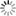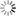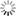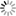Vyhledávání v prostředí webu – je vůbec něco nového?
Doc. Ing. Vilém Sklenák, CSc. / Katedra informačního a znalostního inženýrství, fakulta informatiky a statistiky, VŠE v Praze
Úvod
Na první pohled by se mohlo zdát, že v oblasti webového vyhledávání se v poslední době nic neděje. Karty jsou již několik let rozdány. Google dominuje téměř ve všech zemích, v České republice se mu snaží sekundovat Seznam. Zdání však může trochu klamat. Jakkoliv se vnější podoba vyhledávání zdá stále stejná, o to více se může odehrávat pod povrchem. V následujícím krátkém shrnutí se pokusím zrekapitulovat největší zajímavosti, které menší či větší měrou pociťují uživatelé při vyhledávání.
Vyhledávání prostřednictvím mobilních zařízení
V posledních několika málo letech došlo ve využívání Internetu k významnému posunu směrem k mobilním zařízením, jako jsou chytré telefony, tablety, čtečky apod. Přispělo k tomu více faktorů:
- Zrychlování internetového mobilního připojení včetně rozumnější tarifní politiky.
- Masivní rozšiřování mobilních zařízení za rozumné ceny.
- Generační posun operačních prostředí, kdy webové prohlížeče již jsou plnohodnotným nástrojem.
- Rostoucí rozlišení zobrazovacích jednotek.
I proto se jeví jako logický krok firmy Google, která již dlouho dopředu oznámila, že počínaje dnem 21. 4. 2015 bude ve výsledcích vyhledávání upřednostňovat stránky, které jsou „přátelské“ vůči mobilním zařízením. Neformálně se pak tento den nazývá „Mobilegeddon“.[1]
Zmíněná preference se pochopitelně týká jen dotazů, které jsou uživateli odesílány z mobilních zařízení. Smysl tohoto opatření spočívá v tom, aby se nalezené výsledky dobře používaly. Proto mezi kritéria hodnotící vstřícnost webu vůči mobilním zařízením patří mj.:
- Velikost písma,
- vzdálenost odkazů (prst je přece jen méně přesný než ukazatel myši),
- šíře zobrazení, aj.
Současně s oznámením datumu dal Google k dispozici také testovací nástroj, aby se tvůrci stránek mohli připravit.
Úpravy algoritmů pro hodnocení webových stránek
Google dlouhodobě bojuje jednak s kvalitou webových stránek, jednak s různými praktikami, které se snaží zlepšovat pozice stránek ve výsledcích vyhledávání. Své algoritmy pojmenoval podle zástupců zvířecí říše, které ani v nejmenším nelze podezírat z nějaké agresivity nebo záludnosti:
- Google Panda je algoritmus modifikující řazení výsledků vyhledávání, který je v provozu od února 2011 a který znevýhodňuje stránky nízké kvality,
- Google Penguin je algoritmus modifikující řazení výsledků vyhledávání, který je v provozu od dubna 2012 a který penalizuje stránky používající nekalé SEO praktiky, nebo porušující doporučení Google’s Webmaster Guidelines[2]
Tyto algoritmy jsou průběžně aktualizovány.
Nejnovějším přírůstkem do „stáje“ je algoritmus Pigeon, který ve výsledcích vyhledávání upřednostňuje weby s lokálním cílením (týká se zejména poskytování služeb všeho druhu). V současnosti je použití algoritmu omezeno na území USA.
Objeví se konkurenti?
Od nástupu služby Google v roce 1998 jakoby vymizeli konkurenti. Pro běžné uživatele téměř platí pomyslná rovnost webové vyhledávání = Google. Vůdčí pozice je však vždy výzvou pro soupeře, kteří se ani po mnoha letech nevzdávají. Historie posledních let je ale spíše historií pomníčků více či méně ambiciózních projektů:
- Wikia Search – pokus zakladatele Wikipedie,
- Quaero – projekt evropského vyhledávače[3],
- Theseus – Německo krátce po zahájení projektu Quaero vystoupilo z konsorcia a přišlo s projektem vlastním.[4]
Žadný z těchto projektů však neuspěl, pokud za měřítko úspěchu bereme masové nasazení do rutinního provozu pro běžné uživatele. Projekty byly zastaveny. Jak u projektu Quaero, tak projektu Theseus bylo dosaženo dílčích výsledků ve smyslu algoritmů nebo programových modulů, které jsou popsány na stránkách projektů a jsou k dispozici pro eventuální další využití.
Jediného konkurenta pro Google představila před pár lety firma Microsoft. Je to vyhledávač Bing. Ale i pro firmu Microsoft to byl opakovaný pokus (viz např. neúspěšný vyhledávací stroj LiveSearch). Bing jediný zaznamenává v průzkumech vyhledávacího trhu významnější podíl. Týká se to však zejména USA, kde má nejnověji podíl kolem 20 %, a pokud se vezme v úvahu jeho využívání v rámci aliance se službou Yahoo, pak dokonce až 33 %.[5] V jiných zemích světa to však tak slavné již není.
