Relationships of information resources: an attempt to interdisciplinary synthesis
Keywords: relationships, information resources, structures, interaction, equivalence relationships, hierarchical relationships, associative relationships
PhDr. Helena Kučerová / Ústav informačních studií a knihovnictví FF UK v Praze (Institute of Information Studies and Librarianship, Faculty of Arts, Charles University in Prague), U Kříže 8, 158 00 Praha 5 - Jinonice
"Classical science in its diverse disciplines [...] tried to isolate the elements of the observed universe [...] expecting that, by putting them together again,[...] the whole would result and be intelligible. Now we have learned that for understanding not only the elements but their interrelations as well are required."
Ludwig von Bertalanffy: General system theory (1968)
Introduction
We are likely to get across two major obstacles at the beginning of each try to solve the problems of relationships among the information resources: both the information resource and the relationship are difficult to define. The hurdles in defining an information resource are due, in addition to the broad scope of the concept, also to the variations in understanding its contents in different disciplines, reaching from the narrow documentary viewpoint of the memory institutions, down to the almost unlimited approach of the Semantic Web. For instance D. Allemang and J. Hendler declare that "in the Semantic Web we refer to the things in the world as resources; a resource can be anything that someone might want to talk about."1 The substance of this allegation is in tune with how an information resource is defined in TDKIV, understanding the same as an "information object, containing available information complying with the information needs of the user."2 Contrary to the precision seeking enumeration in the continuing part of the definition, stipulating that "an information resource can be printed, audiovisual or electronic (including resources available online)", thus in fact additionally restricting the available spectrum of the relevant information to documents, but for the purpose of this study we accept the approach represented by the present day concept of the Semantic Web. The information resources are understood in the broadest sense as documents, data, but also persons, things, concepts, terms, processes, events or services supplying information.
The cause of difficulties in defining a relationship resides in the fact that this is one of the most general categories having no superior category level; that is why there is no way of applying the classic Aristotle definition by classifying the issue in the next superior category and then determining its different specific features. An example of understanding the relationship as the most general category can be given by the conception of A. Wierzbicka, representative of the present day cognitive linguistics. In her list of the so-called elementary semantic units, i. e. simple indefinable notions that are universally present in all languages of the world, she indicates three essential representatives of relationships: type (taxonomy), part (partonomy) and likeliness (similarity).3 A relationship, accordingly, is a philosophic category, but in its applied form it is also part of the display of instruments of practically any scientific discipline. Psychology explores the relationships of persons, their interactions and roles, whereas sociology is directed to relationships in social networks and relationships of collaboration. The focus of linguistics and terminology are relations of words and verbal expressions, the focus of semantics lies in studying the relationships of concepts. The rules of correct reasoning and deriving upon the basis of relationships in the frame of formalized statements are the domain of logics. The graph theory offers a theoretical foundation for the "materialization", visualization and exploration of relationships. As to informatics, it deals with technological solutions of the implementation of relationships in digital environments. Of course relationships are also an issue of interest for diverse applications and engineering fields – let us mention, just by way of example, the field of business informatics specialized in the administration of data about customers, in particular CRM – customer relationship management. The accompanying phenomenon of a concept used to such width is its lack of terminological unity. The issue called relationship in this study is given other names by some authors, such as predicate or property, whereas relationships on the web are currently called reference or link. Especially in the context of information technologies heed should be paid to the plurality of meanings of the term relation. In addition to the current understanding it can mean the concept of mathematical relation as a result of a cartesian product, representing the theoretical foundation of relational databases. Also in the "non-professional" natural language the broad extension of the concept of relation is perceived, being the actual cause enabling definitions in very general terms only, such as on the level of a nominal definition (formulating the same in other words). For instance the Dictionary of standard Czech offers the following explanation: a relation is "an interconnection, a continuity or coherence between phenomena, a ratio", or the Dictionary of the Czech Language defines a relation as „the circumstance that somebody or something has some connection or link with somebody or something else".4
The intention of our study resides in summarizing the theoretical principles of relationships formulated by various disciplines, followed by a synthesis and application to the field of information resources. The text of the study is divided in three parts. The first part provides a general delimitation of relationships, the characteristics of ways of their expression and a review of their properties. The second part offers a selection from outstanding contributions to the research of relationships, supplied by diverse scientific disciplines. The third part contains a review of relational taxonomies within the information science and a draft of own framework taxonomy, along with suggestions concerning further explorations.
