Pojem modelu a pojmový model v informační vědě
Klíčová slova: pojmový model, informační věda, doménová ontologie, metadatové schéma, model
Summary: Modeling and application of models affect virtually all areas of human activity, including those of interest to information science. Although the creation and use of models have always been implicitly included in the practice of libraries and other memory institutions, their explicit exploration by information science so far has been concentrated more on the application of knowledge from other disciplines, particularly from computer science. The aim of this study is to suggest ways in which thinking about models in information science could be taken towards forming the theory of conceptual models applicable in the processes of obtaining, processing and using information resources. For the description of the conceptual models, a faceted structure, loosely based on the 5W1H method, is proposed. The facets have been derived from an analysis of the structural components of the model: they determine what is being modeled, who is the creator and who is the model user, wherewith it is modeled, for what the model is used. From the semiotics perspective, the functions of conceptual models relevant to information science are specified and the typology of their content and form is proposed, set out in the context of conceptual models and modeling languages in computer science. Conceptual models in information science are divided into conceptual reference models, and metadata models comprising metadata element sets, metadata schemas, and value vocabularies. Their characteristics are accompanied by representative examples of each type.
Keywords: conceptual model, information science, domain ontology, metadata schema, model
PhDr. Helena Kučerová, Ph.D. / Ústav informačních studií a knihovnictví FF UK v Praze (Institute of Information Studies and Librarianship, Faculty of Arts, Charles University in Prague), Filozofická fakulta Univerzity Karlovy, U Kříže 8, 158 00 Praha 5 – Jinonice

Všechny modely jsou špatné; některé modely jsou užitečné.1 George Edward Pelham Box (1919–2013)
Úvod
Tvorba a aplikace modelů provázejí prakticky všechny typy lidských činností. Jsou zahrnuty jak v subjektivních kognitivních procesech, tak v objektivních metodách vědeckého zkoumání a inženýrských návrhů. Modely se vytvářejí v rámci umělecké tvorby, během komunikačních aktivit i praktické činnosti. Rovněž v oblasti, jež je předmětem zájmu informační vědy, lze pozorovat tuto šíři záběru: v České terminologické databázi knihovnictví a informační vědy (TDKIV) lze najít jak termíny označující modely konkrétní (knižní maketa, mapa, koncept, šablona dokumentu ad.), tak termíny vztahující se k nejrůznějším typům modelů abstraktních (databázový model, konceptuální model databáze, logický model databáze, metainformační systém, relační datový model, model otevřeného přístupu ad.). Jak bude ukázáno v části 3.2, za modely lze považovat i významnou kategorii objektů informační vědy – sekundární zdroje a metadata včetně systémů organizace znalostí. Tak můžeme chápat například katalog jako model knihovního fondu, anotaci či rejstřík jako modely obsahu knihy, bibliografický soupis nebo profil knihovního fondu jako modely množiny zdrojů, bibliografický údaj jako model vlastnosti dokumentu, selekční obraz dokumentu/dotazu jako model jejich obsahu, rešeršní profil jako model potřeb uživatele atd.
I když lze konstatovat, že tvorba a používání modelů byly vždy implicitně obsaženy v praxi knihoven a dalších paměťových a fondových institucí, jejich explicitní zkoumání informační vědou je zatím v počátcích. Zájem o teoretickou problematiku modelování v informační vědě lze skutečně zaznamenat teprve od konce 90. let 20. století, kdy byl publikován model IFLA FRBR (Funkční požadavky na bibliografické záznamy). Dosavadní aktivity se však zatím soustředily spíše na aplikaci poznatků z jiných oborů, především informatiky. Při povrchním pohledu vycházejícím z aktuálně používané terminologie (konceptuální model, model entit a vztahů, datový model) by se tak mohlo zdát, že modelování a modely přinesla do informační vědy až informatika. Už jen trochu důkladnější analýza širších teoretických i praktických souvislostí modelové tvorby však ukáže, že artefakty označované v současné době jako modely byly vytvářeny v knihovnách a dalších paměťových a fondových institucích od nepaměti, nebyly tak ovšem označovány ani vnímány. Tento „implicitní“ přístup ke tvorbě a aplikaci modelů je však žádoucí nahradit explicitním zkoumáním, které umožní zformovat vlastní teorii odpovídající specifickému předmětu zkoumání a metodám informační vědy. V tomto článku se proto pokoušíme načrtnout směry, jimiž by se podle našeho názoru uvažování o modelech v informační vědě mohlo ubírat. V souladu s převažujícími typy modelů v této doméně se zaměřujeme na pojmové modely.2
Inspirací pro informační vědu může být v tomto ohledu právě obor informatiky, který nastoupil cestu k vlastní teorii pojmových modelů už v 60. letech 20. století. Výsledkem je rozsáhlá poznatková základna zachycená v četných příspěvcích z konferencí, článcích v odborných časopisech a ve vědeckých monografiích, učebnicích a příručkách, která umožnila konstituovat vlivný proud teoretického uvažování, jenž přináší inspiraci a aplikační příležitosti i jiným vědním disciplínám. Tak jako se odborníci v informatických oborech zaměřili na budování teoretických základů pojmových modelů využívaných při návrhu databázových a znalostních systémů a při tvorbě počítačových programů, je zapotřebí v informační vědě soustředit se na pojmové modely aplikované na klíčové předměty jejího zájmu. Informační vědu chápeme v souladu s pojetím Davida Bawdena a Lyn Robinsonové jako „obor studia zabývající se zaznamenanými informacemi se za měřením na komponenty komunikačního řetězce zkoumané prostřednictvím perspekti vy doménové analýzy“ (Bawden a Robinson, 2017, s. 30). Pojmové modely informační vědy by tedy měly zachycovat především informační zdroje a procesy jejich získávání, zpracování a využívání.
Text článku je strukturován do tří částí. V první části je zformulováno pracovní vymezení modelu a modelové tvorby, používané v tomto textu. Je navržena fasetová struktura pro charakteristiku modelů, vycházející z analýzy vlastností, vztahů a funkcí strukturních komponent modelu. Fasety volně vycházejí z metody 5W1H: určují, co se modeluje, kdo je tvůrce a kdo je uživatel modelu, čím se modeluje a k čemu je model používán. Druhá část se věnuje charakteristice pojmových modelů. S uplatněním perspektivy sémiotiky je podán rámcový přehled modelovacích jazyků a je specifikováno pět typů funkcí pojmových modelů, které jsou významné pro informační vědu. Prostřednictvím procesního pohledu jsou popsány tři klíčové fáze tvorby pojmového modelu. Ve třetí části je navržena typologie obsahu a formy pojmových modelů relevantních pro informační vědu. Protože pojmové modelování v informatice zásadním způsobem ovlivnilo praxi „novodobého“ pojmového modelování v informační vědě, je v rámci této části podán i jeho stručný přehled. Pojmové modely v informační vědě jsou rozčleněny do dvou skupin, z nichž první představují referenční pojmové modely a druhou skupinou jsou modely metadat zahrnující soubory metadatových prvků, metadatová schémata a slovníky hodnot metadat. Charakteristika jednotlivých typů pojmových modelů je doplněna příklady jejich významných zástupců. Zvláštní pozornost je věnována specifické kategorii pojmových modelů v informační vědě, jíž jsou systémy organizace znalostí a jejich pojmové modely.
1 Model a modelování
1.1 Definice modelu?
Otazník v názvu této části naznačuje pochybnosti, zda je vůbec možné model jednoznačně definovat. Rozsáhlost a rozmanitost oblasti použití modelů a jejich všudypřítomnost, konstatovaná již v úvodu, dovedla například Jochena Ludewiga (2003, s. 5) až k tvrzení, že k obecně použitelnému a konzistentnímu chápání modelu nelze dospět. Určitá shoda může nastat pouze na velmi obecné úrovni, kdy se za model prohlásí jakákoli reprezentace objektu nebo jevu či děje, jež se s tímto objektem, jevem či dějem shoduje v podstatných vlastnostech. O tom, které vlastnosti jsou podstatné, rozhoduje účel modelu. Aforismus George Boxe, uvedený v mottu článku, vystihuje lapidárně tento princip: cílem modelu není být stejný jako originál, ale posloužit nějakému konkrétně stanovenému účelu.
Model budeme chápat jako umělý výtvor, tj. artefakt, záměrně za určitým cílem vytvářený agentem ve funkci subjektu. Tímto výtvorem může být jakákoli myšlenková nebo materiální konstrukce. Od ostatních umělých výtvorů se model odlišuje svým specifickým účelem, jímž je reprezentace originálu ve funkci objektu (předmětu). Pragmatickým cílem této reprezentace může být poznání originálu, jeho vytvoření či návrh, ale i vytvoření vzoru vzhledu, struktury či chování originálu nebo jeho optimalizace. Klíčovými specifickými odlišujícími vlastnostmi modelu jsou vztah korespondence s jiným objektem, díky němuž model může tento objekt reprezentovat, a zároveň existenční závislost na tomto objektu. Podmínkou existence modelu je totiž existence reprezentovaného objektu – model je vždy vztažen k „něčemu“, co nazýváme originálem, ať už to existuje fyzicky („reálně“), nebo v naší mysli, kdy o něčem přemýšlíme, něco vymýšlíme3či to plánujeme vytvořit. Taková vysoce abstraktní definice přibližuje chápání modelu klasickému sémiotickému pojetí znaku, kterým je podle Charlese Sanderse Peirce „něco, co pro někoho něco zastupuje z nějakého hlediska nebo v nějaké úloze“.4Na obrázku 1 jsou schematicky znázorněny tři klíčové entity modelové tvorby – model, originál a agent, a jejich vztahy, jež jsou dvojího typu: vztahy (konkrétního) přímého působení a vztah (abstraktní) korespondence.

Obr. 1 Model, originál a agent
Vztah přímého působení agenta a modelu má dva klíčové aspekty. Prvním je vztah (1) – vytvoření modelu a používání modelu agentem. Vztah označený na obrázku číslem (2) je realizován jako nepřímý – model zastupuje pro agenta originál. Typickým zástupným vztahem je poznání originálu prostřednictvím modelu, například poznání regionu podle jeho mapy.
Vztahy přímého působení agenta a originálu mohou mít nejrůznější podobu, pro naše účely se zaměříme na vztahy, v jejichž rámci se využívá model. Typickým vztahem tohoto typu je tvorba či přizpůsobení originálu agentem podle modelu, označená číslem (3), například vytvoření dokumentu podle připravené šablony nebo konverze záznamu do požadovaného formátu.
Vztah modelu a originálu je označen jako abstraktní vztah korespondence. Případný vliv originálu na model nebo vliv modelu na originál tedy není nikdy přímý, ale realizuje se prostřednictvím agenta. Vztah korespondence je asymetrický, a to ze dvou příčin. Zaprvé vztah korespondence není nikdy realizován jako ekvivalence 1:1, ale jako vztah založený na podobnosti. To znamená, že model a originál se neshodují ve všech svých vlastnostech. Typickým případem je model abstrahující od podrobností, který může právě díky tomuto zobecnění být použit pro více objektů. Obvyklé jsou ale i případy, kdy jsou do modelu začleněny i prvky, jež v originále nejsou obsaženy (například souřadnice na mapě), aby umožnily plnění cíle modelu. Někdy se ještě specifikuje konkrétní typ podobnosti, nejčastěji prostřednictvím rozlišení mezi izomorfií a analogií. Termín izomorfie se používá pro označení korespondence formy, tj. vnějšího vzhledu, analogie obvykle označuje strukturální (vnitřní, obsahovou) podobnost. Druhou příčinou asymetrie je, že samotný vztah podobnosti je pouze jednosměrný. Jak ukazují šipky označené čísly (4) a (5), model je buď podobný originálu, nebo je originál podobný modelu, nikdy neplatí obojí současně. Tato bipolarita souvisí s problematikou deskriptivních a preskriptivních modelů, o níž bude pojednáno v následující části.
