese v úloze knihovníka jako bibliografa, tj. tvůrce bibliografických metadat (Wilson, 1998, s. 315), by tak mohla dojít svého naplnění.
Literatura
ALCTS, 2012. Committee on cataloging: description & access Task force on metadata: Final report [online]. CC:DA/TF/Metadata/5. June 16, 2000. Last updated 07/12/2012 [cit. 2019-09-26]. Dostupné z: http://downloads.alcts.ala.org/ccda/tf-meta6.html.
ALLEMANG, Dean a James HENDLER, 2011. Semantic web for the working ontologist: effective modeling in RDFS and OWL. 2nd ed. Waltham (MA), Amsterdam: Morgan Kaufmann/Elsevier. xiii, 354 s. ISBN 978-0-12-385966-2 (online). ISBN 978-0-12-385965-5 (print).
BAGLEY, Philip R., 1968. Extension of programming language concepts. Philadelphia: University City Science Center, November 1968. 210 s. Digitalizovaná verze dostupná z: https://apps.dtic.mil/dtic/tr/fulltext/u2/680815.pdf [cit. 2019-09-26].
BAKER, Thomas et al., 2011. Library Linked Data Incubator Group final report [online]. W3C Incubator Group report 25 October 2011. W3C, 2011 [cit. 2019-09-26]. Dostupné z: http://www.w3.org/2005/Incubator/lld/XGR-lld.
BAKER, Thomas, Karen COYLE a Sean PETIYA, 2014. Multi-entity models of resource description in the Semantic Web: a comparison of FRBR, RDA, and BIBFRAME. In: Library Hi Tech. 32(4), 562–582. Dostupné z: https://doi.org/10.1108/LHT-08-2014-0081. ISSN 0737-8831.
BERNERS-LEE, Tim a Lalana KAGAL, 2008. The fractal nature of the semantic web. In: AI magazine. Fall 2008, 29(3), 29–34. ISSN 0738-4602.
BERNERS-LEE, Tim, 1997. Web architecture: metadata [online]. W3C, January 1997 [cit. 2019-09-26]. Dostupné z: https://www.w3.org/DesignIssues/Metadata.html.
BRATKOVÁ, Eva, 1999. Metadata jako nový nástroj pro komunikaci webovských informačních zdrojů. In: Národní knihovna. 10(4), 178–195. ISSN 0832-7487.
BRIET, Suzanne, 1951. Qu‘est-ce que la documentation? Paris: ÉDIT. 45 s.
CAPLAN, Priscilla, 2003. Metadata fundamentals for all librarians. Chicago: American Library Association. ix, 192 s. ISBN 978-0-8389-0847-1.
COYLE, Karen, 2010. Understanding the semantic web: bibliographic data and metadata. Chicago (IL): American Library Association. 31 s. Library technology reports, vol. 46, no. 1 (January), ISSN 0024-2586.
ECO, Umberto, 2009. Není seznam jako seznam. In: Bludiště seznamů. Praha: Argo, s. 113–129. ISBN 978-80-257-0164-5.
GARTNER, Richard, 2016. Metadata: shaping knowledge from antiquity to the semantic web. [Cham]: Springer. 114 s. ISBN 978-3-319-40891-0 (brož.). ISBN 978-3-319-40893-4 (e-book).
GILLILAND, Anna, 2016. J. Setting the stage. In: Introduction to metadata [online]. Edited by Murtha Baca. 3rd ed. Los Angeles: Getty Research Institute [cit. 2019-09-26]. ISBN 978-1-60606-500-6 (online). Dostupné z: http://www.getty.edu/publications/intrometadata/.
IFLA, 2017a. Best practice for national bibliographic agencies in a digital age [online]. 2017– [cit. 2019-09-26]. Dostupné z: https://www.ifla.org/node/7858.
IFLA, 2017b. IFLA library reference model: a conceptual model for bibliographic information [online]. Pat Riva, Patrick LeBoeuf, Maja Žumer, ed. Hague: International Federation of Library Associations and Institutions, rev. August 2017 as amended and corrected through December 2017 [cit. 2019-09-26] s. 49–50. Dostupné z: https://www.ifla.org/publications/node/11412.
ISO 5127, 2017. Information and documentation – Foundation and vocabulary. 2nd ed. Geneva: International Organization for Standardization, 2017-05. 353 s.
ISO/IEC 2382, 2015. Information technology – Vocabulary [online]. 1st ed. Geneva: International Organization for Standardization, 2015-05 [cit. 2019-09-26]. Dostupné z: https://www.iso.org/obp/ui/#iso:std:iso-iec:2382:ed-1:v1:en.
ISO/IEC 11179-1, 2015. Information technology – Metadata registries (MDR) – Part 1: Framework. 3rd ed. Geneva: International Organization for Standardization, 2015. 22 s.
