Vliv umělé inteligence na důvěryhodnost informací
Úvod
Článek se zaměřuje na vymezení pojmů informace, dezinformace, misinformace a malinformace. Představuje základní typy dezinformačního obsahu, které mohou být negativně ovlivňovány umělou inteligencí, a zaměřuje se na uvedení do problematiky generativní umělé inteligence z různých úhlů pohledu, ať už jde o používané algoritmy či možnosti detekce generovaného obsahu. Obecně se pak zabývá tím, jakou úlohu může hrát umělá inteligence v tvorbě dezinformačního obsahu a také jaký je její vliv na důvěryhodnost informací.
Aby bylo vůbec možné správně pochopit pojem dezinformace, je klíčové nejprve porozumět tomu, co znamená samotný pojem informace. Informaci můžeme vymezit mnoha způsoby. Co však má hodně definic společného je to, že informace je výsledkem zpracování dat, která jsou následně interpretována pro specifické uživatele (viz obr. 1). Na rozdíl od informací jsou data neinterpretovaná a jsou charakteristická svou přesností a stabilitou, což je činí méně náchylnými k manipulaci (Černý, 2016). Zde je vhodné doplnit, že toto tvrzení přímo vystihuje původní význam slova data; latinské „datum“ znamená něco daného a jasně stanoveného (Sklenák et al., 2001), a proto je vždy nutné si v souvislosti s informacemi vybavit i pojem data, jež jsou základním prvkem pro jejich vznik (Stodola, 2015).
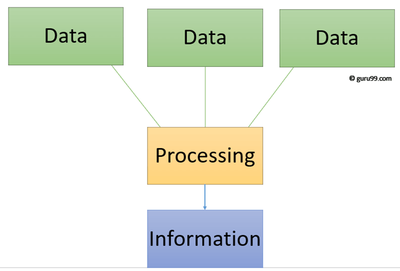
Obr. 1 Vztah mezi daty a informacemi, zdroj (Carter, 2024)
Předpona dez- dává pojmu informace úplně jiné rozměry. Výraz dezinformace se s největší pravděpodobností objevil okolo roku 1949 a pochází z ruského slova дезинформация [dezinformacija]. Můžeme ho definovat jako nepravdivou informaci, která je úmyslně zveřejňována za účelem poškodit lidi či uživatele internetu, k nimž se tato zpráva dostane (MVČR, b.r.). S pojmem dezinformace bývají často zaměňována další slova, jež vyjadřují negativní stránku informací. Těmito slovy jsou misinformace a malinformace, která nejsou synonymy výrazu dezinformace, každý tento termín znamená něco jiného. Misinformace je taková forma informace, která je chybná či nepravdivá, avšak není zveřejněna úmyslně, za účelem někoho poškodit. Jedná se tedy pouze o lidskou chybu toho, kdo tuto informaci vypustil do veřejného prostoru. Misinformace, na rozdíl od dezinformací, bývá však stažena vydavatelem zpět, jakmile se zjistí, že šlo o chybu. Toto potvrzuje samotný význam latinské předpony mis-, která znamená něco chybného (Burýšek, 2019).
Malinformace je takřka pravým opakem misinformace. Malinformace je informace, která je založena na pravdě, nebo může být i zcela pravdivá. Jejím cílem je však záměrně poškodit lidi, na které je zaměřena, nebo naopak drobným upravením textu, kde se například změní pouze autor, datum či částka (například v nějakém finančním podvodu), nasměrovat pozornost někam úplně jinam (LaGarde & Hudgins, 2021). Stejně jako u misinformace, i zde význam slova malinformace potvrzuje latinská předpona mal-, která znamená škodlivý (Burýšek, 2019).
Dezinformace je tedy v podstatě kombinací jak misinformace, tak malinformace. Přebírá však z každé pouze „špatnou“ část, tedy nepravdivost a účel/úmysl někoho poškodit (viz obr. 2).

Obr. 2 Typy zkreslení informací, zdroj: (Burýšek, 2024)
Jako příklady dezinformačního obsahu, které naplňují výše uvedené charakteristiky dezinformací, je možné uvést například propagandu, hoax či velmi moderní pojetí dezinformace v kombinaci s umělou inteligencí, taktéž nazývané deepfake.