1.2 Typologie modelů založená na fasetové analýze
Stejně jako je obtížné najít obecně přijímanou definici modelu, je neméně obtížné zvolit jedno obecně přijímané kritérium členění pro jejich typologii. To, že v přístupu k typologii modelů lze uplatnit množství různých pohledů, z nich činí vhodný objekt fasetové analýzy. Fasety navržené pro typologii modelů v této části jsou odvozeny z analýzy vlastností, vztahů a funkcí strukturních komponent modelu uvedených na obrázku 1 a specifikují, co se modeluje, kdo je tvůrce a kdo je uživatel modelu, čím se modeluje a k čemu je model používán. Při jejich návrhu jsme volně vycházeli z metody 5W1H (zkratka je vytvořena z prvních písmen anglických tázacích zájmen who – kdo, what – co, where – kde, when – kdy, why – proč, how – jak). Metodu 5W1H lze považovat za „naivní“ podobu fasetové analýzy. Její víceméně intuitivní přístup k celostnímu zkoumání však právě díky své názornosti a snadné aplikovatelnosti našel uplatnění v celé řadě odvětví. Využil ho mimo jiných i Bernhard Thalheim (2011), který k charakteristice pojmových modelů v informatice použil fasety wherefore (proč), whereof (z čeho/o čem), wherewith (čím), whereto (k čemu), how (jak), when (kdy), for which reason (z jakého důvodu), by whom (kým), to whom (pro koho), for what (pro co), where (kde) a další.
Faseta odvozená z vlastností entity Originál/objekt – CO se modeluje
Všudypřítomnost modelů je příčinou toho, že rozsah této fasety je prakticky neohraničený. Předmětem, který se modeluje, může být cokoli, jakýkoli objekt zájmu agenta, dokonce i sám agent nebo jiný model (i model lze modelovat – v takovém případě zpravidla hovoříme o metamodelu). „Být originálem“ tedy není trvalá vlastnost objektu, ale role ve vztahu ke konkrétnímu modelu (obdobně to platí i pro model).
Jedním z nejobecnějších kritérií členění v této fasetě je hledisko času. Podle toho, zda se modelují změny originálu v čase či nikoli, se rozlišují modely statické a dynamické. Statické modely se zaměřují na zachycení relativně stabilních struktur; příkladem je model bibliografické citace podle normy ISO 690 nebo model uspořádání dat ve formátu MARC21. Dynamické modely zachycují procesy (příkladem je model podnikových procesů znázorněný pomocí vývojového nebo stavového diagramu), ale i pravidla a metody, například katalogizační pravidla RDA nebo metody bibliometrické analýzy.
Fasety odvozené z vlastností entity Agent/subjekt – KDO je tvůrce modelu a KDO je uživatel modelu
V rámci této fasety opět platí, že tvůrcem i skutečným či zamýšleným uživatelem modelu může být kdokoli – laik, profesionál, jednotlivec, skupina či instituce ad. Navíc v roli tvůrce i v roli uživatele může vystupovat jak člověk, tak stroj.
Fasety odvozené z vlastností entity Model – ČÍM se modeluje a K ČEMU je model používán
I v případě fasety ČÍM obecně platí, že model lze vytvořit z čehokoli, může být abstraktní i konkrétní, může, ale nemusí to být objekt stejného typu jako originál. Podle stupně abstrakce lze řadit modely na plynulé škále od obecných (abstraktních) po modely konkrétní. Rozlišení mezi těmito dvěma typy je vedeno po linii podílu fyzických komponent a jejich úlohy v modelu. Zatímco v konkrétních modelech fyzické části představují obsah modelu (příklady jsou sádrový model budovy nebo sochy, prototyp automobilu nebo uživatelského rozhraní informačního systému), případné fyzické části abstraktních modelů slouží pouze pro záznam obsahu modelu, jako jeho hmotný nosič.
Dalším obecným kritériem pro členění modelů ve fasetě ČÍM je míra standardizace a formalizace použitých modelovacích prostředků. Výhodou standardizovaných nástrojů je usnadnění komunikace a sdílení vytvořených modelů. Individuálně vytvářené modely naopak umožňují uplatnit vyšší míru kreativity a často i přesnosti ve vystižení vlastností originálu, obvykle ovšem za cenu ztížené komunikace.5
V rámci fasety K ČEMU lze rozčlenit modely podle jejich obecného účelu do skupin, jež pracovně označíme jako ontologické a gnozeologické. Účelem ontologického modelu je náhrada originálu, zatímco primárním účelem gnozeologického modelu je poznání originálu. Ontologický model umožňuje fyzickou manipulaci. Gnozeologický model obsahuje informace o originálu, umožňuje pochopení, vysvětlení, porozumění originálu. Jochen Ludewig (2003, s. 8) nabízí alternativní perspektivu, v jejímž rámci člení modely podle vztahu k originálu na deskriptivní a preskriptivní. Deskriptivní model popisuje originál. Předmětem popisu může být cokoli, co aktuálně existuje, existovalo či teprve vznikne (v tomto smyslu je deskriptivním modelem například i předpověď počasí), ale i představy či abstraktní ideje. Preskriptivní model má za cíl ovlivnit originál. Typickým způsobem ovlivnění je vytvoření originálu podle modelu, nicméně preskriptivní model nemusí vždy sloužit k tvorbě originálu – například model společenského chování má „pouze“ ovlivnit chování lidí. Obdobné pojetí deskripce a preskripce se používá v lingvistice. František Čermák je charakterizuje jako „nezaujatý a věrný (vědecký) popis … a autoritativní před pisování jen určitých vybraných forem jako vhodných či správných“ (Čermák, 2007, s. 98). Rovněž v terminologické činnosti se rozlišuje mezi deskriptivní prací, která se zaměřuje na shromažďování termínů z určité oblasti, a prací s preskriptivním účelem, jejímž cílem je prosadit používání doporučených termínů (Cabré, 1999, s. 32).
Další perspektiva rozlišuje modely podle komunikačního záměru na interní implicitní modely a na objektivní sdílené explicitní modely. Blíže bude o těchto typech modelů pojednáno v části 2 v souvislosti s pojmovými modely.
V tabulce 1 jsou uvedeny příklady modelů z knihovní praxe, popsané pomocí navržené fasetové struktury. Modely jsou rozděleny do tří skupin označených čísly: ve skupině 1 jsou statické modely objektů a struktur, ve skupině 2 dynamické modely událostí a procesů a skupina 3 obsahuje dva příklady abstraktních modelů pojmů. Pro názornost jsou ve fasetách CO, KDO a ČÍM uvedeny kurzívou i konkrétní příklady instancí.
Tab. 1 Příklady uplatnění fasetové analýzy při popisu modelů
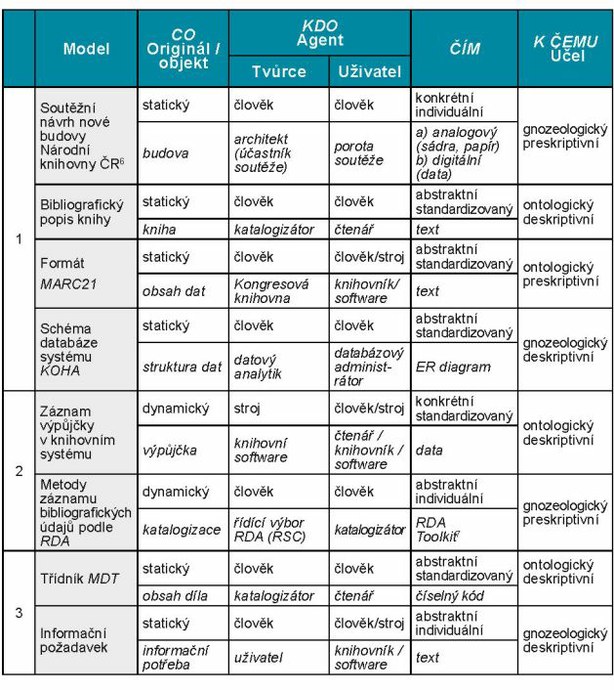
Snahu po jednoznačné kategorizaci modelů komplikuje nestabilita a relativita jejich komponent. Výjimkou nejsou ani modely, které v průběhu své existence mění svůj účel – obvyklou změnou je, že se deskriptivní model mění na preskriptivní. Například informační požadavek je nejprve deskriptivním modelem informační potřeby a poté preskriptivním modelem požadavku na zdroje; specifikace požadavků na informační systém se tvoří jako deskriptivní model uživatelských potřeb a po schválení může sloužit jako preskriptivní model vytvářeného systému. Obdobnou transformaci prodělaly entity modelu FRBR, které se z původního popisu uživatelských požadavků na bibliografické záznamy staly součástí preskriptivního modelu – katalogizačních pravidel RDA.
Ze vztahu podobnosti mezi modelem a originálem se odvíjejí problémy s jejich vzájemným odlišením. Jochen Ludewig (2003, s. 11) v této souvislosti upozorňuje na to, že dobré modely mohou být tak dobré, až svádějí k záměně s originálem. Taková situace může nastat jak u deskriptivních modelů, tak u modelů preskriptivních. Typické jsou případy záměny datových modelů reality (tj. modelů tvořených daty) v počítači za skutečnost, přičemž nemusí jít jen o virtuální realitu. Časté jsou situace, kdy se plán pokládá za skutečnost nebo kdy uživatel považuje předváděný prototyp za hotový artefakt.
Relativita komponent se projevuje v tom, že stejný objekt může v různých časových úsecích nebo pro různé agenty či pro různé účely plnit jednou roli modelu a podruhé roli originálu. To platí v plné míře pro klíčové objekty zájmu informační vědy, jimiž jsou informace, data, metadata a znalosti. Například na data lze pohlížet jako na model, který reprezentuje realitu v informačním systému, ale i jako na originál, reprezentovaný například prostřednictvím konceptuálního modelu databáze. Proto je nutné jasně rozlišovat, které vlastnosti, funkce a role uvažovaných entit máme na mysli v konkrétním případě. Rozhodnutí je plně v gesci agenta a není zdaleka triviální. Cílem fasetové kategorizace, navržené v této části, je napomoci v tomto rozhodování pomocí metody, jež umožňuje stanovit rozdíly mezi jednotlivými typy a zároveň neztratit ze zřetele to, co je jim společné.
2 Pojmový model
Nejvýznamnějšími a zároveň nejsložitějšími typy modelů, jež jsou relevantní pro informační vědu, jsou bezesporu pojmové modely. První obtíž přináší už jejich pojmenování, které připouští dvojí interpretaci a navozuje otázku, je-li pojmový model modelem pojmů nebo modelem z pojmů8. Dosavadní literatura zaměřená na teorii pojmových modelů potvrzuje správnost druhé varianty. Druhové rozdíly pro pojmový model, jež ho odlišují od ostatních typů modelů, tvoří obsah fasety ČÍM se modeluje – nástrojem modelování je pojem, zatímco obsah fasety CO se modeluje není ničím omezen. Pojmový model lze tedy jednoduše definovat jako model vytvořený z pojmů.
2.1 Definice pojmu?
Jednoznačné určení pojmu jako základní konstrukční jednotky pojmového modelu vzápětí nastoluje problémy s jeho definováním, což avizuje opětovné použití otazníku v názvu této části. Absence jednotně přijímané definice pojmu má své filozofické základy a pramení z existence různých teorií poznání, jež si nezřídka protiřečí. Hned v úvodu proto upozorníme na to, že naším cílem rozhodně není dospět v tomto článku k jednoznačné definici pojmu, naopak se snažíme zachytit komplexnost problematiky a charakterizovat nejvýznamnější perspektivy zkoumání pojmu, relevantní z pohledu pojmového modelování v informační vědě. Omezíme se na rekapitulaci zásadních tezí a na odkazy na vybrané významné zdroje, jež se věnují analýze pojmu z perspektivy využitelné v informační vědě. Styčné body, na nichž se většina teorií poznání shoduje, lze shrnout do následujících obecných tvrzení:
- Pojem je základní jednotkou myšlení. Je považován za kognitivní model existujících znalostí, umožňující jejich využití k rozpoznání nových objektů nebo událostí.
- Vlastnosti pojmu tvoří dialektická jednota intenze (obsah, nejčastěji stanovený prostřednictvím množiny charakteristik nebo definicí) a extenze (rozsah, množina věcí, jež pojem zahrnuje).
- Proces tvorby pojmu neboli konceptualizace je jednotou (pasivního) odrazu reality a (aktivní) konstrukce významu.
- Proces konceptualizace je založen na abstrakci – zobecňuje a redukuje potenciálně nekonečnou množinu charakteristik skutečnosti a může proto zahrnout více objektů, čímž se přibližuje procesu kategorizace. Extenzí kategorie je množina věcí, považovaných z určitého pohledu nebo pro daný účel za ekvivalentní.