KUČEROVÁ, Helena, 2018. Pojem modelu a pojmový model v informační vědě. In: Knihovna: knihovnická revue. 29(2), 5–32. ISSN 1801-3252 (print). ISSN 1802-8772 (online).
Library of Congress, 2008. On the record: report of The Library of Congress Working Group on the Future of Bibliographic Control [online]. Washington: Library of Congress, 2008 [cit. 2019-09-26], s. 6. Dostupné z: https://www.loc.gov/bibliographic-future/news/lcwg-ontherecord-jan08-final.pdf.
MAREŠ, Petr, 2017. Metatext (metatextovost). In: Petr Karlík, Marek Nekula a Jana Pleskalová, ed. CzechEncy – Nový encyklopedický slovník češtiny [online]. Brno: Masarykova univerzita, 2012–2018 [cit. 2019-09-26]. Dostupné z: https://www.czechency.org/slovnik/METATEXT.
MURRAY, Ronald J. a Barbara B. TILLETT, 2011. Cataloging theory in search of graph theory and other ivory towers. In: Information theory and libraries (ITAL). December 2011, 30(4), 170–184. Dostupné z: https://doi.org/10.6017/ital.v30i4.1868. ISSN 2163-5226.
NEKVAPIL, Jiří, Jana HOFFMANNOVÁ a Eva HAJIČOVÁ, 2017. Diskurz. In: Petr KARLÍK, Marek NEKULA a Jana PLESKALOVÁ, ed. CzechEncy – Nový encyklopedický slovník češtiny [online]. Brno: Masarykova univerzita, 2012–2018 [cit. 2019-09-26]. Dostupné z: https://www.czechency.org/slovnik/DISKURZ.
POMERANTZ, Jeffrey, 2015. Metadata. Cambridge: The MIT Press. 239 s. The MIT Press Essential Knowledge series. ISBN 978-0-262-52851-1.
RILEY, Jenn, 2017. Understanding metadata: what is metadata, and what is it for? Baltimore: National Information Standards Organization (NISO). 45 s. NISO Primer. ISBN 978-1-937522-72-8. Dostupné též z: https://www.niso.org/publications/understanding-metadata-2017 [cit. 2019-09-26].
SCHREUR, Philip, 2018. RDA, linked data, and the end of average. In: JLIS.it. January 2018, 9(1), 120–127. Dostupné z: http:// doi.org/10.4403/jlis.it-12448. ISSN 2038-1026
SVENONIUS, Elaine, 1992. Bibliographic entites and their uses. In: Seminar on bibliographic records: Proceedings of the seminar held in Stockholm, 15–16 August 1990, and sponsored by IFLA UBCIM Programme and the IFLA Division of bibliographic control. Ross Bourne, ed. Műnchen: Saur, s. 3–18. UBCIM Publications. Vol. 7. ISBN 3-598-11085-5.
WILSON, Patrick, 1998. Patrick Wilson: a bibliographer among the catalogers. In: Cataloging & classification quarterly. 25(4), 305–316. ISSN 0163-9374 (print). ISSN 1544-4554 (online).
WILSON, Patrick, 1968. Two kinds of power: an essay on bibliographical control. Berkeley: University of California Press, 1978, © 1968. 155 s. California library reprint series.
ISBN 978-0-520-03515-7.
W3C RDF Working Group, 2014. Resource description framework (RDF) [online]. Last modified 2014-03-15 [cit. 2019-09-26]. Dostupné z: http://www.w3.org/RDF/.
YEE, Martha M., 2009. Can bibliographic data be put directly onto the Semantic Web? In: Information technology & libraries. June 2009, 28(2), 55–80. ISSN 0730-9295.
ZENG, Marcia Lei a Jian QIN, 2016. Metadata. 2nd ed. Chicago: Neal-Schuman, an imprint of the American Library Association. xxvii, 555 s. ISBN 978-1-55570-965-5.
ŽUMER, Maja, ed., 2009. National bibliographies in the digital age: guidance and new directions. München: Saur, 2009. 140 s. IFLA Series on Bibliographic Control, vol. 39. ISBN 978-3-598-24287-8.
KUČEROVÁ, Helena. Bibliografická metadata v sémantickém webu. Knihovna: knihovnická revue, 2019, 30(2), 5–35. ISSN 1801-3252.
1 Cit. dle COLE, David, 2014. ‚We kill people based on metadata‘. In: The New York review of books. 2014-05-10 [cit. 2019-09-26]. Dostupné z: https://www.nybooks.com/daily/2014/05/10/we-kill-people-based-metadata/.