1 General characteristic of relationships
The best suited approach for the purposes of this study appears to be the systemic one that can be singled out of the plurality of field specific relational concepts. Indeed, the general system theory or the system science has been the engine giving rise to the importance of interrelationships of elements of the entities under scrutiny; opposed to the Newtonian mechanistic approach trying to cognize a complex whole by splitting it to smaller parts, it has highlighted the learning of the relationships between these parts . The image of the world based upon the systems approach consists of entities (elements), functions (processes), their features and their mutual relationships. Contrary to the concrete Newtonian analysis, physically separating single elements to be investigated (e.g. by filtration of liquids), the systems approach is an abstract one; instead of physical elements it focuses upon logical ones, the analysis and the synthesis are brought about by mental processes. The same as systems do not exist independently and are products of the human mind, also the relationships within a system are mental artefacts and constructions that are deliberately created in the process of cognizance, representation or drafting of a novel reality.5 We should also bear in mind that the role of relationships within a system is not only a static one in the sense enabling a certain structuring, but that the relationships are also endowed with dynamic and interactive functions.
1.1 Ways of expressing relationships
Relationships encountered in the practice can be expressed with various degrees of formalization. 1. A tacit, unexpressed relationship exists only on a material level. Just a few examples of entities with unexpressed relationships: "Peter", "George", "heart", "man", "book", "lending". 2. An implicit, verbally expressed relationship uses means of the natural language. In such ways of putting things the relationships are integrated so closely with the other elements of communication as to form compact wholes requiring to be analyzed. Examples of implicitly expressed relationships: "George´s son Peter has been lent a book." "Man George has heart." "A lost book cannot be lent." 3. An explicit, logical and unambiguously expressed relationship is markedly separated from the other elements of communication. It can be expressed verbally by statements of formal language or graphically. Examples of explicitly expressed relationships can be seen in Fig. 1.

Fig. 1
As shown by examples in Fig. 1, both static and dynamic relationships can be formalized. The static relationships have been graphically expressed with the class diagram of the modelling language UML, more closely described in part 2.5, dynamic relationships are expressed by a statechart diagram and a diagram of activities in the same language. A simple formalized language is used for the text expression of both types of relationships where the relationships are designated by terms enclosed in angle brackets. The formalization of explicit text recording of relationships can continue down to the level of entries by way of symbols agreed upon, e.g. symbols of formal logics or of programming languages. The advantage of such recording resides in that it enables automatic inference, i.e. deriving new statements out of the existing ones thanks to the unambiguous and explicit expression of relationships, which, in the consequence, results in the creation of new knowledge. An example of inference can be offered by the short sentences above, such as: "Since every human has a heart and Peter is a human, also Peter has a heart". Whereas a man with natural intelligence can derive such finding also from an implicit expression in a free text (and a man knowledgeable of the unexpressed context and endowed with intuition could master it upon the material in the first example lacking the expression of relationships), the computer applications based upon artificial intelligence require relationships expressed explicitly, fully and unambiguously. Yet another method of formalization can be a mathematical approach abstracting relationships between the elements to a level enabling their quantitative expression. Also a quantitative expression of a relationship is useful, as it enables processing by tools for which the intentional semantic characteristics of the relationship are unintelligible. In addition to that the quantitative values allow, under certain conditions, extrapolating to quality out of quantitative data.
An analysis of explicitly expressed relationships will allow us to ascertain that relationships expressed formally to the full are composed of three key components: 1. relationship – connection (e.g. "is", "has", "paternity", "lending"), 2. thing (participant) in the relationship (e.g. "man", "Peter", "George", "Heart", "Book") and 3. role of a thing in the relationship (e.g. "son", "father", "follows after", "precedes").6
1.2 Definition of a relationship through the mediation of its features
In much the same way as in any entity upon which systems approach is applied, we will define also the relationships by the intermediary of their properties. The importance of relationships for investigating reality, as indicated in the motto of the present paper, however, does not mean to say that they can be handled in a fully abstract way. In order that the relationship may give any sense, we should know what "things", i.e. elements or processes, are joined by way of such relationship. All entities on the most general level can be divided in two groups for the purpose of defining their relationships: abstract concepts (categories, classes, sets of objects) with abstract relationships, on the one hand, and concrete individuals or instances (single objects) with concrete relationships. The entities of both groups are intelligible, definable and describable thanks to their properties (i.e. intensions). Some properties can be shared by a plurality of entities at a time, and exactly these create the semantics of what we call relationship.
For the purpose of our review of selected features of relationships we will consider two groups of properties – formal (extensional, syntactic) and content oriented (intensional, semantic). The group of formal properties comprises: symmetry, direction, degree, multiplicity, obligatory membership in the relation, transitiveness and dynamics. The content properties – permanence of relationships (paradigmatic/syntagmatic relationships) and semantics of relationship are given – considering their importance – separate parts of this study (2.2 and 2.3). It can be stated – in addition to acknowledging their general importance for cognizing a relationship – that both the formal and the content properties of relationships have direct impact upon the way of representation (i.e. instantiation) in computer systems.
Symmetry of relationship: When determining this property, we examine the roles of the entities participating in the relationship. If their roles are equal, we declare the relationship as symmetric, whereas if they play different roles, the relationship is asymmetric. For instance the relationship of paternity is asymmetric, whereas the relationship of siblings is symmetric.