Podrobný přehled dosavadních výzkumů v této oblasti z pohledu kognitivní lingvistiky podává George Lakoff (2006), který sám zformuloval teorii tzv. idealizovaných kognitivních modelů. Lakoff staví do protikladu „tradiční“ aristotelskou teorii tvorby pojmů, založenou na společných vlastnostech zahrnutých objektů, a výsledky empirických výzkumů lidského myšlení v průběhu 20. století. Vyzdvihuje především teorii prototypů Eleanor Roschové a princip tzv. rodinných podobností, zformulovaný Ludwigem Wittgensteinem. Vhodným doplňkem k Lakoffovu textu, zaměřenému na humánní kognici, je interdisciplinární studie Josepha Goguena (2005) zaměřena na metody strojového vytváření pojmů, postavené na matematických základech (jedním z uváděných příkladů je formální konceptuální analýza), a na jejich aplikace v informatice, umělé inteligenci a reprezentaci znalostí. Strojové metody pojmové tvorby abstrahují od „lidské“ stránky procesu, jež je příčinou nejednoznačnosti a nestability významu a nejasných vztahů mezi pojmem a jeho vyjádřením. „Pojem pojmu“ v detailní historické retrospektivě a se zřetelem na kontext informační vědy rozebírá Alberto Marradi (2012). Zkoumání pojmů v rámci teorie poznání zahrnuje i problematiku reprezentace jejich obsahu. Toto téma zpracovala Elaine Svenoniová (2004) ve studii věnované epistemologickým (tj. kognitivním) základům reprezentace znalostí. Oproti obvyklému chápání reprezentace znalostí jako disciplíny umělé inteligence uplatňuje rozšířený pohled, který se neomezuje na otázky zprostředkování znalostí strojům. Podává přehled tří teorií významu, jež dominovaly ve filozofii dvacátého století: operacionalismu, referenční neboli zobrazovací teorie a kontextové/instrumentální teorie významu. Operacionalismus vychází z teorie logického pozitivismu a pojmy definuje procedurálně, pomocí zobecnění empirických údajů. Referenční teorii se budeme věnovat blíže v části 2.2. Instrumentální teorie významu určuje smysl pojmů v rámci jejich využívání v konkrétním kontextu. E. Svenoniová pohlíží na tyto teorie z hlediska jejich aplikace v procesech zpracování a vyhledávání informací. Pro jejich srovnání používá kritéria relevantní pro informační vědu: validita reprezentace znalostí, podpora funkcí kolokace, odlišení a navigace, vhodnost k automatizaci a možnosti sémantické inter-operability.
2.2 Pojmový model v sémiotickém trojúhelníku
Skutečnost, že základní stavební jednotkou pojmových modelů je pojem, který je nutné vyjádřit nějakým znakem, vybízí k aplikaci poznatkového aparátu sémiotiky. Pro účely tohoto textu použijeme obecně přijímaný referenční triadický koncept znaku, znázorňovaný tradičně prostřednictvím sémiotického trojúhelníku. V naší pracovní interpretaci sémiotického trojúhelníku na obrázku 2 jsou pro tři základní aspekty znaku použity termíny věc, pojem a označení. Vztah pojmu a věci, jež je jeho extenzí, je označen jako konceptualizace, tj. pojmové zpracování myšlenkové představy o významu skutečnosti. Vztah pojmu a jeho označení je pojmenován jako vyjádření. Vztah reference neboli odkazu směřující od označení k věci je chápán jako nepřímý, zprostředkovaný pojmovou reprezentací, a proto je vyznačen tečkovanou čárou. Ve skutečnosti vede cesta odkazu znaku na realitu ve směru označení → pojem → věc.

Obr. 2 Pojem a jeho označení v sémiotickém trojúhelníku
Z perspektivy modelové tvorby lze konstatovat, že pojem v sémiotickém trojúhelníku reprezentuje/modeluje věc a označení reprezentuje/modeluje pojem. Vrchol sémiotického trojúhelníku označený jako věc tedy zahrnuje obsah fasety CO se modeluje. Vyjadřuje, že předmětem/originálem pojmového modelu se může stát cokoli, tj. je možné (ale ne nutné), aby pojmový model modeloval i pojmy nebo jejich označení. Tak například terminologické slovníky nebo tezaury lze chápat jako pojmové modely jazykových výrazů – v mezinárodní normě ISO 704 věnované principům a metodám terminologické práce se přímo hovoří o analýze a „modelování pojmových systémů na základě identifikovaných pojmů a jejich vztahů“ (ISO 704:2009, s. v).
2.3 Jazyky pro vyjádření pojmového modelu
Jak bylo konstatováno, pojmový model je model věcí tvořený pojmy. Pojem je ovšem nesdělitelný (implicitní, tacitní), pro komunikaci a manipulaci je třeba vyjádřit jej nějakým jazykem. Formátem pojmového modelu je tedy nějaký modelovací jazyk.
V systémovém pohledu lze jazyk definovat jako jednotu struktury (tj. prvků jazyka a jejich vzájemných vztahů) a funkce. Pro naše účely se omezíme na referenční funkci a následující strukturní prvky jazyka: slovník, pravidla, paradigmatické a syntagmatické vztahy. Jazyky používané pro vyjádření pojmových modelů představují co do komplexnosti své struktury a funkce široké spektrum, jehož začátek je možné spatřovat už na úrovni znakových formátů (např. Unicode) a pokračování v podobě jazyků vyjadřujících syntaxi o různé granularitě a nejrůznějšími technikami či formáty (např. HTML, XML, RDF, JPEG, PNG, PostScript, SVG). My se zaměříme na jazyky sémantické, které umožňují vyjádřit obsah pojmů a jejich vztahů v pojmových modelech. Ty tvoří v současnosti již značně rozsáhlou skupinu, kterou lze členit podle různých hledisek, například podle granularity, tj. „velikosti“ jednotky zachycovaného obsahu, podle modelovaných entit, podle stupně formalizace nebo podle formy vyjádření obsahu modelu.
Z hlediska granularity připomeneme alespoň členění jazyků do skupin určených pro modelování obsahu na úrovni celého dokumentu nebo dokonce na úrovni kolekce dokumentů, tzv. makroindexaci (například MDT), a jazyky umožňující tzv. mikroindexaci na úrovni jednotek obsahu spočívající například v tvorbě výroků tvořících obsah znalostních bází či dokonce jednotlivých hesel věcných rejstříků publikací.
Podle modelovaných entit (obsah fasety CO se modeluje) lze rozlišovat jazyky specializované na modelování softwarových aplikací (např. ER, UML, SQL Schema, BPMN), jazyky vyjadřující struktury elektronických dokumentů (např. DTD, XML Sche ma), jazyky pro sémantický web, webové zdroje a služby (např. RDFS, OWL, SKOS), případně pro modelování objektů v aplikacích umělé inteligence (např. KIF, Topic maps).
Při uplatnění hlediska stupně formalizace lze konstatovat, že jazyky pro vyjádření sémantiky pojmových modelů tvoří plynulou škálu od neformalizovaných k formalizovaným. Na této plynulé škále lze rozpoznat pomyslné hranice oddělující tyto typy jazyků: zcela neformální přirozený jazyk, částečně formalizovaný přirozený jazyk (například jazyky s řízeným slovníkem nebo tzv. speciální jazyky zahrnující odborné názvosloví neboli terminologii), formalizovaný umělý jazyk (např. ER, BPMN, SQL Schema, XML Schema, RDFS, OWL, UML) a konečně rigorózně formální jazyk logiky (k nejčastěji používaným patří jazyky výrokové, predikátové a deskripční logiky).
Podle formy vyjádření obsahu pojmového modelu lze rozlišovat mezi jazyky textovými (slovními, číselnými) a jazyky obrazovými, které se používají pro vyjádření prostřednictvím statických obrazů či videa. Zcela neformálním způsobem textového vyjádření je volný text zapsaný v některém z přirozených jazyků. Nástroji formálního textového vyjádření hierarchické struktury elektronických dokumentů jsou jazyky DTD (Document type definition) a XML Schema. Pro textové modelování slovníků v prostředí sémantického webu se používají jazyky RDFS, SKOS a OWL. Základem většiny obrazových jazyků jsou sémantické sítě, tj. znázornění (vizualizace) sémantických vztahů ve formě grafu. Za první použití sémantických sítí pro reprezentaci pojmů jsou považovány existenční grafy Charlese Sanderse Peirce. Specifickou aplikací sémantické sítě jsou například modely vyjadřované prostřednictvím diagramů v jazyce ER nebo UML, které v současnosti představují nejvýznamnější formální jazyky pro vyjádření pojmových modelů v grafické podobě. ER je jazyk entitně-relačních modelů (odvozeno z angl. entity-relationship model/diagram, v českém překladu model/diagram entit a vztahů), označovaný též zkratkou E-R nebo ERA (z angl. entity-relationship-attribute, v českém překladu entita-vztah-atribut). Používá se od 70. let 20. století především pro návrh modelů relačních databází, klasickou variantu představuje původní návrh Petera Chena (1976). UML (Unified Modeling Language – unifikovaný modelovací jazyk) je od 90. let 20. století standardem pro reprezentaci objektově orientovaných modelů (OMG, 1997). Původně byl navržený pro modelování objektově orientovaných softwarových aplikací, jeho oblast působnosti se postupně rozšířila i do dalších oborů. Zajímavým příkladem v tomto směru je norma ISO 24156-1, která specifikuje aplikační profil UML pro využití jeho grafické notace v terminologické práci (ISO 24156-1:2014).
Stejně jako jazyk zpětně ovlivňuje myšlení, je i volba jazyka pro vyjádření pojmového modelu schopna ovlivnit jeho smysl. Tak volba jazyka UML či RDF zpravidla vede k uplatnění objektově orientovaného paradigmatu v modelu a jazyk ER modelů směřuje k orientaci na jejich implementaci v relačních databázích.
2.4 Funkce pojmového modelu
Pro specifikaci funkcí pojmového modelu využijeme výše uvedené komponenty sémiotického trojúhelníku věc a označení. Místo jednotlivého pojmu pak budeme uvažovat jejich systém, tj. množinu pojmů spjatých vzájemnými vztahy, jež tvoří pojmový model. Na obrázku 3 je znázorněno pět funkcí pojmových modelů, které jsou výběrem typů, jež považujeme za relevantní z pohledu informační vědy. Funkce označené písmeny a – e jsou znázorněné šipkami, jež představují zpracovatelské procesy a směřují od zdrojové entity k cílové entitě, která je její transformací. Každá funkce je popsána strukturovaným způsobem – je charakterizován daný zpracovatelský proces a jsou uvedeny konkrétní příklady zdrojových a cílových entit.

Obr. 3 Funkce pojmového modelu
(a) Tvorba pojmového modelu reality
Charakteristika procesu: konceptualizace, tj. tvorba pojmového modelu skutečnosti.
Zdrojová entita procesu: věc ve funkci originálu; rozsah této entity není omezen, modelovat lze cokoli pozorovatelného či myslitelného.
Výsledek (výstup) procesu: deskriptivní pojmový model vyjadřující obsah, smysl, význam skutečnosti. Příklady: doménová ontologie, systém organizace znalostí, model databáze.
(b) Tvorba pojmového modelu vyjadřujícího obsah znaku
Charakteristika procesu: interpretace smyslu označení jako specifický případ konceptua-lizace. Základem konceptualizace v tomto případě je obsahová analýza informačních zdrojů. Její specifika spočívají v tom, že se neprovádí analýza věci, ale interpretuje se význam textu/znaku. V textech informační vědy se pro tento proces používá termín indexace; norma ISO 5963 definuje indexaci jako „pracovní postup popisování nebo identifikace dokumentu ve vztahu na jeho věcný obsah“ (ČSN ISO 5963, 1995, s. 5).
Zdrojová entita procesu: označení ve funkci originálu; možné typy jazyků pro tvorbu označení byly charakterizovány v části 2.3.
Výsledek (výstup) procesu: deskriptivní pojmový model jako výsledek obsahové analýzy označení (textu, dokumentu, informačního zdroje), v angličtině označovaný jako about ness (Kučerová, 2014). Příklady: metadata, selekční obraz dokumentu, redukovaný text (např. abstrakt).
(c) Tvorba artefaktu podle pojmového modelu
Charakteristika procesu: vytvoření nebo modifikace originálu podle modelu, například katalogizace (tvorba katalogizačního záznamu) podle pravidel RDA nebo tvorba databáze podle konceptuálního schématu.
Zdrojová entita procesu: preskriptivní pojmový model, například katalogizační pravidla RDA, konceptuální schéma databáze.
Výsledek (výstup) procesu: věc ve funkci originálu – artefakt, vytvořený podle modelu. Příklady: záznam v katalogu, databázová tabulka.
(d) Tvorba znaků jako implementace pojmového modelu
Charakteristika procesu: vyjádření obsahu modelu prostřednictvím nějakého jazyka, případně jeho formalizace podle dohodnutých pravidel.