Pokud jde o propagandu, toto slovo nebylo vždy vnímáno tak negativně, jako tomu je dnes. Termín propaganda je odvozen od latinského slova propagare (rozšiřovat, rozhlašovat) a původně byl spojován s vatikánskou kontrolní komisí Sacra Congregatio de Propaganda Fide, jejímž úkolem bylo šířit římskokatolickou víru. Původně opravdu šlo o rozšiřování/propagování bez postranních úmyslů. Postupem času však tento pojem nabyl takřka výhradně negativního významu a dnes si pod ním lidé vybaví spíše extrémní praktiky propagandy jako „vymývání mozků a manipulace s masou lidí“ než šíření něčí víry či přesvědčení. Aktuálně tedy tento pojem můžeme spíše chápat jako proces, při němž dochází k systematickému překrucování faktů a předkládání názorů toho, kdo danou propagandu využívá ke svému prospěchu (Drábik, 2014), (MVČR, b.r.).
V případě hoaxu je již relativně těžké rozhodnout, zda se jedná o dezinformaci v tom pravém slova smyslu, jak byla výše definována. Slovník totiž uvádí, že hoax je jakási poplašná nebo zavádějící zpráva, tvářící se jako pravdivá, která má za cíl zmást či šokovat čtenáře.
V angličtině byl tento pojem původně ekvivalentem pro tzv. novinářskou kachnu. Zde však není úmyslem čtenáře nějak značně poškodit nebo zdiskreditovat, spíše se zkrátka cílí, stejně tak jako tomu je u bulváru, na senzaci a vzbuzení emocí (Halada & Osvaldová, 2017). Ať už hoax považujeme za cokoliv, fakt, že se jedná o nepravdivou informaci, je zde nepopiratelný a takovéto poplašné a rádoby šokující informace by se ve veřejném prostoru šířit neměly. Je proto tedy s podivem, že v den, lidově označovaný jako „apríl“, někteří novináři záměrně tento typ zpráv publikují a zaplavují jím internet či noviny pro pobavení lidí. Ne každý je ovšem schopen rozeznat nepravdivou senzaci od pravdy, což může vést k rychlému šíření těchto zpráv, jež se z nevinné legrace mohou proměnit v hromadnou a lehce zneužitelnou dezinformaci (Researchwriter.cz, 2022).
Dalším a posledním rozebíraným typem dezinformačního obsahu je deepfake, nepravý či zmanipulovaný audiovizuální materiál (Tesař, 2022). Díky neustálému rozvoji na poli umělé inteligence, v tomto případě zejména inteligence generativní, se tento typ cílených dezinformací stává stále věrohodnějším a v důsledku toho vzniká velké nebezpečí, že se deepfake v budoucnu stane natolik kvalitním, že ho nebude možné rozeznat od reality. Je zde tedy potenciální hrozba, že ve veřejném prostoru může kolovat značné množství obsahu, který již ani nebude považován za zmanipulovaný a kvůli tomu bude ovlivňovat názory a mínění lidí tím směrem, který autoři deepfake chtějí (Kopecký, 2019).
Dle různých výzkumů jsou často falšovány hlavně materiály s pornografickou či sexuální tematikou, která může značným způsobem poškodit a ohrozit důvěryhodnost konkrétních osob, na něž jsou tyto podvrhy cíleny (Rathgeb et al. 2022). Jako ukázka může sloužit například případ útoku prostřednictvím deepfake na světoznámou zpěvačku Taylor Swift, která byla pomocí generativní umělé inteligence vykreslena v sexuálním kontextu (viz obr. 3). Tento podvrh se začal okamžitě rychle šířit sítí X, kde během prvních hodin nasbíral miliony shlédnutí a vrhal tak neprávem na zpěvačku negativní světlo (Kopecký 2024).

Obr. 3 Příklad deepfake - zmanipulovaného obsahu, zdroj: (Kopecký, 2024)
Propojení s umělou inteligencí může v budoucnu problémy falešných informací prohloubit. Jak již bylo řečeno například u technologie deepfake, zde má velký podíl generativní umělá inteligence. Co to generativní umělá inteligence je a co si pod ní máme představit?