Nyní se však proslýchá, že do světa velkých vyhledávačů možná vstoupí další velký hráč – firma Apple. Mohou o tom svědčit některé indicie. Například před nedávnem proběhla ze strany firmy Apple akvizice firmy Topsy, která se specializuje na analýzu sociálních sítí. Dále pak bylo v květnu 2015 potvrzeno, že je v provozu robot Applebot, podle sdělení firmy však tento crawler slouží pouze jako podpora pro služby Siri a Spotlight.[6] Nechme se však překvapit, co přinese další vývoj.
Je všeobecně známo, že běžné indexování obsahu webu nezasáhne tzv. neviditelný web, neboli též deep web. Obvykle se jedná o obsah, který je pomocí webové služby normálně dostupný, čili není zapotřebí žádné specifické vybavení nebo specifický prohlížeč apod. Pro dostupnost daného obsahu je však zapotřebí např. projít přihlašovací procedurou, nebo zadat vyhledávací filtry pro výběr údajů z databáze aj. Uživatel-člověk se s tímto vypořádá bez problémů, pro uživatele-robota to je ale překážka. Lze však říci, že neviditelný web se nesnaží nic skrývat. Totéž už neplatí pro tzv. temný web, neboli dark web. Zde se jedná o úmyslně skrývaný obsah, který je určen jen povolaným a který není žádnému uživateli běžnými prostředky dostupný. Tímto skrývaným obsahem může být cokoliv, ale je zřejmé, že mnohdy má nelegální charakter. Zřejmě mediálně nejznámějším nástrojem pro práci s tímto typem obsahu je anonymizační prostředí Tor. Vedle aktivistů, disidentů je služba oblíbená mezi hackery, drogovými dealery apod. Americká agentura DARPA je primárně zaměřena na pomoc bezpečnostním složkám USA, a proto se asi nelze divit, že přišla s projektem Memex[7] [8]. [9] Jedná se o tříletý projekt, jehož řešení začalo koncem roku 2014. Cílem je vytvořit takový vyhledávač, který bude schopen indexovat skrytý obsah webu, tj. zejména temný web. Je pochopitelné, že žádné detaily o případném fungování nejsou a ani nebudou k dispozici. V první fázi je algoritmus testován na obsahu zaměřeném na obchod s lidmi. Nejedná se v pravém smyslu slova o konkurenci pro Google, nicméně se jedná o ukázku vyspělých technologií, což osvědčuje i zveřejněné demonstrační video[10].
Seznam nezaostává
Firma Seznam si je vědoma své oblíbenosti mezi českými uživateli, a proto se snaží zlepšovat nejen vlastní vyhledávač, ale nabízené služby jako celek. Je však pravdou, že v posledních měsících jsou změny na první pohled méně patrné. Již před rokem přešel vyhledávač na plně responzivní design.
(Cílem responzivního webdesignu je, aby webová stránka měla jeden zdrojový kód, který bude vyhovovat všem zařízením, která se používají pro prohlížení webu. Klíčovým principem je přizpůsobení zobrazení webové stránky různým rozlišením tak, aby stránka vypadala stále dobře čitelná, aby se v ní dobře navigovalo a aby se minimalizovala nutnost rolování či posouvání).
Na jaře 2015 byl spuštěn přechod celého portálu na nový design, který má působit více odlehčeným dojmem. Pro porovnání si lze uvést vedle sebe vzhled „starý“ a inovovaný, jak ukazuje obr. 1.
Podobně jako Google i Seznam bojuje s kvalitou prohledávaných webových stránek, případně s různými nečistými metodami, které se snaží zlepšit pozici stránky ve vyhledaných výsledcích (SERP[11]). Do mechanismů, které se podílejí na fungování vyhledávací služby Seznamu, byl zařazen v květnu 2015 algoritmus zvaný jalapeño[12]. Jeho smysl spočívá v:
- Boji s webovým spamem,
- snižování skóre u stránek s velmi agresivními SEO[13] technikami.
Odhaduje se, že daný algoritmus bude mít přímý vliv na zhruba 2 % dotazů.
Obrázek 1 Seznam nový design
Vyhledávání nejsou jen texty
Obsah webu není tvořen jen texty, jeho nedílnou součástí i obrázky. Pokud pomineme ty, jež mají pouze dekorační charakter, pak většina obrázků má svým obsahem co sdělit. Mnohdy platí, že obrázek je výmluvnější než spousta popisného textu. Již poměrně dlouhou dobu jsou obrázky také cílem vyhledávání. V základní rovině mohou vyhledávače vyjít při odhadování obsahu obrázků z textů, které jsou s obrázkem v užším vztahu:
- Název souboru obsahující obrázek za předpokladu, že se nejedná o slaboduché názvy jako 001.jpg apod.