Zdrojová entita procesu: pojmový model ve funkci originálu.
Výsledek (výstup) procesu: označení – pojmový model vyjádřený v dohodnutém jazykovém systému. Z existence velkého množství modelovacích jazyků (viz část 2.3) vyplývá možnost implementovat jeden model různými způsoby ve více jazycích. Příklady: databázové schéma vyjádřené pomocí ER diagramu nebo diagramu tříd v UML, doménová ontologie vyjádřená v jazycích HTML, RDF nebo OWL, systém organizace znalostí (např. tezaurus) vyjádřený graficky v podobě sémantické sítě nebo textově v jazyce SKOS.
(e) Tvorba modelu podle modelu
Tento poněkud anekdoticky znějící název označuje proces, v jehož průběhu je vytvářen nový model s využitím existujícího modelu.
Charakteristika procesu: úprava (opětovné použití, modifikace, transformace) původního modelu a vytvoření nového modelu.
Zdrojová entita procesu: pojmový model, například soubor metadatových prvků Dublin Core.
Výsledek (výstup) procesu: pojmový model odvozený z již existujícího modelu. Příklady: aplikační profil vytvořený podle Pravidel pro aplikační profily Dublin Core (Coyle a Baker, 2009), aplikační profil UML, pojmový model nebo doménová ontologie vytvořené s využitím základní ontologie nebo návrhových vzorů.
2.5 Procesy tvorby pojmového modelu
Pro pochopení specifik pojmových modelů je vhodné zaměřit se i na procesní pohled. Rámcový postup při pojmovém modelování je znázorněn na obrázku 4. Tvoří ho tři na sebe navazující fáze: tvorba subjektivního modelu a tvorba objektivního modelu, která se člení na podprocesy vyjádření subjektivního modelu a fyzické realizace modelu. Modely vytvořené v první fázi jsou označené číslem 1, model vytvořený v druhé fázi má označení 2.1 a model vytvořený ve třetí fázi je označen číslem 2.2.
Pro názorné odlišení jednotlivých fází využijeme teze o objektivních znalostech a metaforu tří světů, jež ve své teorii poznání zformuloval Karl Raimund Popper. Jejich vhodnost pro aplikaci v informační vědě lze spatřovat v tom, že řeší nejen problematiku poznání v lidské mysli, ale především podrobně rozpracovávají problematiku poznání zaznamenaného v externích pamětech. Popper razí tezi o dvou typech znalostí – subjektivních a objektivních. Subjektivní znalost je podle něj ta, již vlastní nějaký subjekt; představuje ji stav mysli nebo vědomí či dispozice jednat nebo reagovat. Jako objektivní znalost označuje „znalost v objektivním smyslu, jež sestává z logického obsahu našich teorií, hypotéz, dohadů“ (Popper, 1979, s. 73). „Znalost v tomto objektivním smyslu je totálně nezávislá na tom, co kdokoli tvrdí, že ví, je též nezávislá na přesvědčení kohokoli. Znalost v objektivním smyslu je zna lost bez toho, kdo zná (je to znalost bez poznávajícího subjektu).“ (Popper, 1979, s. 109) Popperova teorie tří relativně autonomních světů vychází z filozofie Bernarda Bolzana a Gottloba Fregeho. Člení objektivní realitu na svět 1 – fyzický svět hmoty a energie, svět 2 – svět lidského vědomí (stavy vědomí, subjektivní znalosti) a svět 3, což je svět řeči – abstraktní svět obsahu vědomí a výtvorů lidského ducha (objektivní znalosti). Mezi světy 1, 2 a 3 existují hranice, jež jsou zároveň místy vzájemné interakce. Přímá interakce mezi světem 1 a světem 3 však podle Poppera není možná, je uskutečnitelná jen prostřednictvím světa 2. Svět 3 je lidským výtvorem, tj. artefaktem, který je produktem světa 2.
Na obrázku 4 je vyznačeno, že modely vytvořené v první fázi spadají do Popperova světa 2 a modely vytvořené v následujících dvou fázích patří do Popperova světa 3. Zhmotněný model, vytvořený ve fázi 2.2, obsahuje už samozřejmě prvky fyzického světa 1.

Obr. 4 Fáze tvorby modelu
Fáze 1 – tvorba subjektivního modelu
Subjektivní model se vytváří v průběhu myšlení. Označuje se též jako implicitní, tacitní, mentální, kognitivní model či reprezentace nebo pojmová struktura (angl. conceptual structure). Podle George Lakoffa „kognitivní mo dely strukturují myšlení a používají se při formování kategorií a uvažování“ (Lakoff, 2006, s. 26). Subjektivní modely zkoumá psychologie, kognitivní věda a umělá inteligence s cílem poznat a vysvětlit podstatu lidského myšlení. V rámci výzkumu principů lidského myšlení se vyprofilovalo více alternativních představ, z nichž mnohé považují modelování za základní proces či dokonce způsob lidského myšlení. Podrobný přehled této problematiky z pohledu kognitivní psychologie podává Miluše Sedláková (2004).
Z hlediska účelu bude vhodné rozlišit dva typy subjektivních modelů. Prvním typem je implicitní model vytvářený jednotlivcem pro jeho vlastní potřebu, který se obvykle označuje jako mentální model. Druhý typ, který nemá své specifické označení, nazveme pracovně jako subjektivní pojmový model. Jedná se rovněž o implicitní model vytvářený jednotlivcem, tentokrát ovšem se záměrem model vyjádřit a komunikovat.
Mentální model se vytváří podvědomě, intuitivně a je považován za složku dlouhodobé paměti. Vytváří jej jednotlivec sám pro sebe a používá ho k pochopení světa nebo k řešení problémů. Případná externalizace mentálních modelů není záměrem jejich tvůrců, ale výzkumníků, kteří k jejich zjištění používají různé metody.
V informatice se mentální modely studují především v kontextu interakce uživatele a informačního systému či aplikace. Nejčastěji je předmětem zájmu mentální model fungování systému, který si vytváří jeho koncový uživatel. Obvyklou hypotézou je, že pokud bude informační systém odpovídat mentálnímu modelu uživatele, bude jím ochotně přijímán a interakce uživatel – informační systém bude úspěšná.
Informační věda se zajímá o mentální modely rovněž při zkoumání interakce uživatele s informačním systémem a zejména v rámci výzkumu uživatelského chování. Přehled četných výzkumů na toto téma podávají například David Bawden a Lyn Robinsonová (2017, s. 251–277). Zajímavým příkladem je výzkum provedený v rámci historicky prvního uživatelského testování modelu FRBR, jehož výsledky byly publikovány v roce 2010 (Pisanski a Žumer, 2010a, 2010b). Cílem byla elicitace (tj. zjištění a explicitní vyjádření) interních subjektivních mentálních modelů bibliografického univerza a následné zjištění, zda mentální modely uživatelů bibliografických informací jsou kompatibilní s modelem FRBR. Během výzkumu byly použity techniky třídění kartiček, pojmového mapování (tj. reprezentace znalostí formou diagramu) a komparace s výsledky řízených rozhovorů.
Druhý typ modelu, pro nějž používáme pracovní označení subjektivní pojmový model, vytváří ve své mysli jednotlivec vědomě se záměrem transformovat jej v objektivní, explicitní model, který hodlá s někým sdílet. Subjektivní pojmový model se v lidské mysli vytváří jako nutný předstupeň pro to, aby mohl být vyjádřen v podobě objektivního modelu. Jeho podstatou je konceptualizace a kategorizace, tj. tvorba pojmů a pojmových systémů. Účelem tohoto typu modelu je tedy tvorba objektivního modelu, je vytvářen pro účely své externalizace a sdílení (tj. komunikace).
Fáze 2 – tvorba objektivního modelu
Jak je na obrázku 4 znázorněno, tvorba objektivního modelu se člení na dvě dílčí fáze: explicitní vyjádření subjektivního modelu a fyzickou realizaci modelu.
Fáze 2.1 – vyjádření subjektivního modelu
Tento model je abstraktní. Je vyjádřený nějakým jazykem, tj. reprezentovaný. Umožňuje komunikaci sémantiky subjektivního modelu ve smyslu sdílení, případně přenosu v prostoru, ovšem už nikoli uchování modelu v čase nebo fyzickou manipulaci s ním.9 Tyto aktivity jsou možné až po uskutečnění následující fáze spočívající ve fyzické realizaci modelu.
Jedním ze způsobů externalizace mentálních modelů je popis rozpoznaných vzorců chování, v němž se interní mentální modely projevují. Standardní metodou externalizace subjektivních pojmových modelů jsou sémantické sítě (jazyky pro jejich vyjádření byly charakterizovány v části 2.3).
Fáze 2.2 – zhmotnění modelu
Výsledkem této fáze je konkrétní model, typicky vytvořený zachycením sémantiky modelu vyjádřené v nějakém jazyce na hmotném nosiči. Pro materializaci pojmového modelu může být zvolen nosič jak analogový, tak digitální (např. papír, mikrofilm, flash disk)10. Konkrétní model umožňuje kromě komunikace v čase přímou manipulaci, například provedení experimentu s modelem nebo jeho fyzickou organizaci umístěním.
3 Přehled pojmových modelů relevantních pro informační vědu
Pro přehled pojmových modelů relevantních pro informační vědu použijeme vlastní pracovní typologii založenou na obsahu fasety CO se modeluje. Níže uvedený přehled v tabulce 2 zahajují univerzální sémantické modely ve formě základních ontologií. Následují sémantické modely omezené na konkrétní oblast zájmu – doménové ontologie a referenční pojmové modely. Další skupinou jsou modely metadat. Ty jsou nejprve rozděleny na skupinu statických a dynamických modelů, statické modely jsou dále členěny na soubory metadatových prvků a metadatová schémata a na slovníky hodnot. Přehled uzavírají modely entit v informačním systému nebo v softwarové aplikaci, tj. pojmová/konceptuální schémata a datové modely. Konstatovaný vliv pojmového modelování v informatice na teorii a zejména na praxi modelování v oblastech zkoumaných informační vědou je demonstrován začleněním „vlastních“ pojmových modelů informační vědy, jež jsou uvedeny ve zvýrazněné centrální části tabulky, do kontextu modelů informatických. Tento kontext tvoří na nejobecnější úrovni základní ontologie a naopak na úrovni konkrétní pojmová/konceptuální schémata a datové modely.
Tab. 2 Typologie pojmových modelů relevantních pro informační vědu

3.1 Pojmové modely v informatice a jejich terminologie
Protože teorie pojmového modelování zformovaná v rámci oboru informatiky představuje klíčový zdroj pro informační vědu, považujeme za vhodné uvést její rámcovou charakteristiku, vzhledem k bohaté existující literatuře na toto téma se však omezíme pouze na stručné shrnutí, zaměřené především na používanou terminologii. Zájemce o historický přehled výzkumů pojmového modelování v informatice lze odkázat například na přehledové studie, které zpracovali Janis A. Bubenko (2007) nebo Nick Roussopoulos a Dimitris Karagiannis (2009). K významným autorům a teoretikům pojmových modelů v informatice patří autor koncepce entitně relačního modelování dat Peter Chen, představitel skandinávské školy konceptuálního modelování Arne Sølvberg, autor významného databázového modelu Telos John Mylopoulos a německý teoretik pojmového modelování Bernhard Thalheim.
V množství publikovaných textů lze samozřejmě zaznamenat rozdílná pojetí. Převažuje ovšem chápání pojmových modelů jako artefaktů reprezentujících znalosti o entitách relevantních pro informační systém, jež jsou určeny lidem. Tím se pojmové modelování liší od reprezentace znalostí, která je určena strojům. Problémy řešené teorií pojmových modelů v informatice lze shrnout do dvou základních okruhů. První okruh hledá odpověď na otázku, co se modeluje – zda objekty v realitě nebo objekty v informačním systému/aplikaci. Druhý okruh problémů zahrnuje řešení automatickéhopřevodu pojmového modelu na softwarový artefakt či aplikaci (tzv. dopředné inženýrství) a naopak (tzv. reverzní inženýrství).11 V souladu s inženýrským charakterem disciplíny se informatici zaměřují především na preskriptivní modely. Snaha vytvořit teoretické základy pro pojmové modely v informatice dovedla některé autory až k filozofickým kořenům modelování. Například Yair Wand a Ron Weber (1990, s. 63) zvolili jako základ pro svoji teorii pojmových modelů informačních systémů ontologii filozofa Maria Bungeho.