Generativní umělá inteligence je relativně inovativní technika na poli umělé inteligence, která je schopná vytvářet obrázky, texty, zvuky atd., zkrátka cokoliv, co je možné počítačově vygenerovat. Tento typ umělé inteligence (artificial intelligence, dále také AI) se běžně učí na ohromném množstvím trénovacích dat, což jsou data, na nichž se optimalizuje žádaná budoucí funkčnost a přesnost generativní AI (Goodfellow et al., 2020). Díky tomuto množství dat, pokročilému strojovému učení a neuronovým sítím se pak z generovaného obsahu stává obsah téměř nerozeznatelný od reality a tudíž i velmi nebezpečný v oblasti dezinformací (Foster, 2019).
Konkrétněji, jedny z hlavních používaných konceptů (algoritmů), které se k vytváření generovaného obsahu využívají, jsou variační autoenkodéry (VAE) a generativní adversariální sítě (GAN) (Goodfellow et al., 2020).
Variační autoenkodéry se skládají z enkodéru, dekodéru a latentního prostoru. Princip latentního prostoru je klíčový pro pochopení autoenkodéru. Latentní prostor je jakýsi „skrytý svět“, kde jsou uloženy velmi zjednodušené verze dat, které sem vloží enkodér. Vezměme si například nějaký obrázek. Enkodér ho do latentního prostoru uloží, zde se tento obrázek rozštěpí na základní body, které si můžeme představit jako hlavní souřadnice na mapě.
Z těchto hlavních bodů, které byly základem původního obrázku, se pak tvoří obrázek generovaný, odvíjející se od toho původního, na základě dat v latentním prostoru. Enkodér tedy vkládá vstupní data do latentního prostoru a dekodér zpětně generuje data ze zadaného bodu v latentním prostoru a snaží se tak vytvořit co nejvěrohodnější obraz reality (viz. obr. 4).
Autoenkodéry jsou pro tyto své kvality nejčastěji využívány pro generování nových obrázků nebo textů s podobnými charakteristikami jako data, jež sloužila k jejich natrénování (Bergmann & Stryker, b.r.).

Obr. 4 Variační autoenkodér, zdroj: (Jordan, 2018)
Druhým často používaným typem pro generování obsahu je generativní adversariální síť (GAN), která oproti VAE funguje na úplně odlišném principu. Tzv. GANs se skládají ze dvou hlavních komponent – generátoru a diskriminátoru, jež jsou ve vzájemné soutěži. Generátor usiluje o vytvoření autentických dat, zatímco diskriminátor usiluje o rozlišení mezi skutečnými a generovanými daty (viz obr. 5). Tato soutěžní dynamika umožňuje generátoru neustále zlepšovat své schopnosti a vytvářet tak stále autentičtější data (Goodfellow et al., 2020)

Obr. 5 Generativní adversariální síť, zdroj: (Clicworker, b.r.)
Tyto principy tedy slouží jako jedny z variant pro generování obsahu, který, pokud má jeho autor špatné úmysly, se může lehce proměnit v cílený zmanipulovaný obsah a rozvířit po internetu či sociálních sítí vlnu chaosu nebo zmatku.
Jak již bylo řečeno, technologie se vyvíjí tak rychle, že bude velmi těžké rozeznat, kde je skutečně pravda a rychle a vědomě ji oddělit od lží a výmyslů. Vyvstává tedy důležitá otázka, jak tento zmanipulovaný obsah rozeznat od obsahu pravého a na co se konkrétně při jeho detekci zaměřit?
Přístupy k detekci se liší v závislosti na typu média. Jinak se bude identifikovat generovaný text, obrázek, video a audio. Pokud se jedná o prostý text, zde je při detekci důležité se zaměřit na identifikaci stylistických či gramatických vzorců, které nejsou přirozené pro text vytvořený člověkem. Například specifické repetitivní struktury vět nebo totální absence jazykových chyb mohou poukazovat na strojový původ (Zellers et al., 2019).
Odhalení falešného vizuálního obsahu se provádí tak, že se za pomoci pokročilých počítačových programů hledají anomálie, které neodpovídají přirozeným vzorcům vidění. Jednou z těchto konkrétních metod je analýza nepravidelností v pixelech nebo nesrovnalostí v osvětlení a stínech, jelikož právě tyto rysy jsou běžné u vizuálů generovaných umělou inteligencí (Farid, 1999).