Direction of relationship: We differentiate between one-way and both-ways relationships. For instance the relationship lending – losing is unidirectional, whereas the relationship lending – returning is bidirectional.
Degree of relationship: For designating the degree of relationship or the number of entities entering into a relationship the terms arity, or possibly dimension or degree of relationship are used, sometimes also valence. In general the relationships are designated as n-ary (n-dimensional), n being the number of participating entities. A relationship with one entity is designated as a unary relationship. Such relationship can be understood in two ways: 1. as a relationship of instances or individuals of the same class, for instance the relationship of the first and second edition of the same title; it can be also called iteration or recursion; in the graph theory the edge representing such relationship is called loop, and 2. as a relation of a class and its property (also unary predicate); a unary relationship in this sense is represented, for instance, by the statement "the book has a dimension (e.g. 20 cm)". A relationship of two entities is called binary (with two members, double, two-dimensional), the relationship of three entities, in analogy, is called ternary (with three members, triple, three-dimensional) etc.
Multiplicity of relationship: The number of elements in the sense of instances or individuals of a concrete class participating in an abstract relationship has a special term multiplicity or cardinality. A number larger than 1, as a rule, is not expressed numerically, but by way of a generalizing symbol, such as N, M, , . The relationships are differentiated also thus 1 : 1 (one–to–one), 1 : N (one–to–many), N : 1 ( many–to–one), N : M (many–to–many). If considering an asymmetric, bidirectional and binary relationship "a reader reads a book", then cardinality 1 : 1 would mean that one reader is just reading one book, cardinality 1 : N would allow one reader to read more books, cardinality N : 1 would express a situation when there is a plurality of readers reading one book, and cardinality N : M would apply in the case when one reader reads more books, and at the same time one book is read by a number of readers.
Obligatory membership in a relation: Another quantitative parameter of a relationship is the so-called obligatory participation. The possibility of non-existence of a partner entity is verified (does the occurrence of one entity require the occurrence of the other entity – for instance must every book have its reader?) According to the result the relationship is then designated as obligatory (total, full) or optional (partial).
Transitivity of relationship: The transitivity or transferability of a relationship can be expressed by the formula: if A→B→C, it is valid that A→C. Sometimes also a differentiation is possible between the transitivity of a relationship and the transitivity of properties of the participating entities. For instance in the FRBR model wherein the work D has been realized by expression V, and this expression V has been embodied by manifestation P, it can be derived that P is not only a manifestation of expression V, but also a manifestation of work D. The transfer of semantics of an abstract relationship of classes to the concrete relationship of their instances can serve as another example of transitivity.
Dynamics of a relationship: As mentioned above, the relationships can be divided to static and dynamic ones, in tune with the systems approach. The static relationships depict the relations of elements in a system. They are also called structural relationships, as they allow us to describe the structure of a given system (i.e. a relatively stable arrangement of elements), and thus to understand the sense of the comprised things. This is typically achieved by way of construing a conceptual system representing concrete things within their context. The dynamic relationships depict the relations between the processes in a system. They can show the development and changes in the course of time, such as by the intermediary of process models based upon a network diagram. This diagram depicts the dynamic relationship as an edge or a path; in combination with nodes standing for the participants of the relationship diverse sequences, splitting and joining of processes can be represented. Dynamic relationships are also called interactive, since they enable communication and interaction with the resource (for instance a hypertext link allows the browser to "read" the resource, i.e. ensures access to the resource).
All above formal features can be combined7 with one another and, accordingly, any relationship can be specified by adding the relevant value of each of the properties. Thus, by way of example, the relation "Man has a heart" in Fig. 1 can be described as an asymmetric both-ways binary static relationship 1 : 1 with optional participation of the entity man and obligatory partnership of entity heart (based upon the fact that every human has a heart, but a heart need not always be only a component part of man). The relationship „has a heart" is transitive in the direction to the relationship "Peter is a man", but it is not transitive in the direction to the relationship "Man borrows a book" (the circumstance that the book is borrowed by a man having a heart does not mean to say that also the book has a heart).
2 Review of approaches to the examination of relationships in diverse disciplines and fields
2.1 Semantics of relationships in the semiotic triangle
A well proven instrument for modelling the function of a sign in understanding the world and in communication, i.e. reflecting reality in the thought and its lingual expression, is the semiotic triangle. The opinions of protagonists of different theories in linguistics and semiotics as to the delimitation of the key components of the semiotic triangle are not unified. For the purpose of this text we have selected such choice of relationships and their interpretations that can be applicable in the follow-up for considering the relationships among information resources. For the benefit of compliance with the approach used in the terminological systems as well as the knowledge organization systems summarized in part 2.3 the apexes of the triangle are occupied by entities "Thing", "Concept" and "Designation". The relationships are marked with arrows and numbered. As obvious in Fig. 2 there are both relationships between diverse types of entities, and between the entities themselves. The first group are binary asymmetric bi-directional relationships between things and concepts, concepts and designations, and designations and things. The second group comprises recursive relationships of concepts, designations and things that can be both symmetrical and asymmetrical.