Aktuální etapa vývoje informačních technologií vnesla do problematiky pojmového modelování tematiku ontologií, které z původní oblasti svého využití v systémech umělé inteligence rychle pronikají i do dalších oblastí včetně knihovnictví a informační vědy. Ontologie jsou vysoce aktuálním a závažným tématem, jehož detailnímu rozboru by však bylo třeba věnovat samostatnou studii. V tomto textu se omezíme na stručnou charakteristiku ontologie jako specifického typu pojmového modelu, jehož účelem je komunikace, opakované využití a organizace znalostí, popis skutečnosti pro počítačové zpracování a automatické odvozování znalostí. Obsah tvoří třídy, jejichž význam je vymezen pomocí axiomů. Výběr tříd, jejich vlastností a způsob strukturování ontologie je založen na implicitně či explicitně stanovených ontologických závazcích.
Z četných možností členění ontologií je pro naše účely relevantní typologie vytvořená podle toho, jak je vymezena množina jimi reprezentovaných entit, tedy podle obsahu fasety CO se modeluje. Na základě tohoto kritéria lze ontologie členit na obecné (též univerzální, angl. generic) a doménové (angl. domain). Obecné ontologie jsou všeobecně zaměřené, doménově nezávislé a co do rozsahu neohraničené. Specifickým typem obecných ontologií jsou základní (angl. foundational) ontologie, jejichž účelem je sloužit jako výchozí bod pro tvorbu nových doménových ontologií. Obsahují vícenásobně použitelné entity, obvykle základní kategorie na nejvyšší úrovni obecnosti, a někdy i návrhové vzory. Doménové ontologie se omezují na konkrétní oblast, vymezenou tematicky, ale i problémově – například je možné rozlišovat mezi ontologiemi orientovanými na deskriptivní a na procedurální znalosti. Jak bude ukázáno v části 3.2, v současnosti je již možné se setkat s doménovými ontologiemi i v oblasti paměťových a fondových institucí.
Terminologická báze pojmového modelování v informatice byla už v roce 1987 zachycena a standardizována na úrovni technické zprávy ISO/TR 9007 a je dále rozvíjena mezinárodním konsorciem OMG (Object Management Group), jež bylo založeno v roce 1989. OMG sdružuje přibližně 300 technologických, výzkumných a konzultačních organizací a věnuje se standardizaci objektově orientovaných nástrojů a metodik.
Norma ISO/TR 9007 (ISO/TR 9007:1987) definuje dvě roviny modelování skutečnosti v informačních systémech: obsahovou rovinu (tj. intenzi) zachycuje pojmové schéma, zatímco rozsah (tj. extenzi) zachycuje datová základna. Pojmové schéma popisuje sémantiku dat a datová základna je chápána jako datový model reality. Kromě těchto modelů norma definuje ještě dva další typy – tzv. vnější schéma (systém, jak jej vidí uživatel, tj. model vnějšího rozhraní mezi uživatelem a informačním systémem) a vnitřní schéma, popisující technologii fyzického uložení dat v systému a manipulaci s nimi (tj. model rozhraní mezi informačním systémem a použitými prostředky uložení dat).
Aktuální implementací principu pojmového modelování v návrhu informačních systémů a softwarových aplikací je od roku 2001 specifikace MDA – Model driven archi tecture (Architektura řízená modelem) (OMG, 2014). Jejím cílem je standardizace typů modelů společných pro většinu systémů a automatizovaná transformace různých úrovní modelů v obou směrech (tj. dopředné i zpětné inženýrství). Koncepce architektury informačních systémů a softwarových aplikací podle MDA zahrnuje tři typy postupně konkretizovaných modelů, reprezentujících úrovně jejich popisu.
Na nejobecnější úrovni je definován pojmový model nezávislý na počítačovém zpracování (CIM – Computation Independent Model), zachycující popis oblasti použití systému, například model podnikových procesů. Protože jádrem tohoto modelu je obvykle slovník vymezující význam pojmů v aplikační doméně a pravidla stanovená pro průběh podnikových procesů, lze při tvorbě tohoto modelu využít další ze standardů OMG – Semantics of Business Vocabulary and Business Rules (SBVR – volně přeloženo Sémantika slovníku a pravidel podnikového byznysu) (OMG, 2017). SBVR lze považovat za vysoce zobecněný metajazyk umožňující vyjádřit standardizovaným způsobem model byznysu. Jednou z oblastí jeho využití je transformace do modelu informačního systému. Přínosem SBVR je, že se zaměřuje jak na popis statické struktury prostřednictvím slovníku, tak na popis dynamické struktury podnikových procesů prostřednictvím formalizovaného modelu jejich pravidel. Představuje tak určitou paralelu k aktuálním snahám o formalizaci katalogizačních pravidel RDA a možnou inspiraci pro jejich další směřování.
Další dva modely se liší svou závislostí na platformě, přičemž za platformu je v MDA považována množina zdrojů, na nichž je počítačový systém realizován a jež se používá k implementaci nebo k podpoře systému. Pojmový model nezávislý na platformě (PIM – Platform Independent Model) představuje pojmový model reality reprezentované informačním systémem na sémantické úrovni, bez údajů o jejich implementaci v konkrétním počítačovém prostředí. Model pro specifickou platformu (PSM – Platform Specific Mo del) již modeluje objekty v konkrétním informačním systému či aplikaci.
Tři typy modelů definované specifikací MDA zhruba odpovídají následujícím typům pojmových modelů, pracovně vymezeným v tabulce 2: model CIM má charakter doménové ontologie, model PIM odpovídá pojmovému schématu podle ISO/TR 9007 a model PSM, jenž odpovídá vnitřnímu schématu informačního systému podle ISO/TR 9007, představuje datový model.
V souvislosti s pojmovými modely v informatice je vhodné poukázat na specifika používané terminologie. S určitým zjednodušením lze konstatovat, že pro sémantické modely reality se v angličtině používá označení conceptual model/schema a modely dat v informačním systému se označují jako data model/database schema. České ekvivalenty pro modely dat se vcelku bezproblémově vžily v podobě termínů datový model a databázové schéma. V případě českých ekvivalentů pro anglické termíny conceptual model a conceptual schema však lze zaznamenat jistou dvoukolejnost. V českém překladu normy ISO/TR 9007, který byl publikován v roce 1995, se používá termín pojmové schéma (ČSN ISO TR 9007, 1995). V průběhu následujících let se však v rámci české komunity informatiků zřejmě pod vlivem zdrojů v angličtině ustálilo používání anglicismů konceptuální model/schéma. Tyto anglicismy začínají zpětně pronikat z původní oblasti použití, kterou je modelování databázových a informačních systémů, i do oblastí pojmového modelování v informační vědě. Jak ale bude ukázáno v následující části, pojmové modely v informační vědě mají svá vlastní specifika a podstatně se liší od konceptuá-lních modelů a schémat informatiky. Považujeme proto za vhodné omezit používání termínů konceptuální model/schéma pouze na přesně vymezenou oblast, v níž vznikly, a modely v oblasti zájmu informační vědy označovat jako pojmové modely.
3.2 Pojmové modely informační vědy
I paměťové a fondové instituce mají samozřejmě své provozní a administrativní systémy, jejichž pojmové modely je žádoucí postavit na teoretických základech zformulovaných informatikou. Avšak stejně jako je informatická teorie pojmových modelů přizpůsobena specifikům modelování v informatice, je zapotřebí zaměřit teorii pojmových modelů v informační vědě na specifické předměty jejího zkoumání, kterými jsou informační zdroje a procesy komunikačního řetězce, mezi nimiž hraje významnou roli proces obsahové analýzy a indexace informačních zdrojů. Prvním počinem v tomto směru se stal model FRBR. Původně byl označovaný jako model určený pro návrháře knihovních informačních systémů, nyní je v konsolidované verzi IFLA LRM prohlášen za pojmový model bibliografického univerza a představuje významný podnět k rozvoji teoretického myšlení v informační vědě pro 21. století.
V následujících třech částech se zaměříme na tři typy pojmových modelů v informační vědě: referenční pojmové modely, modely metadat a systémy organizace znalostí a jejich pojmové modely.
3.2.1 Referenční pojmové modely
Označení „referenční“ se používá pro modely na nejvyšší úrovni abstrakce, které se soustřeďují na explicitní zachycení sémantiky příslušné oblasti. Lze konstatovat, že modely tohoto typu spadají do kategorie doménových ontologií, resp. tvoří jejich zvláštní skupinu. Nejsou určeny k přímé implementaci v informačních systémech, ale představují pojmovou základnu pro všechny další specifické modely a normativní dokumenty v rámci svých domén. Tento rys je přibližuje i kategorii základních ontologií. Typickým příkladem referenčního modelu je model otevřeného archivačního informačního systému, který je k dispozici v českém překladu z roku 2014 (ČSN ISO 14721, 2014).
Nejvýznamnějšími referenčními pojmovými modely, jež zachycují entity v oblasti zájmu informační vědy, jsou pojmový model bibliografických informací IFLA LRM (Library reference model)12 a pojmový model informací o kulturním dědictví CIDOC CRM (CIDOC Conceptual reference model, Pojmový referenční model CIDOC). Díky vysoké míře formalizace a zahrnutí obecných pojmů pro vyjádření časoprostorových charakteristik a abstraktních pojmů lze o obou modelech prohlásit, že mají rovněž rysy základní ontologie.
Referenční pojmový model IFLA LRM (IFLA, 2017), jehož doména je obecně vymezena jako bibliografické univerzum, je důležitým příspěvkem k tvorbě doménové ontologie pro oblast knihoven. Specifikace modelu byla v roce 2017 přijata jako standard IFLA, který plně nahrazuje pojmové modely FRBR (Funkční požadavky na bibliografické záznamy), FRAD (Funkční požadavky na autoritní data) a FRSAD (Funkční požadavky na věcné autority).
Účelem modelu IFLA LRM je poskytnout rámec pro analýzu logické struktury informací vztahujících se ke knihovním zdrojům z pohledu jejich uživatelů. Stejně jako modely rodiny FRBR modeluje IFLA LRM informace tradičně označované jako bibliografické a autoritní údaje, nezaměřuje se na údaje administrativní a provozní. Jazykem pro vyjádření pojmového modelu IFLA LRM je jazyk entitně-relačních modelů, který byl použit už v modelu FRBR. Tentokrát je ovšem tento jazyk použit v rozšířené verzi EER (z angl. enhanced entity-relationship model/diagram, česky rozšířený ER model/diagram), jež umožňuje modelovat i hierarchické vztahy zobecnění a specializace a s tím související dědičnost atributů a vztahů. Tento rys přibližuje zvolenou metodiku metodám založeným na objektově orientovaném přístupu.
V rámci modelu je definováno 11 entit propojených hierarchickými a asociativními vztahy. Na nejvyšší úrovni hierarchie se nachází entita res (z lat. označení pro věc), zahrnující všechny entity v rámci bibliografického univerza. Podtřídami entity res jsou dílo (angl. work), vyjádření (angl. expression), provedení (angl. manifestation), jednotka (angl. item), agent (angl. agent) s podtřídami osoba (angl. person) a kolektivní agent (angl. collective agent), nomen (z lat. označení pro jméno), místo (angl. place) a časové rozpětí (angl. time-span).
Referenční pojmový model CIDOC CRM byl vytvořen Mezinárodním výborem pro dokumentaci Mezinárodní rady muzeí ICOM (ICOM‘s International Committee for Docu mentation, CIDOC) jako doménová ontologie pro výměnu informací o kulturním dědictví (ICOM/CIDOC Special Interest Group, 2003). Na rozdíl od modelu IFLA LRM je CIDOC CRM už od své první verze z roku 1996 založen na objektově orientovaném přístupu. Aktuální verze 6.2.3 zahrnuje 82 tříd a 262 predikátů. Na vrcholu hierarchie je třída nazvaná CRM entita (angl. CRM entity), jež zahrnuje pět vrcholových tříd: dočasnou entitu (angl. temporal entity), trvalou položku (angl. persistent item), časové rozpětí (angl. time-span), místo (angl. place) a rozměr (angl. dimension).
Snahy o sémantickou interoperabilitu referenčních modelů IFLA LRM a CIDOC CRM se projevují nejen na úrovni konzultací a spolupráce odborníků z obou komunit, ale i v podobě návrhu harmonizovaného modelu zahrnujícího entity z obou modelů. Model označovaný jako FRBRoo (IFLA, 2015) byl od roku 2009 k dispozici v postupně se vyvíjejících verzích už pro modely rodiny FRBR. V návaznosti na přijetí modelu IFLA LRM byla v roce 2017 ustavena pracovní skupina LRMoo Working Group, která zahájila revizi FRBRoo a začíná připravovat návrh objektově orientovaného modelu LRMoo (Riva a Žumer, 2018).