Anomálie se hledají i u zvukového obsahu. Zde se detekce zaměřuje na intonaci, která může být u generovaného obsahu abnormálně konzistentní. Analytické nástroje v této oblasti se snaží nalézt frekvenční anomálie nebo neobvyklé časování ve zvukových vzorcích (Zhou et al., 2019).
Závěr
Ačkoliv se v tomto příspěvku generativní umělá inteligence vykresluje spíše v negativním světle, ve spojení s dezinformacemi a jejími novými formami, které s neustálým rozvojem AI vznikají, nemělo by se zapomínat, že s příchodem (generativní) umělé inteligence se objevuje i mnoho nových a dobrých příležitostí či inovací pro zlepšení našeho života. Je však nezbytné, stejně jako tomu je u vývoje jakéhokoliv nového produktu či technologie, nezapomínat na obezřetnost a případné zneužití. Generovat vysoce kvalitní obsah jakéhokoli typu a urychlit tak například mnohokrát se opakující úkony, je zcela nepochybně usnadněním pro lidstvo. Tvorba falešného a zmanipulovaného obsahu však mezi takovéto usnadnění rozhodně nepatří a do budoucna bude pravděpodobně vyžadovat, aby byl kladen větší důraz na rozpoznání dezinformačního obsahu od obsahu pravého.
Autor: Adam Sochor
Pracoviště: Vysoká škola ekonomická v Praze
Seznam literatury
BURÝŠEK, Jiří, 19. 7. 2019. Co je to dezinformace?. Online. Bezfaulu.net. Dostupné z: https://bezfaulu.net/clanky/o-manipulaci/co-je-to-dezinformace/. [citováno 2024-08-11].
BERGMAN, Dave a Cole STRYKR, 23 November 2023. What Is an Autoencoder?. IBM. Dostupné z: https://www.ibm.com/topics/autoencoder. [citováno 2024-08-13].
CARTER, David, June 20, 2024. Difference between Information and Data. Online. Guru99. Dostupné z: https://www.guru99.com/difference-information-data.html. [citováno 2024-08-13].
CLICKWORKER, [b. d.]. Generative Adversarial Networks (GANs)-Brief Explanation. Online. Clickworker. Dostupné z: https://www.clickworker.com/ai-glossary/generative-adversarial-networks/. [citováno 2024-08-13].
ČERNÝ, Michal, 2016. Informační systémy ve vzdělávání: Od matrik k sémantickým technologiím a dialogovým systémům pro učení. Online. Masarykova univerzita. ProQuest (distributor). Dostupné z: http://ebookcentral.proquest.com/lib/vsep/detail.action?docID=5633989. [citováno 2024-08-11].
DRÁBIK, Jakub, 2014. Mýtus o znovuzrození: Britská unie fašistů a její propaganda. Online. Univerzita Karlova, Filozofická fakulta. ProQuest (distributor). Dostupné z: http://ebookcentral.proquest.com/lib/vsep/detail.action?docID=6458500. [citováno 2024-08-12].
FARID, Hany, 1999. Detecting Digital Forgeries Using Bispectral Analysis. Online. Massachusetts Institute of Technology. Dostupné z: https://farid.berkeley.edu/downloads/publications/tr99.pdf. [citováno 2024-08-14].
FOSTER, David, 2019. Generative Deep Learning: Teaching Machines to Paint, Write, Compose, and Play. Online. O’Reilly Media, Inc. Dostupné z: https://books.google.cz/books/about/Generative_Deep_Learning.html?id=RqegDwAAQBAJ&redir_esc=y. [citováno 2024-08-13].
GOODFELLOW, Ian, Jean, POUGET-ABADIE, Mehdi, MIRZA, Bing, XU, WARDE-FARLEY et al. 2020. Generative adversarial networks. Online. Communications of the ACM, 63(11), 139–144. ACM Digital Library (distributor). Dostupné z: https://doi.org/10.1145/3422622. [citováno 2024-08-14].
HALADA, Jan a Barbora, OSVALDOVÁ, 2017. Slovník žurnalistiky. Online. Karolinum Press. ProQuest (distributor). Dostupné z: http://ebookcentral.proquest.com/lib/vsep/detail.action?docID=5325580. [citováno 2024-08-10].