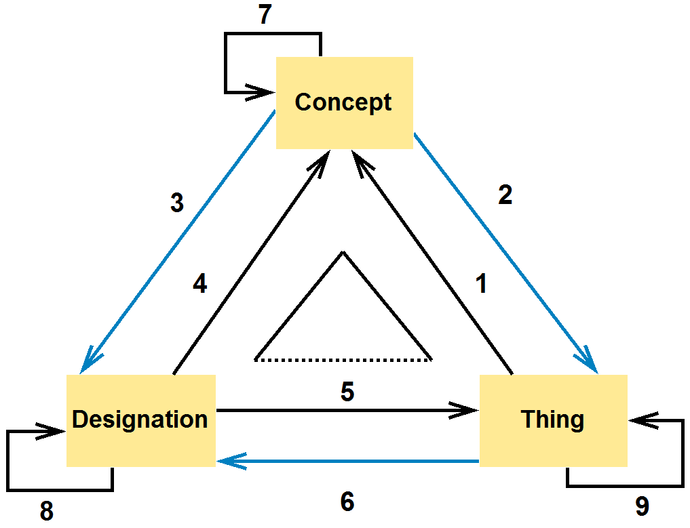
Figure 2
Comments to the relationships shown in the semiotic triangle in Fig. 2:8
1. Relationship thing – concept is called conceptualization, i.e. a conceptual expression of reality. The thing in this relationship is introduced as an empirical model of the concept. The concept, accordingly, functions as a model of the thing in the sense of its representation. The sum of the characteristics of the thing comprised in the concept is called intension. The relationship thing – concept can have any cardinality, namely from 1 : 1 (1 thing –1 individual concept), over N : 1 (a number of things – 1 general concept) down to the relationship of semantic heterogeneity 1 : N (1 thing – a plurality of concepts).
2. The relationship concept – thing is designed as instantiation or as illustration. The thing in such relationship figures either as a physical instantiation (embodiment) of the meaning of the concept or as its exemplification (introduction of an example). The concept has the function of a model in the sense of its template (plan). The set of things represented by the concept is called extension. The relationship can have cardinality 1 : 1 (1 individual concept – 1 thing) or 1 : N (1 general concept – a plurality of things).
3. The relationship concept – designation is called expression, or possibly also name. E. Svenonius uses the term relational semantics9 for these cases. The relationship with cardinality 1 : 1 is called mononymy (1 concept – 1 designation), the relationship 1 : N (1 concept – a number of designations) is called synonymy. Synonymy has an adverse impact upon the recall rate in the retrieval systems.
4. The relationship designation – concept is usually called meaning or sense. According to E. Svenonius the relationships designation – concept create the so-called reference semantics. The relationship with cardinality 1 : 1 is called monosemy (1 designation – 1 concept), whereas the relationship 1 : N (1 designation – a plurality of concepts) is called polysemy or homonymy. Polysemy/homonymy has adverse effect upon the precision in the retrieval systems.
5. The relationship designation – thing is called denotation, if such designation is related to a class of objects, or reference, if it is directed to an individual object.
6. The relationship thing – designation is called representation.
7. The relationship concept – concept has abstract character and is called conceptual relationship. Relationships describing hierarchical relationships between concepts with semantically broader and narrower scope, as well as associative concepts, are interesting from the viewpoint of handling semantic problems.
8. The relationship designation – designation, considering the one with highest frequency among the designation systems, is usually called lexical. The mutual hierarchical designation relationships are called hyperonymy – hyponymy and holonymy – meronymy, and troponymy is the usual designation for the hierarchical relationships of verbs.
9. The relationship thing – thing is concrete; we mention it for the sake of completeness. Much the same as concepts reflect the properties of things, the mutual relationships between concepts should be based upon the ascertained relationships of things.
2.2 Paradigmatic and syntagmatic relationships in the language
The concepts of paradigm and syntagm, together with the concepts of synchrony and diachrony, are seen as the pillars of modern linguistics. The classical linguistic theory of Ferdinand de Saussure recognizes the paradigmatic relationships (designated by Saussure as associative) as the basic structure of what he calls "langue" (language, system), whereas the syntagmatic relationships structure the so-called "parole" (speech, text).10
Paradigmatic is the designation given to relationships whose meaning is relatively independent of the context. They serve to construe generalized semantic systems for multiple utilization (such as thesauri, intended to express paradigmatic relationships according to the standard ISO 25964-1) by using lingual means to express units of contents, i.e. concepts.