3.2.2 Modely metadat
Na rozdíl od referenčních pojmových modelů se u pojmových modelů metadat předpokládá přímé využití jejich obsahu v procesech zpracování informačních zdrojů. Jak uvádí jejich název, předmět modelování se omezuje na specifickou množinu objektů, jimiž jsou metadata.
Termín metadata se začal používat s nástupem digitálních zdrojů, v éře analogových zdrojů se pro takový typ dokumentů používalo označení sekundární dokument. Rovněž termín metadata navzdory svému znění, jež navozuje výklad ve smyslu „data o datech“, případně „informace o informacích“, označuje specifický typ informačního zdroje. Specifikem metadat není jejich forma, ale obsah, který se vždy vztahuje k nějakému informačnímu zdroji. Typickým účelem metadat je náhrada (surogát) zdroje. Často slouží jako odkaz na zdroj, tj. jako přístupový bod, mohou ovšem obsahovat i informace, doplňující obsah zdroje. Ve všech případech jejich využití lze metadata chápat jako reprezentanty, tj. modely informačních zdrojů.
Metadata mohou být fyzickou součástí zdroje (např. tiráž, ex libris, metadata v HTML dokumentu), nebo na něj odkazovat (např. bibliografická citace, katalogizační záznam, URL, deskriptor, třídník MDT). Podle toho, jakého atributu nebo jaké funkce zdroje se týkají, se rozlišují metadata obsahová, identifikační, administrativní a další. Uživatelsky nejvýznamnější jsou metadata umožňující přístup ke zdrojům. V souladu s tím, jaký princip organizace zdrojů byl zvolen, obsahují přístupová metadata buď adresu (lokaci) nebo označení zdroje. Stejně jako ve světě fyzických objektů je tedy modelem fyzického přístupu k organizovaným zdrojům mapa jejich lokací tvořená metadaty v podobě indexu, katalogu či rejstříku. Analogickou ‚mapou‘ označení, resp. modelem sítě jejich vzájemných vztahů, jsou systémy organizace znalostí.
V praxi knihoven a paměťových institucí se využívají jak statické, tak dynamické modely metadat. Existují i případy „hybridních“ modelů, kupříkladu katalogizační pravidla RDA obsahují jak seznam strukturních prvků popisu, tak předepsané postupy při jejich zjišťování a zápisu. Rovněž norma ISO 25964, o níž se blíže zmíníme v části 3.2.3, zachycuje ve svém textu jak statické, tak dynamické aspekty standardizace tezaurů a dalších systémů organizace znalostí.
Výše uvedená možnost pohlížet na metadata jako na model připomíná, že i na metadata lze vztáhnout již konstatovaný problém s rozlišením originálu a modelu. Opět vyvstává otázka, zda (resp. kdy) jsou metadata modelem nebo originálem, a opět se potvrzuje, že pro její zodpovězení je nezbytné provést vícekriteriální fasetovou analýzu. Na obrázku 5 jsou prostřednictvím vztahů polyhierarchie v diagramu UML znázorněny obě možné varianty: metadata jako pojmový model informačního zdroje a metadata jako originál, jehož struktura je modelována pojmovým modelem metadat.

Obr. 5 Metadata jako model a jako originál
Statické modely metadat
Z hlediska jejich sémantické struktury lze metadata považovat za instance vlastností, jejichž základní konstrukční prvky tvoří dvojice atribut-hodnota. Z existence této dvojice jsou pak odvozeny dva základní typy strukturních modelů metadat – modely atributů a modely jejich hodnot. V angličtině se pro jejich pojmenování ustálily termíny metadata element set (soubor metadatových prvků), příp. metadata schema (metadatové schéma) a value vocabulary (slovník hodnot). Používají je mimo jiných Marcia Lei Zengová a Jian Quinová v monografii Metadata (Zeng a Quin, 2016). Rovněž autoři technické zprávy americké Národní organizace pro normy v oblasti informací NISO TR-06-2017, věnované problémům správy slovníků, člení modely metadat relevantní pro oblast bibliografických informací do těchto dvou základních typů (NISO TR-06-2017, 2017, s. 2). Stejnou terminologii uplatňují i katalogizační pravidla RDA.13
Soubory metadatových prvků a metadatová schémata
Soubory metadatových prvků a metadatová schémata představují pojmové modely atributů metadat včetně případného zachycení jejich vztahů. Významným úložištěm pro soubory metadatových prvků ve formátu propojených otevřených dat je Open metadata registry (Registr otevřených metadat), provozovaný neziskovou společností Metadata Management Associates.14 Obsahuje mimo jiných seznam datových prvků Dublin Core, ISBD, MARC21, RDA a UNIMARC.
Slovníky hodnot metadat
Název napovídá, že tyto typy pojmových modelů sestávají z uspořádaných seznamů slov, nejčastěji termínů, označujících pojmy v dané oblasti zájmu. Příkladem mohou být číselníky neboli seznamy termínů a kódů (angl. vocabulary encoding schemes) v rámci pravidel RDA, například seznam hodnot pro pole typ obsahu15, jenž v aktuální podobě obsahuje 23 označení možných hodnot pole 336 z formátu MARC21 (např. kartografický obraz, počítačový program ad.).
Jedním z nejvýznamnějších typů slovníků hodnot metadat jsou soubory odborného názvosloví, zachycující pojmovou základnu příslušného oboru v terminologických slovnících a databázích. Terminologickou základnu informační vědy a oblasti informačních technologií zachycují mezinárodní normy ISO 5127 Information and documentation – Foundation and vocabulary (Informace a dokumentace – základy a slovník)16 a ISO/IEC 2382 Information technology – Vocabulary (Informační tech nologie – slovník)17. Českou terminologii v rozsahu přes 3000 termínů obsahuje Česká terminologická databáze knihovnictví a informační vědy (TDKIV).18 Významným terminologickým zdrojem je vícejazyčný slovník termínů a pojmů z oblasti katalogizace MulDiCat, který slouží jako zdroj pro autoritativní překlady standardů a dokumentů IFLA. Aktuální verze z roku 2012 obsahuje 41 termínů v 26 jazycích včetně češtiny.19
Dynamické modely metadat – pravidla a metody
Procesními modely metadat, jež regulují pracovní postupy jejich tvorby a správy, jsou texty standardů a pravidel. Stěžejní význam pro tvorbu popisných metadat mají Mezinárodní principy katalogizace (International cataloguing principles, ICP) (IFLA, 2016). Na obecných principech katalogizace jsou založena pravidla; v paměťových institucích jsou v současné době nejpoužívanějšími katalogizačními pravidly pro popis a zpřístupňování zdrojů RDA (Resource description and access). Pro metodiku procesu indexace byla v roce 1985 přijata mezinárodní norma ISO 5963 Metody analýzy dokumentů, určování jejich obsahu a výběru lexikálních jednotek selekčního jazyka (ČSN ISO 5963, 1995).
3.2.3 Systémy organizace znalostí a jejich pojmové modely
Systémy organizace znalostí
Specifickými zástupci pojmových modelů metadat jsou systémy organizace znalostí. Představu o počtu používaných systémů organizace znalostí a jejich typech poskytuje zřejmě aktuálně nejreprezentativnější registr BARTOC (Basel Register of Thesauri, Ontologies & Classifications), jenž k 20. 9. 2018 zahrnuje informace o 2857 systémech.20 Příkladem systému organizace znalostí, který se snaží o pojmové pokrytí domény informační vědy, je fasetový Tezaurus ASIST pro informační vědu, techno logii a knihovnictví (ASIS&T thesaurus of information science, technology, and libra rianship), jehož třetí vydání z roku 2005 obsahuje 1970 termínů, členěných do 18 faset s 10 subfasetami. Primárním účelem tezauru je indexace a vyhledávání zdrojů v oborových databázích a digitálních knihovnách (Redmond-Neal a Hlava, 2005).
Zatímco v případě metadat vyvstává problém, zda je chápat jako model nebo jako originál, u systémů organizace znalostí se projevuje nejednoznačnost v tom smyslu, zda je chápat jako metadatové schéma nebo jako slovník metadat. Tomuto významnému problému byla věnovaná samostatná studie (Bratková a Kučerová, 2014) zaměřená na definování systémů organizace znalostí a jejich typologii, na tomto místě uvádíme stručnou rekapitulaci jejích závěrů.
Systém organizace znalostí chápeme jako pomůcku, jejíž funkcí je podpora procesů organizace znalostí a přístupu ke znalostem. Tvoří jej pojmový model struktury (tj. prvků a vzájemných vztahů) metadat, jež se používají k popisu organizovaných zdrojů a při jejich vyhledávání.
Z perspektivy metadatového schématu lze systém organizace znalostí chápat jako model struktury organizované množiny informačních zdrojů. Základními strukturními prvky systému organizace znalostí v tomto pojetí jsou pojmy a jejich vztahy.
Z perspektivy slovníku hodnot metadat je možné pohlížet na systém organizace znalostí jako na slovník, který je formálním vyjádřením pojmů. Tento slovník je používán jak pro vyjádření sémantiky, tak syntaxe organizovaného celku, případně i pravidel, určujících používání struktury. Základním strukturním prvkem systému organizace znalostí v tomto pojetí je tedy termín.
Pojmové modely systémů organizace znalostí
Tato skupina je názorným příkladem metamodelů, které představují ‚model modelu‘ či ‚strukturu struktury‘ metadat, případně ‚metadatové schéma metadatového schématu‘. Pojmové modely systémů organizace znalostí, jejichž příkladem jsou níže uvedený model tezauru v normě ISO 25964 a model SKOS, zobecňují jejich strukturu a umožňují tak teoretický výzkum a zejména implementaci systémů organizace znalostí do současné informační infrastruktury síťového prostředí.
Klíčovým standardem pro vývoj, používání a správu nástrojů pro vyhledávání informací je mezinárodní norma věnovaná tezaurům a dalším řízeným slovníkům ISO 25964, jejíž historie sahá až do počátku 70. let 20. století. Aktuální vydání z let 2011 a 2013 (ISO 25964-1:2011, ISO 25964-2:2013) bylo zpracováno v gesci technické komise ISO/TC 46 Informace a dokumentace. Norma reflektuje změny, k nimž došlo zavedením informačních technologií do této oblasti: softwarové aplikace pro tvorbu a využívání tezaurů, technologie plnotextového vyhledávání ad. Od původního striktního zaměření na návrh tezaurů se záběr rozšířil směrem k obecnějšímu pojetí, použitelnému pro širší spektrum typů řízených slovníků a jiných systémů organizace znalostí. Ve druhé části normy, věnované interoperabilitě, jsou samostatné kapitoly věnovány charakteristice klasifikačních schémat, taxonomií, předmětových heslářů, ontologií, terminologií, seznamů jmenných autorit a seznamů synonym. Obsahem normy jsou jak modely procesů v podobě pravidel pro návrh, implementaci a správu tezaurů včetně pokynů pro řešení lingvisticko-sémantických problémů, tak strukturní model tezauru, zpracovaný jako referenční pojmový model pro implementaci softwarových aplikací využívajících tezaury v počítačovém prostředí. Pojmový model je vyjádřen jak v textové tabelární formě, tak graficky v jazyce UML21. Hlavní třídy modelují tyto pojmy a jejich vzájemné vztahy: tezaurus, pojem tezauru, termín tezauru, vztah hierarchie, vztah asociace a vztah ekvivalence.
SKOS (Simple knowledge organization system) je svými tvůrci definován jako datový slovník pro takový popis systémů organizace znalostí, který umožní jejich sdílení a propojování na webu (Miles a Bechhofer, 2009). Jeho ambicí je definovat minimální množinu charakteristik, společných všem typům systémů organizace znalostí v celém rozsahu jejich škály. V roce 2009 byl SKOS přijat jako standard konsorcia W3C a v současné době představuje nejvýznamnější a v praxi nejpoužívanější obecný metamodel systému organizace znalostí.
SKOS má charakter ontologie formalizované v jazyce OWL a jako takový je tvořen třídami a jejich vlastnostmi (predikáty). Základní třídou je pojem (skos:Concept), který je identifikován svým URI. Pojmy lze agregovat do pojmových schémat, tj. do systémů organizace znalostí (k jejich popisu slouží třída skos:ConceptScheme), například do tezaurů nebo klasifikačních schémat. Další možností je seskupování pojmů v rámci daného systému do kolekcí (třída skos:Collection), například do faset nebo mikrotezaurů.