2 Podrobněji viz např. ŠLERKA, Josef, 2014. Just metadata [online]. Záznam vystoupení na konferenci New Media Inspiration 2014. Praha: Studia nových médií FF UK, 2014-02-08 [cit. 2019-09-26]. Dostupné z: https://www.youtube.com/watch?v=_2ku9E7swr4.
3 Metadata, n. In: OED: Oxford English Dictionary [online]. Oxford: Oxford University Press, © 2014 [cit. 2019-09-26]. Dostupné komerčně z: http://www.oed.com/view/Entry/117150.
4 FOLDÈS, Peter (režie), 1971. Metadata. National Film Board of Canada [cit. 2019-09-26]. 8 min. Dostupné z: https://www.nfb.ca/film/metadata_en/.
5 Dostupné z: https://www.czso.cz/csu/czso/databaze_metainformaci [cit. 2019-09-26].
6 Dostupné z: http://apl.czso.cz/iSMS/ukazvyb.jsp [cit. 2019-09-26].
7 Ostatně z tohoto důvodu i mnozí autoři z jiných oblastí používají alternativní pojmenování a v jejich definicích se lze setkat s termíny dokument, informace, informační objekt, objekt obsahující informace, objekt v síti, primární data, záznam, zdroj, znalost.
8 Doslova: „Metadata jsou výrok o potenciálně informativním zdroji“ (Pomerantz, 2015, s. 26).
9 Česko. Zákon č. 499/2004 Sb. ze dne 30. 6. 2004, o archivnictví a spisové službě, ve znění pozdějších předpisů. Aktuální znění k 24. 4. 2019.
10 National Information Standards Organization
11 BRUKNER, Josef a Jiří FILIP, 1968. Větší poetický slovník. Praha: Československý spisovatel, s. 236.
12 CELBOVÁ, Ludmila, 2003. Metadata. In: KTD: Česká terminologická databáze knihovnictví a informační vědy (TDKIV) [online]. Praha: Národní knihovna ČR, 2003– [cit. 2019-09-26]. Dostupné z: http://aleph.nkp.cz/F/?func=direct&doc_number=000000543&local_base=KTD.
13 Podrobněji jsme se modelům a jejich vztahu k metadatům věnovali v samostatné studii (Kučerová, 2018).
14 Poznámka: přístup ke zdrojům je možný i bez metadat – oba způsoby mají své výhody a nevýhody.
15 Terminologická poznámka: V současné době mnozí autoři zejména v kontextu sémantického webu používají pro bibliografická metadata též označení bibliografická data nebo bibliografické informace.
16 SKOLEK, Jaroslav a Marie BALÍKOVÁ, 2017. Bibliografická kontrola. In: KTD: Česká terminologická databáze knihovnictví a informační vědy (TDKIV) [online]. Praha: Národní knihovna ČR, 2003– [cit. 2019-09-26]. Dostupné z: http://aleph.nkp.cz/F/?func=direct&doc_number=000000296&local_base=KTD.
17 SKOLEK, Jaroslav, 2003. Bibliografická heuristika. In: KTD: Česká terminologická databáze knihovnictví a informační vědy (TDKIV) [online]. Praha: Národní knihovna ČR, 2003– [cit. 2019-09-26]. Dostupné z: http://aleph.nkp.cz/F/?func=direct&doc_number=000000291&local_base=KTD.
18 Terminologická poznámka: Aktuální knihovnická terminologie, reprezentovaná v Ustanovení mezinárodních zásad katalogizace, používá termín bibliografický zdroj.
19 Terminologická poznámka: Aktuální knihovnická terminologie, reprezentovaná v Ustanovení mezinárodních zásad katalogizace, používá pro označení těchto dvou skupin údajů termíny bibliografická data a autoritní data.
20 ŠKVORECKÝ, Josef, 2006. Detektivky v mém životě. In: Listy: dvouměsíčník pro politickou kulturu a občanský dialog. 36(3). ISSN 1210-1222. Online verze dostupná z: http://www.listy.cz/archiv.php?cislo=063&clanek=obsah [cit. 2019-09-26].
21 Viz např. KOCANDA, Martin, 2019. V digitální podobě bude přístupných stále více publikací [online]. In: Česká pozice. 2019-08-24 [cit. 2019-09-26]. ISSN 1213-1385. Dostupné z: http://ceskapozice.lidovky.cz/tema/v-digitalni-podobe-bude-pristupnych-stale-vice-publikaci.A190820_172941_pozice-tema_lube.
22 Výsledky průzkumu jsou dostupné z: https://www.oclc.org/research/themes/data-science/linkeddata/linked-data-survey.html [cit. 2019-09-26].
KUČEROVÁ, Helena. Bibliografická metadata v sémantickém webu. Knihovna: knihovnická revue, 2019, 30(2), 5–35. ISSN 1801-3252.