Syntagmatic (syntactic, contextual) is the designation given to relationships among a plurality of lingual elements in a concrete expression (such as in a sentence, in an query, in a heading or entry). In contrast to paradigmatic relationships they serve to construe unique systems or ad hoc units whose meaning varies in accordance with the context in which they have been applied. In other words they enable repeated utilization of semantic elements of the language in diversified connections. Naturally, the possibility of joining a certain lingual element with other elements so as to create a reasonable whole is not unlimited. For instance the verb "to open" can be combined with words "book, (computer) file, publication, journal, newspaper, letter, folio", but it is less suitable for words "picture, film, Internet, interview, billboard, author, Police, TV channel ČT1 , paper, radio, document", although all these words concern information resources.
Sometimes we can come across the designation of paradigmatic relationships as semantic ones, but also syntagmatic relationships have a certain semantic dimension. Due to frequent usage some combinations that were formed ad hoc originally can "grow together" to the extent of not being perceived as the result of some combination, but as a separate semantic paradigm (such as "offside" etc.). The interconnection of both types of relationships was established by Saussure11 already and Roman Jakobson followed in his footsteps. In his study "Two aspects of language and two types of aphasic disturbances" Jakobson maintains that there are two references to interpret the sign – the one is selection, i.e. choice of mutually replaceable semantic equivalents within the same language (Jakobson uses the term "code"), and the other is a combination to form a topical grouping within a certain context.12 Namely, we can conclude that each element of a lingual expression lies at the intersection of the paradigmatic axis (the so-called axis of equivalence, an option from the given possibilities of expression) and the syntagmatic axis (the so-called axis of combination, of interlinking with the other components of the communication), the actual meaning being derived from both these dimensions.
2.3 Lexically semantic relationships in terminological systems and in the knowledge organization systems
This part offers a summary of the general conception of lexically semantic relationships, as standardized by the international standards for terminological work ISO 70413 and ISO 1087-114 and in ISO 2596415 for thesauri and further controlled vocabularies used for organizing knowledge and searching for information. ISO 704 in the recent version of 2009 is already the third revised edition of this standard devoted to the principles and methods of terminological word, whose first edition was dated 1987 and the second in 2000. The terminological standard ISO 1087-1 comprises a vocabulary explicating concepts from the field of terminology. Its verbal part is accompanied by an appendix with diagrams of concepts, illustrating the conceptual relationships of the contained terms in graphic form. It was published in 2000 and its Czech translation together with national comments was issued in 200216. ISO 25964 is a standard having two parts whose history goes back to the beginning of the 70ies of the 20th century. The 2011 and 2013 editions represent the actual culmination of efforts of many outstanding institutions (such as UNESCO, IFLA, NISO17, BSI18) and of experts associated in the subcommittee of the technical commission ISO/TC 46 Information and documentation, of setting the rules and methods of design, utilization and administration of the thesauri. It reflects amendments due to the introduction of information technologies in this field: software applications for the creation and use of thesauri, technology of full-text searching etc. The scope of the standard has been widened from the original strict focus upon the design of thesauri in the direction towards a more general conception, as applicable for a broader spectrum of types of controlled vocabularies and other knowledge organization systems. The second part of the standard, focussing upon interoperability, has separate chapters dealing with classification schemes, taxonomies, subject heading schemes, ontologies, terminologies, name authority lists and a synonym rings.
All the above standards are examples of practical application of the semantic principles, as indicated in parts 2.1 and 2.2 of the present study, namely the work with concepts and terms. Their character makes them suited for practical activities; concretely ISO 704 and ISO 1087-1, for the creation of terminological conceptual systems, and ISO 24156, for the development and administration of knowledge organization systems. There is a conspicuous similarity of these groups of standards, and namely both as to the types of comprised relationships and the description of their semantics, obviously due to their empirical character based upon the direct practice of the work with concepts. They agree also in the pragmatic expression of the purpose of the explicit description of relationships in the terminological systems and the systems of knowledge organization, which is a certain disambiguation, i.e. the conversion of the relationships between the designation19 and the concept to the 1 : 1 ratio. The prerequisite is not only the solution of problems of 1 : N relationships, accordingly of synonymy and homonymy or polysemy, but also the problem of indefiniteness of meaning of quite a number of concepts; a help for the solution can be found also in integrating a vague concept into some concrete context (for instance the meaning of the word "good" will obviously differ in the context of ethics, in the system of university classification or in the field of culinary descriptions). Both the two terminological standards and ISO 24156 devoted to thesauri focus upon the three most important lexically-semantic relationships: equivalence, hierarchy and association.