JORDAN, Jeremy, 19 Mar 2018. Variational autoencoders. Online. Jeremy Jordan. Dostupné z: https://www.jeremyjordan.me/variational-autoencoders/. [citováno 2024-08-12].
KOPECKÝ, Kamil, 2019. Deep fake – Stručný úvod do problematiky. Online. E-Bezpečí, 4(1), 23–25. Dostupné z: https://www.e-bezpeci.cz/index.php/70-projekt-fake-news/1417-deep-fake-strucny-uvod-do-problematiky. [citováno 2024-08-11].
KOPECKÝ, Kamil, 2024. Negativní dopady generativní umělé inteligence budou vidět stále více. Online. E-Bezpečí, 9(1), 18–22. Dostupné z: https://www.e-bezpeci.cz/index.php/57-rizikove-jevy/3802-negativni-dopady-generativni-umele-inteligence-budou-videt-stale-vice. [citováno 2024-08-13].
LAGARDE, Jennifer a Darren HUDGINS, 2021. Developing Digital Detectives: Essential Lessons for Discerning Fact from Fiction in the ‘Fake News’ Era. Online. International Society for Technology in Education. ProQuest (distributor). Dostupné z: http://ebookcentral.proquest.com/lib/vsep/detail.action?docID=6727265. [citováno 2024-08-12].
MINISTERSTVO VNITRA ČESKÉ REPUBLIKY, [b. d.]. Definice dezinformací a propagandy. Online. Dezinformační kampaně. Dostupné z: https://www.mvcr.cz/chh/clanek/definice-dezinformaci-a-propagandy.aspx. [citováno 2024-08-10].
RATHGEB, Christian, Ruben, TOLOSANA, Ruben, VERA-RODRIGUEZ a Christoph BUSCH, 2022. Handbook of Digital Face Manipulation and Detection: From DeepFakes to Morphing Attacks. Online. Springer International Publishing AG. ProQuest (distributor). Dostupné z: http://ebookcentral.proquest.com/lib/vsep/detail.action?docID=6878098. [citováno 2024-08-13].
RESEARCHWRITER.CZ, 12. 2. 2022. Postfaktická éra: Hoax a fake news. Online. ResearchWriter.cz • Rešerše a psaní. Dostupné z: https://www.researchwriter.cz/2022/02/12/postfakticka-era-hoax-a-fake-news/. [citováno 2024-08-11].
SKLENÁK, Vilém, Petr, BERKA, Jan, RAUCH, Petr, STROSSA a Vojtěch, SVÁTEK, 2001. Data, informace, znalosti a Internet. C. H. Beck. ISBN 80-7179-409-0.
SOCHOR, Adam, 2024. Vliv umělé inteligence na důvěryhodnost informací a tvorba dezinformačního obsahu. Bakalářská práce. Vysoká škola ekonomická v Praze.
STODOLA, Jiří, 2015. Filosofie informace – metateoretická analýza pojmu informace a hlavních paradigmat informační vědy. Online. Masarykova univerzita. ProQuest (distributor). Dostupné z: http://ebookcentral.proquest.com/lib/vsep/detail.action?docID=4887189. [citováno 2024-08-10].
TESAŘ, Václav, 10. května 2022. Dezinformace a nová výzva deepfake. Online. Muni.cz. Dostupné z: https://www.em.muni.cz/udalosti/15160-dezinformace-a-nova-vyzva-deepfake. [citováno 2024-08-10].
ZELLERS, Rowan, Ari, HOLTZMAN, Hannah, RASHKIN, Yonatan, BISK, Ali, FARHADI et al. 2019. Defending Against Neural Fake News. Online. Proceedings of the 33rd International Conference on Neural Information Processing Systems. 812, 9054-9065. ACM Digital Library (distributor). Dostupné z: https://dl.acm.org/doi/10.5555/3454287.3455099. [citováno 2024-08-14].
ZHOU, Xinyi, Reza, ZAFARANI, Kai, SHU a Huan LIU, 2019. Fake News: Fundamental Theories, Detection Strategies and Challenges. Online. WSDM '19: Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining. 836-837. ACM Digital Library (distributor). Dostupné z: https://doi.org/10.1145/3289600.3291382. [citováno 2024-08-11].