- Hodnota atributu alt, jež je součástí elementu img, který se používá pro vnoření obrázků do webových stránek. Atribut alt je právě zamýšlen jako alternativní textový popis obsahu obrázku mající víceúčelové použití:
- Je použit, pokud nelze obrázek zobrazit (např. z důvodu zákazu na straně uživatele).
- Je použit, pokud je obsah webové stránky předčítán (např. pro slabozraké uživatele).
- A konečně poslouží také při indexování obrázků.
- Text, který se nachází v bezprostředním okolí obrázku.
- Případná metadata uložená přímo v obrázku – EXIF (Exchangeable image file format) obsahuje spíše technické parametry týkající se vzniku, ale u fotografií může obsahovat např. geolokační údaje.
Na uvedeném základě pak může fungovat s celkem uspokojivými výsledky vyhledávání obrázků pomocí textových dotazů. Tato forma je uživatelům blízká – jediné, co je potřeba, aby vystihli, je zaměření obrázku vhodně zvolenými klíčovými slovy. To by neměl být problém, pokud je splněn předpoklad, že uživatel ví, co chce, a proto to také dokáže popsat.
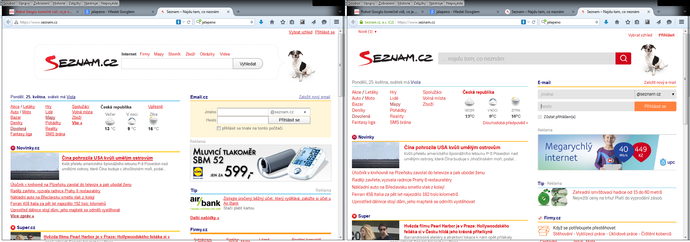
Zajímavá situace však nastává, pokud uživatel nemá odpovídající znalosti, aby jeho dotaz byl dostatečně konkrétní. Má ale k dispozici obrazový vzor, třeba vlastní fotografii obsahující zajímavý objekt, ke kterému by se chtěl uživatel dozvědět více. Hledání pomocí obrazové ukázky nabízí Google již delší dobu – v jednoduchém formuláři pro dotaz na obrázek je trochu nenápadná ikona fotoaparátu (viz obr. 2).

Obrázek 2 Google - obrázky - hledání
Uvedená možnost funguje poměrně spolehlivě v situaci, kdy se předkládá obrázek pocházející z nějakých webových stránek, jak to ukazuje mj. obr. 3 (rozdíl mezi levým a pravým výsledkem spočíval v tom, že vlevo byl použit významově pojmenovaný obrázek, naopak vpravo se obrázek jmenoval 1.png). Z toho lze usuzovat, že Google si při indexování obrázků ukládá kromě výše zmíněných textových informací také nějaké další pomocné údaje.
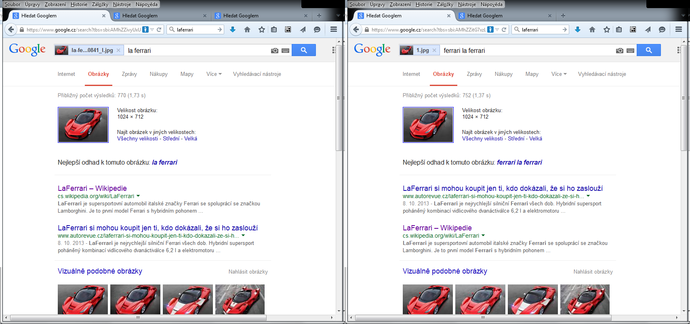
Obrázek 3 Hledání La Ferrari
Použijeme-li tutéž funkci s obrázkem, který je pro Google neznámý, pak už jsou výsledky méně přesvědčivé – viz obr. 4. V dané situaci je na závadu absence schopnosti obrázku porozumět jen na základě toho, co je na něm vidět.
V blízké budoucnosti lze očekávat posun směrem ke strojovému „porozumění“ obrázku. Určitou vlaštovkou je v tomto úsilí projekt Image Identification Project[14] Stephena Wolframa, který je veřejnosti znám mj. díky nekonvenčnímu vyhledávači WolframAlpha. Na obrázku 5 lze vidět úvodní obrazovku, která jen vyzývá k tomu, aby uživatel vložil svůj obrázek, který je pak následně podroben analýze ve snaze identifikovat obsah. Výsledek zpracování obrázku motýla, který byl dříve použit jako testovací pro Google (viz obr. 4), ukazuje pak obr. 6. Lze říci, že odpověď stroje je celkem trefná, protože se jedná o motýla z čeledi Babočkovitých.