2.3.1 Relationship of equivalence
The relationships of lexically-semantic equivalence in terminological systems fall into the category of designation. ISO 1087-1 defines equivalence as a relationship between designations in different languages representing the same concept. ISO 25964 differentiates, in the knowledge organization systems, between the equivalence of terms in a single language or multi-language context in the sense of ISO 1087-1, and between conceptual equivalence. According to ISO 25964 a relationship of symmetric term equivalence can comprise synonyms and quasi-synonyms, specific terms subordinated to terms expressing a broader concept and specific terms expressing compound concepts represented by combinations of two or more terms (the so-called compound equivalence).An asymmetric term equivalence is a relationship between a preferred and a non-preferred term, or possibly between a variant or alternative name and a name preferred in a set of authorities. A relationship of conceptual equivalence can be established in the course of the so-called equivalent mapping of concepts between different knowledge organization systems (e.g. between two different thesauri). It is obvious that semantic equivalence in this context does not mean identity; the meanings of entities participating in such relationship, can differ. The ISO 25964 standard directly specifies the degrees of inter-lingual and conceptual equivalence for differentiating between the extent of similarity of the participating elements: exact, inexact, partial, broader/narrower, non-equivalence.
2.3.2 Relationship of hierarchy
The standards ISO 1087-1 and ISO 704 as well as ISO 25964 correspond in considering hierarchy as a relationship of concepts. In general they delimit the same as the relationship of inclusion20 in the sense in comprising the scope of the subordinate concept into the scope of the superior one. ISO 25964 determines that a relation of hierarchy should be based upon degrees or levels of superordination and subordination, wherein the superior concept represents a class or a whole and the subordinate concepts represent members of the class or parts of the whole. It is recommendable to define this relationship only among concepts of the same category.21 All standards differentiate between generic and partitive hierarchy, and in addition to that they also define the so-called instance relationship between a class and its instance; in agreement they all consider it as a specific case of a generic relationship.
The designation generic relationship is derived from Latin (genus – species); further there is a differentiation between general – special (subsumption), generalisation – specialisation /specification, supra-type – infra-type, superclass – subclass, hyperonymy – hyponymy, inclusion (set – subset). Various alternatives can be encountered, such as "is a", "is-a", or "ISA" ("is", possibly "is a type"). ISO 25964 suggests using the aid "all – some" for the test of validity of generic hierarchy. Its application on the pair of concepts vehicles and trains would look like the following: all trains are vehicles, some vehicles are trains. A seemingly analogous pair of concepts, however, trucks and trains, does not pass this test: only some trains are transport vehicles for loads, some load transporting vehicles are trains. Under ISO 704 the validity test of a generic relationship is the existence of inheritance – all subordinate elements should possess attributes of the superordinate elements; in addition to the inherited characteristics, "the offspring" should be endowed by at least one specific delimiting feature.
Partitive relation is the relationship whole – part of it, and is sometimes also designated as holonymy – meronymy. In contrast to the generic relationships the partitive ones do not enable the application of inheritance and transitiveness or inference derived from the same, either; a part can possess its specific features differing from the properties of the whole. This disables the association of parts belonging to one whole by way of certain common features – the only link is the appurtenance to the given whole. ISO 25964 recommends to specify partitive relationships as mono-hierarchical, i.e. a part should always belong exclusively to one whole. A relatively small circle of entities can fulfil such requirement, and the above standard enumerates them in part 10.2.3.1: systems and organs of the body, geographical locations, disciplines or fields of discourse, hierarchical social structures.
Relationship class – instance (instance relationship) determines whether an individual object appertains to the given class. This is a difference against the generic and partitive relationships concerning abstract relations between classes in the sense of concepts representing sets of objects. Yet another difference between a class and an instance can be seen in that whereas classes have designations, instances and individuals have proper names.
2.3.3 Relationship of association
All standards define this relationship only very generally and, in principle, by the process of elimination – according to the standards any semantic relationship that is neither equivalent nor hierarchic, can be called associative. ISO 10871-1 suggests the division of the associative relationships into sequential ones (follow-up relationships) with the subtype of temporal relationship, on the one hand, and causal relationships, on the other hand. ISO 25964 does not offer any normative typology of associative relationships, though, but in part 10.3 it indicates some typical examples: associations of terms and concepts with overlapping meaning, scientific discipline and the object of studies, or a phenomenon, operation or process and their agents or instruments, an action and its product, an action and its addressee and target, objects and materials and their decisive properties, an artefact and its parts, concepts joined by causal connection, an object or process and means against the same, a concept and a unit of measure, a composed term and a noun forming its nucleus, an organism cultivated out of some other organism or a substance derived from another substance.
2.4 Relationships in data structures
Whereas our above deliberations have been carried on mostly upon a theoretical level, the data structures will lead us to the physical instantiation of relations in digital environment. These physical forms of data relationships have direct impact upon the effectiveness of both basic functions ensuring access to the organized data: collocation and navigation. Collocation consists in static aggregation of semantically linked data, whereas the substance of navigation is a dynamic movement upon an existing path leading to semantically relevant data. In the following review we will direct our attention to these basic general types of data structures: linear, tree-like, networked and relational.