Vlastnosti (predikáty) jazyka SKOS umožňují formálně vyjádřit obsah pojmů a jejich vzájemné vztahy. Sémantiku pojmů pro lidské uživatele pomáhají upřesnit a definovat různé typy poznámek (skos:definition, skos:note ad.). Skupina vlastností pro označení pojmů umožňuje každý pojem označit jazykovými výrazy (skos:prefLabel – preferované označení, skos:altLabel – alternativní označení, např. synonyma, skos:hiddenLabel – nezobrazované označení) nebo notací (skos:notation).
Nejdůležitějšími vlastnostmi jsou ty, jež umožňují popisovat sémantické vztahy mezi pojmy (skos:semanticRelation). Člení se na dvě vzájemně propojené skupiny: vztahy pojmů v rámci jednoho systému organizace znalostí a vztahy pojmů z různých systémů, nazývané mapování (skos:mappingRelation). Vztahy pojmů v kontextu jednoho systému jsou asociace (skos:related), obecná hierarchie (skos:broader – širší pojem, skos:narrower – užší pojem) a hierarchie, umožňující tranzitivitu (skos:broaderTransitive, skos:narrowerTransitive). Při mapování pojmů je možné vyjádřit různé stupně ekvivalence: skos:exactMatch, skos:closeMatch. Navíc lze i mezi pojmy z různých systémů definovat asociativní (skos:relatedMatch) a hierarchické vztahy (skos:broadMatch, skos:narrowMatch), jež jsou významově ekvivalentní analogickým vztahům v rámci jednoho systému organizace znalostí.
Závěr
V tomto článku jsme se pokusili přinést dílčí příspěvek k formování teorie pojmových modelů v informační vědě. Byla navržena fasetová struktura popisu modelů, již lze uplatnit i pro popis modelů pojmových. S uplatněním perspektivy sémiotického trojúhelníku byly specifikovány vybrané funkce pojmových modelů relevantních pro informační vědu: tvorba modelu reality, tvorba modelu znaku, tvorba artefaktu podle modelu, formalizace pojmového modelu, tvorba nového modelu s využitím modelu existujícího. Byla navržena rámcová typologie obsahu a formy pojmových modelů v informační vědě, zasazená do kontextu pojmových modelů a modelovacích jazyků v informatice.
V úvodu jsme vyjádřili přesvědčení, že informační věda potřebuje zformulovat vlastní teorii pojmových modelů, které budou vystihovat specifické objekty a události touto vědou zkoumané. Pro okruh deskriptivních modelů potřebuje informační věda především teoretické základy umožňující konstrukci modelů struktur informačních zdrojů, aktuální jsou zejména digitální zdroje. Další významnou skupinou strukturních modelů jsou modely metadat a obsahu informačních zdrojů (aboutness). Deskriptivní modely procesů jsou žádoucí zejména pro modelování komunikačního procesu a informačních potřeb a informačního chování. Rovněž preskriptivní modely je zapotřebí opřít o teoretické základy. Potřebné je to především pro široký okruh modelů pravidel pro tvorbu metadat a pro technologické a právní modely vyhledávání informací a přístupu k informacím.
Ve všech zmíněných oblastech se jeví jako důležité formalizovat modely pro účely jejich využití ve strojovém zpracování. Za klíčový problém k řešení pro informační vědu považujeme nalezení optimálního poměru mezi sémantickou vyjadřovací silou modelů a jednoduchostí jejich používání. Jak ukazují četné příklady nástrojů a jazyků organizace znalostí, v praxi se často prosazují jednodušší řešení na úkor propracovaných komplexních systémů. Stačí připomenout vysoce formalizovaný systém Mezinárodního desetinného třídění, jehož složitost brání v jeho masovém využití a je (možná paradoxně) překážkou jeho využití k automatické indexaci a v prostředí sémantického webu. Elaine Svenoniová (2004, s. 585) uzavírá své srovnání teorií poznání slovy, jež lze vztáhnout i na problematiku pojmových modelů: „Možná nepotřebujeme vždycky validní reprezentaci, pokud nám bude stačit taková, která je užitečná.”
Použitá literatura
BAWDEN, David a Lyn ROBINSON, 2017. Úvod do informační vědy. 1. vyd. Doubravník: Flow, 2017. ISBN 978-80-88123-10-1.
BRATKOVÁ, Eva a Helena KUČEROVÁ, 2014. Systémy organizace znalostí a jejich typologie. Knihovna: knihovnická revue. 25(2), 5–29. ISSN 1801-3252 (print). ISSN 1802-8772 (online).
BUBENKO, Janis A., 2007. From information algebra to enterprise modelling and ontologies – a historical perspective on modelling for information systems. In: John Krogstie, Andreas Lothe Opdahl, Sjaak Brinkkemper, ed. Conceptual modelling in information systems engineering. Berlin: Springer, s. 1–18. doi: https://doi.org/10.1007/978-3-540-72677-7_1. ISBN 978-3-540-72676-0 (print). ISBN 978-3-540-72677-7 (online).
CABRÉ, M. Teresa, 1999. Terminology: theory, methods and applications. Amsterdam; Philadelphia: John Benjamins Publishing Company. ISBN 978-1-55619-787-1.
COYLE, Karen a Thomas BAKER, 2009. Guidelines for Dublin Core Application Profiles (working draft) [online]. Dublin (Ohio): DCMI,2009-05-18 [cit. 2018-09-20]. Dostupné z: http://dublincore.org/documents/profile-guidelines/.
ČERMÁK, František, 2007. Jazyk a jazykověda: přehled a slovníky. 2. dotisk 3. dopl. vyd. Praha: Karolinum. ISBN 987-80-246-0154-0.
ČSN ISO 14721, 2014. Systémy pro přenos dat a informací z kosmického prostoru – Otevřený archivační informační systém – Referenční model. 2. vyd. Praha: Úřad pro technickou normalizaci, metrologii a státní zkušebnictví. 97 s. Třídicí znak 31 9620.
ČSN ISO 5963, 1995. Dokumentace. Metody analýzy dokumentů, určování jejich obsahu a výběru lexikálních jednotek selekčního jazyka. Praha: Český normalizační institut. 10 s. Třídicí znak 01 0174.
ČSN ISO TR 9007, 1995. Systémy zpracování informací: Pojmy a terminologie pro pojmové sché ma a informační základnu. Praha: Český normalizační institut. 131 s. Třídicí znak 97 9702.
DROBÍKOVÁ, Barbora, Radka ŘÍMANOVÁ, Jiří SOUČEK a Martin SOUČEK, 2018. Teoretická východiska informační vědy: využití konceptuálního modelování v informační vědě. 1. vyd. Praha: Karolinum. 136 s. ISBN 978-80-246-3716-7. ISBN 978-80-246-3881-2 (pdf).
EMBLEY, David W. a Bernhard THALHEIM, ed., 2011. Handbook of conceptual modeling: theory, practice, and research challenges. Berlin: Springer. xix, 589 s. ISBN 978-3-642-15864-3 (print). ISBN 978-3-642-15865-0 (online).
GOGUEN, Joseph, 2005. What is a concept? In: Frithjof Dau, Marie-Laure Mugnier, Gerd Stumme, ed. Conceptual structures: common semantics for sharing knowledge: 13th International Conference on Conceptual Structures, ICCS 2005, Kassel, Germany, July 17-22, 2005. Berlin: Springer, s. 52–77. Lecture notes in computer science, no. 3596. doi:https://doi.org/10.1007/11524564_4. ISSN 0302-9743. ISBN 978-3-540-27783-5 (print). ISBN 978-3-540-31885-9 (online).
CHEN, Peter Pin-Shan, 1976. The entity-relationship model – toward a unified view of data. ACM Transactions on Database Systems. 1(1), 9–36. doi:10.1145/320434.320440. ISSN 0362-5915 (print).ISSN 1557-4644 (online).
ICOM/CIDOC Special Interest Group, 2003. Definition of the CIDOC Conceptual Reference Model [online]. Produced by the ICOM/CIDOC Documentation Standards Group, continued by the CIDOC CRM Special Interest Group. Patrick LeBoeuf, Martin Doerr, Christian Emil Ore, Stephen Stead, ed. Version 6.2.3. © 2003, version from May 2018 [cit. 2018-09-20]. 287 s. Dostupné z: http://www.cidoc-crm.org/Version/version-6.2.3-0.
IFLA, 2015. Definition of FRBRoo: a conceptual model for bibliographic information in object-oriented formalism [online]. Version 2.4. Chryssoula Bekiari, Martin Doerr, Patrick Le Boeuf, Pat Riva, ed. International Working Group on FRBR and CIDOC CRM Harmonisation, November 2015 [cit. 2018-09-20]. 283 s. Dostupné z: https://www.ifla.org/publications/node/11240.
IFLA, 2016. Statement of international cataloguing principles (ICP) [online]. Agnese Galeffi, María Violeta Bertolini, Robert L. Bothmann, Elena Escolano Rodríguez, Dorothy McGarry, ed. IFLA Cataloguing Section and IFLA Meetings of Experts on an International Cataloguing Code, December 2016. Edition with minor revisions, 2017 [cit. 2018-09-20]. 26 s. Dostupné z: https://www.ifla.org/publications/node/11015.
IFLA, 2017. IFLA library reference model: a conceptual model for bibliographic information [online]. Pat Riva, Patrick Le Boeuf, Maja Žumer, ed. Hague: International Federation of Library Associations and Institutions. Rev. August 2017 as amended and corrected through December 2017 [cit. 2018-09-20]. 101 s. Dostupné z: https://www.ifla.org/publications/node/11412.
ISO 24156-1:2014. Graphic notations for concept modelling in terminology work and its relationship with UML – Part 1: Guidelines for using UML notation in terminology work. 1st ed. Geneva: International Organization for Standardization, 2014. 24 s.
ISO 25964-1:2011. Information and documentation – Thesauri and interoperability with other vocabularies – Part 1: Thesauri for information retrieval. 1st ed. Geneva: International Organization for Standardization, 2011-08-08. 152 s.
ISO 25964-2:2013. Information and documentation – Thesauri and interoperability with other vocabularies – Part 2: Interoperability with other vocabularies. 1st ed. Geneva: International Organization for Standardization, 2013-03-04. 99 s.
ISO 704:2009. Terminology work – Principles and methods. 3rd ed. Geneva: International Organiza-tion for Standardization, 2009-11-01. 65 s.
ISO/TR 9007:1987. Information processing systems – Concepts and terminology for the conceptual schema and the information base. 1st ed. Geneva: International Organization for Standardiza-tion, 1987-07-01. 120 s.
KUČEROVÁ, Helena, 2014. Co analyzujeme při obsahové analýze dokumentů? K pojmu aboutness v organizaci znalostí. Knihovna: knihovnická revue. 25(1), 36–54. ISSN 1801-3252 (print). ISSN 1802-8772 (online).
LAKOFF, George, 2006. Ženy, oheň a nebezpečné věci: co kategorie vypovídají o naší mysli. 1. vyd. Praha: Triáda. Kapitola 2. Od Wittgensteina k Roschové, s. 25–66. ISBN 978-80-86138-78-7.
LUDEWIG, Jochen, 2003. Models in software engineering – an introduction. In: Software and systems modeling (SoSyM). 2(1), 5–14. doi:10.1007/s10270-003-0020-3. ISSN 1619-1366 (print). ISSN 1619-1374 (online).
MARRADI, Alberto, 2012. The concept of concept: concepts and terms. Knowledge organization. 39(1), 29–54. ISSN 0943-7444.
MILES, Alistair a Sean BECHHOFER, ed., 2009. SKOS Simple Knowledge Organization System Reference [online]. W3C Recommendation 18 August 2009 [version, cit. 2018-09-20]. Cambridge (MA): World-Wide Web Consortium. Dostupné z: http://www.w3.org/TR/2009/REC-skos-reference-20090818/.
NISO TR-06-2017, 2017. Issues in vocabulary management: a technical report of the National Information Standards Organization [online]. Baltimore: NISO, 2017-09-25 [cit. 2018-09-20]. ISBN 978-1-937522-79-7. Dostupné z: https://www.niso.org/publications/tr-06-2017-issues-vocabulary-management.
OMG, 1997. OMG Unified Modeling Language (OMG UML) [online]. Object Management Group, 1997- [cit. 2018-09-20]. Dostupné z: http://www.omg.org/spec/UML/.
OMG, 2014. MDA guide. Revision 2.0 [online]. Needham (MA, USA): Object Management Group, June 2014 [cit. 2018-09-20]. 15 s. Document Number: ormsc/2014-06-01. Dostupné z: http://www.omg.org/cgi-bin/doc?ormsc/14-06-01.