V současné době Google pracuje na anotačním nástroji pro popis obsahu obrázku, čím je samozřejmě myšleno automatické anotování. Nástroj vychází jednak z technik strojového učení, jednak je založen na mohutném výpočetním výkonu superpočítačů.[15]
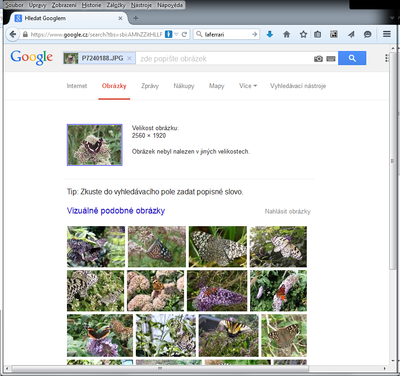
Obrázek 4 Google-obrázek-mimo-web
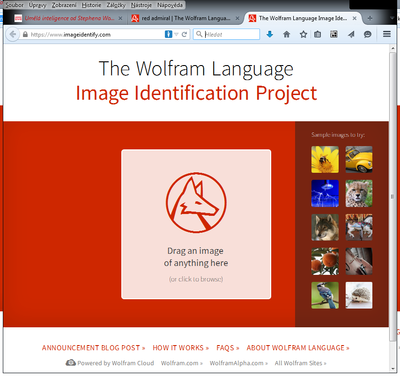
Obrázek 5 Wolfram - IIP
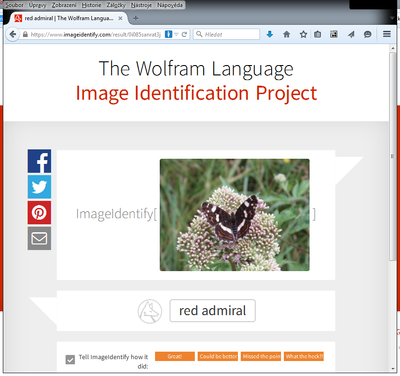
Obrázek 6 Wolfram - IIP - babocka
Závěr
Svět vyhledávání v posledních letech pronikl do každodenní praxe běžných uživatelů. Přispěl k tomu jak rostoucí podíl domácností s internetovým připojením, tak rostoucí využívání mobilního připojení. Uživatelé si zvykli mít informace kdykoliv a kdekoliv – informace užitečné jak pro všední život, tak pro odbornou práci. Vyhledávače se pokoušejí skloubit dvě, možná protichůdné, snahy. Na straně jedné poskytovat co nejkvalitnější výsledky, na straně druhé klást uživateli minimum překážek k jejich dosažení. Pravděpodobně se to daří. Svědčí o tom i průzkumy mezi uživateli, kteří buď vůbec netuší existenci pokročilejších možností v podobě různých operátorů nebo filtrů, nebo je vědomě nepoužívají. Uživatelé si možná neuvědomují, nebo si nechtějí připustit, zrádnost „chytřejších“ zařízení a technologii, webové vyhledávače nevyjímaje, která spočívá v malém namáhání mozku.[16] Toto není myšleno jako výtka vůči pokročilejším technologiím (kdyby ano, byla by to určitá analogie boje se stroji z doby průmyslové revoluce v 19. století), je na každém uživateli, jak bude nové možnosti vyhledávání používat.
[1] http://www.mobilmania.cz/clanky/google-zvyhodni-mobile-friendly-weby-mate-takovy/sc-3-a-1330432/default.aspx
[2] https://support.google.com/webmasters/answer/35769?hl=en
[5] http://www.zive.cz/bleskovky/bing-v-americe-vali-uz-ma-pres-20--a-stale-bude-vyhledavat-i-v-yahoo/sc-4-a-177992/default.aspx
[6] http://appleinsider.com/articles/15/05/06/apple-challenges-google-with-growing-web-search-program-fueled-by-topsy-acquisition
[7] Memex = Memory Extender
[8] Název Memex poprvé použil „otec“ hypertextu Vannevar Bush ve svém článku As we may think, který byl publikován v roce 1945.
[9] http://www.lupa.cz/clanky/prichazi-memex-vladni-google-ktery-prohleda-i-temny-a-hluboky-web/
[10] http://www.cbsnews.com/news/new-search-engine-exposes-the-dark-web/
[11] SERP = Search Engine Results Pages
[12] http://seznam.seznamblog.cz/post/118765179956/seznam-cz-zkvalitnuje-sve-hledani
[13] SEO = Search Engine Optimization
[14] https://www.imageidentify.com/
[15] http://googleresearch.blogspot.co.uk/2014/11/a-picture-is-worth-thousand-coherent.html
[16] http://www.zive.cz/clanky/s-pouzivanim-chytreho-telefonu-se-zvysuje-lenost-mozku/sc-3-a-177434/default.aspx