Linear or sequential structure is the historically oldest method of data organization. It is closely connected with restriction from the "pre-computer" era, namely the oral and written communication as well as the restrictions of the early stage of development of information technologies, when data would be registered one after the other upon a magnetic tape and for searching the whole tape had to be sequentially re-wound. There is no mutual relationship between such elements except for the order of their saving (relation 1 : 1 – each element can possess 1 following and 1 preceding element to the maximum, possibly 1 supraordinate and 1 subordinate element). The only advantage of a linear structure seems to be the simplicity of design. Anything else are drawbacks only: the impossibility of expressing relationships 1 : N and N : M between the elements (only for the price of data redundancy, which again causes trouble during updating; e.g. if we wished, in a linearly organized file of bibliographic entries, to register a plurality of books written by the same author, his name must be repeated for each further title.) There is no way of direct retrieval of a given element; the only access is sequential search through the whole file. Traditional application fields of linear structures in the information practice are the bibliographic formats MARC that are founded upon the ISO 2709 standard. Another domain of utilization is seen to be data backup by sequential saving on magnetic tape. Linear structures complemented with sophisticated indexing files, however, are the basis of full text technologies of the present day.
The tree structure enables the link of any data element by way of a unidirectional relation directly or indirectly with a plurality of elements on a lower lever, but only with a single element on a higher hierarchic level. The relationships can be both generic and partitive, and also relationships of the type class – instance22 are possible. On the one hand side the redundancy of data can be thus reduced (each superior element is introduced only once, in spite of being linked with more subordinate elements), and on the other hand data retrieval can be accelerated due to the fact that there is no searching in the whole file; the relevant branches of the tree will do. However, direct access to data on more distant levels is not possible; it is necessary to undergo the complete path leading over the levels in-between. Substantial parts of the tree structure are linear chains enabling navigation. ISO 704 calls the linear chains in the hierarchic terminological structures the sequence of concepts. Whereas the vertical series of concepts reflects their hierarchic relationships, the horizontal line of concepts having an identical directly superior element, comprises a set of coordinate concepts on the same level that is designated as field in ISO 25964. The tree structure is very well adapted for data that are naturally organized in a hierarchical way, i.e. they demonstrate relationships of subordination and superordination, yet they do not allow the relationships N : M between the elements to be expressed easily and without duplicities. The speediness of the tree structure for data access is utilized in auxiliary indexing files. The documents of the HTML and XML type (whose structure is based upon the principles of the SGML23 language) are doubtlessly the most important application field of the tree structure at the present day.
The network structure is the only one enabling the expression of bi-directional relationships 1 : N and N : M between the data without redundancy – each element can be linked arbitrarily with all other elements. The search is very quick; not the whole file being under scrutiny, the direct path to the given element can be followed, as determined by the defined link. The speedy access by direct jumps, anyway, is enabled only upon paths prepared in advance; ad hoc queries require more steps to be done. Network data structures are the basis of graph (also NoSQL) databases, and are especially connected with the World Wide Web; from the very beginning of its existence it enables the linking of documents by way of hypertext references. These simple relationships on document level without any semantics (the hypertext reference only links the documents without hinting to the importance of their relations), are in the process of change at the present day thanks to the technologies of the Semantic Web, being now complemented by the option of expressing the relationships of single recorded pieces of knowledge, including the respective semantics. The standard is the RDF language (Resource Description Framework) with a simple triple syntax of three members: subject – predicate (i.e. relationship) – object. The nodal points of the RDF graph are subjects and objects identified by means of URI, and also the edges of the diagram represent predicates identified by URI.
The relational structure is also capable of expressing relationships N : M between data, yet it achieves the same by other ways than the network structure. Data of entities participating in the relationship are organized in two-dimensional tables wherein collocation instead of navigation takes place: data of the same type are located in columns, whereas the lines create the so-called arranged n-tuples (this general expression denotes doubles, triples, quadruples and further analogies) comprising values of the properties of some object. An advantage from the user´s viewpoint is the relative ease of the relational structure for retrieving, but on the other side it is the cause of high claims, as regards memory and performance of the computer and low effectiveness of searching. The latter is not achieved by navigation, but the program gradually selects (and draws into its memory) whole sets of data, and only then it chooses the relevant data out of those files by set operations. A typical field of application are relational databases making use of the standardized SQL language.
Linear, tree-type and network structures have one common foundation in the theory of graphs: they consist of a pair of construction elements node – edge. The node represents the entity participating in the relation and the edge the actual relationship. The edges can be oriented or without orientation, which enables the differentiation between symmetry and asymmetry of the relationship. Moreover, they can be evaluated, which adds also semantics to the relationship they represent. Such pairs node – edge can create sequential chains of arbitrary length or paths, but they can be also used for construing more complex tree or network structures A physical implementation of a node is a data object, whereas the implementation of an edge, called reference, is a special data item in the resource node, containing the identifier of the target node. The graph structures are governed by the principle of pre-coordination: the relationships are defined explicitly and permanently prior to the query on the level of entries or documents (the reference contains the identifier of the connected data object) in all anticipated directions and, accordingly, the mutual relationships between the elements can get very complicated, especially in the case of a network structure, and are difficult to analyze. Subsequent changes of the structure and expressing other relationships between the elements require physical "re-arrangement" of the whole file.