OMG, 2017. Semantics of Business Vocabulary and Business Rules [online]. Version 1.4. Needham (MA, USA): Object Management Group, May 2017 [cit. 2018-09-20]. 314 s. OMG Document Number: formal/2017-05-05. Dostupné z: https://www.omg.org/spec/SBVR/.
PISANSKI, Jan a Maja ŽUMER, 2010a. Mental models of the bibliographic universe. Part 1: mental models of descriptions. Journal of documentation. 66(5), 643–667. doi:10.1108/00220411011066772. ISSN 0022-0418.
PISANSKI, Jan a Maja ŽUMER, 2010b. Mental models of the bibliographic universe. Part 2: comparison task and conclusions. Journal of documentation. 66(5), 668-680. doi:10.1108/00220411011066781. ISSN 0022-0418.
POPPER, Karl Raimund, 1979. Objective knowledge: an evolutionary approach. Revised ed. Oxford: Oxford University Press. ISBN 0-19-875024-2.
REDMOND-NEAL, Alice a Marjorie M. K. HLAVA, ed., 2005. ASIS&T thesaurus of information science, technology, and librarianship. 3rd ed. Medford: Information Today on behalf of the American Society for Information Science and Technology. xiii, 255 s. ASIST monograph series. ISBN 978-1-57387-243-0. ISBN 1-57387-244-X (s CD-ROM).
RIVA, Pat a Maja ŽUMER, 2018. FRBRoo, the IFLA Library Reference Model, and now LRMoo: a circle of development [online]. Paper presented at IFLA WLIC 2018 – Kuala Lumpur, Malaysia – Transform Libraries, Transform Societes in Session 74 – Impact of recently approved IFLA standards – Committee on Standards. 2018-08-25 [cit. 2018-09-20]. 7 s. Dostupné z: http://library.ifla.org/2130/.
ROUSSOPOULOS, Nick a Dimitris KARAGIANNIS, 2009. Conceptual modeling: past, present and the continuum of the future. In: Alexander T. Borgida, Vinay K. Chaudhri, Paolo Giorgini, Eric S. Yu, ed. Conceptual modeling: foundations and applications. Essays in honor of John Mylopoulos. Berlin: Springer, s. 139–152. doi:10.1007/978-3-642-02463-4. ISBN 978-3-642-02462-7 (print). ISBN 978-3-642-02463-4 (online).
SEDLÁKOVÁ, Miluše, 2004. Vybrané kapitoly z kognitivní psychologie: mentální reprezentace a mentální modely. 1. vyd. Praha: Grada. 252 s. ISBN 80-247-0375-0.
SVENONIUS, Elaine, 2004. The epistemological foundations of knowledge representation. Library trends. 52(3), 571–587. ISSN 0024-2594 (print). ISSN 1559-0682 (online).
THALHEIM, Bernhard, 2011. The theory of conceptual models, the theory of conceptual modelling and foundations of conceptual modelling. In: David W. Embley, Bernhard Thalheim, ed. Handbook of conceptual modeling: theory, practice, and research challenges. Berlin: Springer, Part V, s. 543–577. doi:10.1007/978-3-642-15865-0_17. ISBN 978-3-642-15864-3 (print). ISBN 978-3-642-15865-0 (online).
WAND, Yair a Ron WEBER, 1990. Toward a theory of the deep structure of information systems. In: Janice I. DeGross, Maryam Alavi, Hans J. Oppeland, ed. Proceedings of the Eleventh International Conference on Information Systems, December 16–19, 1990, Copenhagen, Denmark. Baltimore (Mar.): ACM Press.
ZENG, Marcia Lei a Jian QIN, 2016. Metadata. 2nd edition. Chicago: Neal-Schuman, an imprint of the American Library Association. xxvii, 555 s. ISBN 978-1-55570-965-5.
1 BOX, George Edward Pelham, 2013. An accidental statistician: the life and memories of George E. P. Box. Hoboken: Wiley, s. 162. ISBN 978-1-118-40088-3.
2 V tuzemském kontextu tuto orientaci potvrzuje i nedávno vydaná publikace autorského kolektivu Ústavu informačních studií a knihovnictví FF UK (Drobíková, 2018).
3 Proto může být za model považována třeba i mapa smyšleného Yoknapatawphského okresu, kterou pro svá díla vytvořil William Faulkner. Náhled obrázku je dostupný z: http://en.wikipedia.org/wiki/File:Yoknapatawpha.County.jpg [cit. 2018-09-20].
4 Cit. dle PALEK, Bohumil, ed., 1997. Sémiotika: Ch. S. Peirce, C. K. Ogden and I. A. Richards, Ch. W. Morris, H. B. Curry. 2. přeprac. vyd. Praha: Karolinum, s. 37. ISBN 80-7184-356-3.
5 Poznámka: Extrémním příkladem individuálně vytvářených modelů jsou některé náčrtky v zápisnících Leonarda da Vinciho, který k nim dokonce záměrně psal komentáře zrcadlovým písmem (viz např. ukázka na http://www.bl.uk/manuscripts/Viewer.aspx?ref=arundel_ms_263_f001r [cit. 2018-09-20]).
6 Viz např. Katalog soutěžních návrhů na http://wwwold.nkp.cz/soutezni_navrhy/start.htm [cit. 2018-09-20].
7 Dostupné komerčně např. z: https://beta-rdatoolkit-org.ezproxy.is.cuni.cz/RDA.Web/Guidance?externalId=en-US_Recording_methods [cit. 2018-09-20].
8 Poznámka: Obdobně to platí i pro datový model – toto slovní spojení může rovněž označovat jak model dat, tak model z dat.
9 Poznámka: na této úrovni zobecnění lze konstatovat, že abstraktní pojmový model má stejné vlastnosti jako entita Vyjádření z modelu FRBR, resp. IFLA LRM.
10 Poznámka: na této úrovni zobecnění lze konstatovat, že konkrétní pojmový model má stejné vlastnosti jako entita Provedení z modelu FRBR, resp. IFLA LRM.
11 Dopředné a reverzní (zpětné) inženýrství se liší směrem vývoje. Dopředné inženýrství postupuje od modelu k artefaktu, zatímco během reverzního inženýrství se model zpětně odvozuje z funkční implementace.
12 Poznámka: Český ekvivalent pro název Library reference model ještě nebyl vytvořen. Nabízí se více možností překladu: referenční model knihovny, knihovní či knihovnický referenční model, případně referenční model pro knihovny.
13 Viz soubory nazvané RDA element sets, online dostupné z: http://www.rdaregistry.info/Elements/ a RDA value vocabularies, dostupné z: http://www.rdaregistry.info/termList/.
14 Metadata Management Associates, 2010. Element sets [online]. In: Open metadata registry, 2010– [cit. 2018-09-20]. Dostupné z: http://metadataregistry.org/schema/list.html.
15 Dostupné z: http://www.rdaregistry.info/termList/RDAContentType.
16 ISO 5127:2017. Information and documentation – Foundation and vocabulary. 2nd ed. Geneva: International Organization for Standardization, 2017-05. 353 s.
17 ISO/IEC 2382:2015. Information technology – Vocabulary [online]. 1st ed. Geneva: International Organization for Standardization, 2015-05 [cit. 2018-09-20]. Dostupné z: https://www.iso.org/obp/ui/#iso:std:iso-iec:2382:ed-1:v1:en.
18 KTD: Česká terminologická databáze knihovnictví a informační vědy (TDKIV) [online databáze]. Praha: Národní knihovna České republiky, 2003– [cit. 2018-09-20]. Dostupné z: http://aleph.nkp.cz/cze/ktd.
19 IFLA, 2010. Multilingual dictionary of cataloguing terms and concepts (MulDiCat) [online]. MulDiCat Working Group, Cataloguing Section; Barbara B. Tillett, ed. Hague: International Federation of Library Associations and Institutions, 2010– [cit. 2018-09-20]. Dostupné z: https://www.ifla.org/publications/multilingual-dictionary-of-cataloguing-terms-and-concepts-muldicat a z: http://metadataregistry.org/vocabulary/show/id/299.html.
20 Universitätsbibliothek Basel, 2013. BARTOC.org: BAsel Register of Thesauri, Ontologies & Classifications [online]. Projektleiter Andreas Ledl. Basel: Universitätsbibliothek Basel, 2013– [cit. 2018-09-20]. Dostupné z: http://www.bartoc.org/.
21 Náhled je dostupný z: http://www.niso.org/schemas/iso25964/Model_2011-06-02.jpg [cit. 2018-09-20].
KUČEROVÁ, Helena. Pojem modelu a pojmový model v informační vědě. Knihovna: knihovnická revue, 2018, 29(2), 5–32, ISSN 1801-3252.









{kind=link}
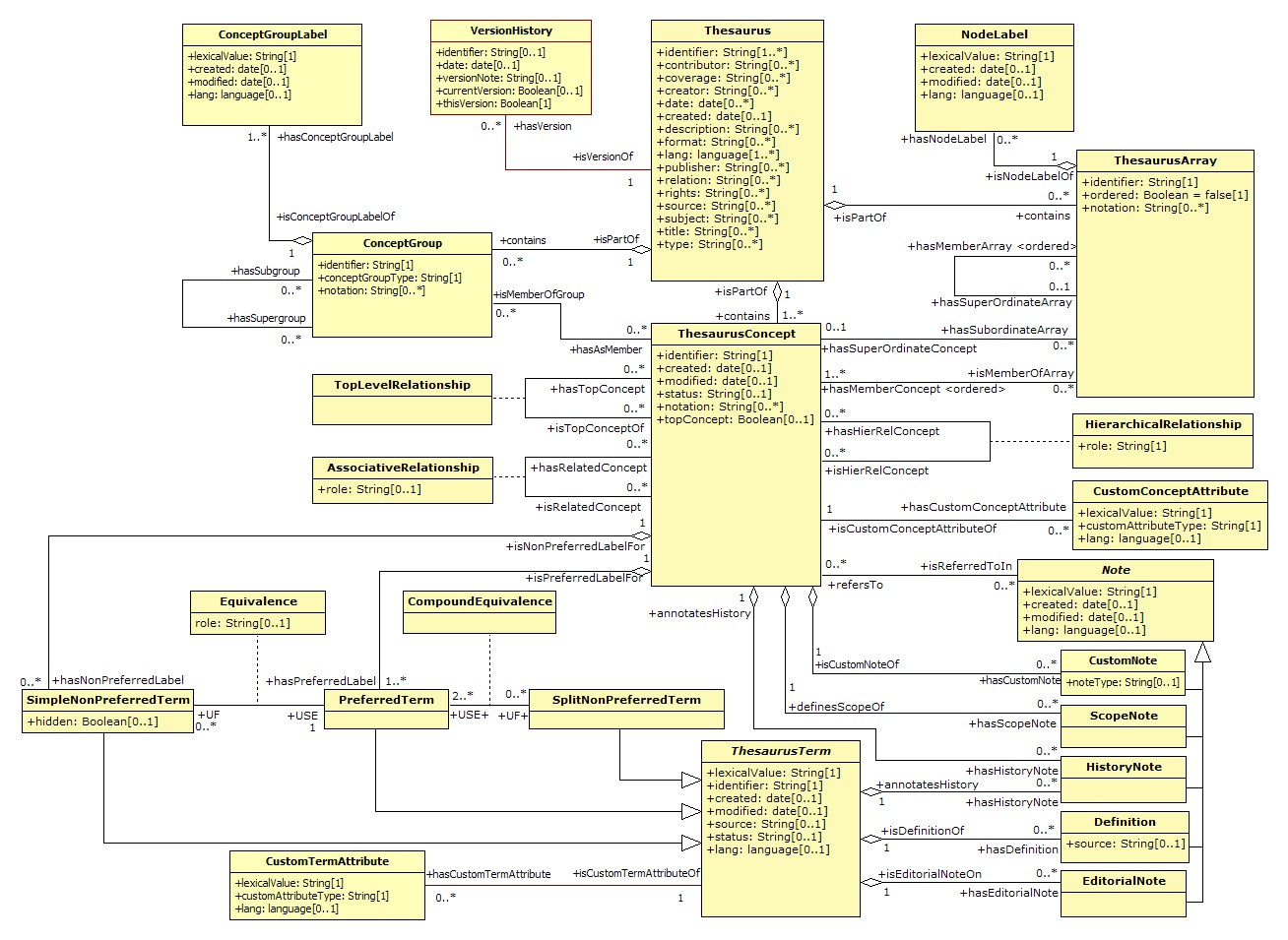{kind=link}