Contrary to the above structures the relational one is based upon a thoroughly different principle – drawing from the theory of sets and the mathematical theory of relations. Such relation is the result of a cartesian product over sets of data, the so-called domains. The differing theoretical foundation of relational data structures is reflected also in the way of the physical implementation of relationships – the interlinking is defined also by way of relations between the items (concretely, between the pair primary – foreign key; the reference contains the value of some of the attributes of the connected record). The contribution of this solution resides in the flexibility of expressing the relationships; these are namely defined only at the moment they are required for answering a query, but not in advance. In this respect the relational data structures are conform to the post-coordination principle. An undoubted asset for the user is seen both the simplicity of designing relational tables and easy changes of the structure, consisting just in adding or deleting a column in one table, without any impact upon the other tables.
2.5 UML notation for modelling the relationships
UML (Unified Modelling Language)24 is a standardized language conceived for enabling and simplifying communication for the development of diagrams in object oriented models describing real problems and expressing the results of their analysis, as well as drafts for solving the same by way of information and communication technologies. The systems approach applied in modelling allows the user to model objects (entities), classes, attributes, operations (functions) and relationships among them. The basic lexical units of the UML language are icons (forms, graphic symbols), conjunctions and chains of signs. They are usually represented by diagrams based upon the principles of graph theory. The icons form the nodes of the diagram and their connections are edges representing the relationships of the entities depicted by the icons. UML does not specify one universal diagram for all types of models, but offers a set of fourteen specialized diagrams for various tasks and phases of system modelling. The diagrams are divided in two groups – diagrams of structure and diagrams of behavior and interaction. This classification corresponds with the dichotomy of static and dynamic relationships, as introduced under part 2.2.
UML is traditionally used for designig information systems and in software engineering, however, its field of application get constantly wider, as evidenced also by the recently adopted international standard ISO 24156-1, specifying the utilization of UML in terminology work25. The contents of this standard is a user defined profile, adapting the original semantics to the diagram of the UML classes for application in the development of conceptual diagrams in accordance with terminological standards ISO 704 and ISO 1087-1, as have been introduced in part 2.3. Yet another example of the utilization of UML in the field of work with information is the data model of thesaurus26, elaborated in ISO 25964-1.
The class diagram in UML is of crucial importance for the illustration of the static relationships, and the most essential diagrams enabling the depiction of dynamic relationships are the diagram of activities and the statechart diagram. The graphic representations of various types of relationships in these diagrams with short comments concerning their importance are shown in Fig. 3.

Figure 3
A class diagram is a depiction of the static structure of a system by the help of classes composed of attributes (data) and operations (processes) and through the intermediary of relationships between those classes. It disposes of tools for the expression of all three key types of relationships – equivalence, hierarchy and association. The relationship of equivalence of objects having the same propertie is expressed by their being classified in one class. As can be seen in Fig. 3 where there is, along with the UML-terminology, following a slash, also the terminology used in the user profile ISO 24156-1, the class in UML is an analogy for the concept, as understood by terminological standards ISO 704 and ISO 1087-1, and by ISO 25964. The relationship of generic hierarchy in UML is expressed by the symbol of generalization, whereas the relationship of partitive hierarchy has at its disposal two symbols – aggregation and composition, differing as concerns the extent of dependence of the parts upon the whole. UML enables modelling of both mono-hierarchical, and poly-hierarchical relationships. As a rule, the relationship of instance hierarchy is not depicted in the class diagram, but of course separate instances can be modelled in the diagram of objects.27 The relationship of association in UML is expressed by a symbol of the same name. As has been mentioned already, the instance of each class in UML are data objects. A generic relationship is instantiated by transfer (i.e. the transitivity) of features of a generic class onto the objects of the specific class, thus enabling inheritance. The instances of both partitive and associative relationships are links between the objects instantiated from the classes taking part in the relationship.
A statechart diagram depicts the dynamics of change of the object, whereas a diagram of activities serves for modelling the mutual relationships of the processes within the system, i.e. the relationships of follow-up and of parallelism in time. In addition to the orientated edges both diagrams dispose also of symbols enabling the depiction of alternative possibilities of the course of the modelled processes and their synchronization.
3 General taxonomy of relationships applicable to the relationships of information resources
There is no doubt that learning the relationships of information resources has rich usage in the field of information science and in practice. The relational analysis investigates the extent of connection of a given resource with other resources (such as documents, people, disciplines, organisations…), visualizing the same by means of communication or social networks or maps. The evaluating analysis, executed by methods of scientometry, bibliometry or citation analysis, serves as an indicator of productivity, quality, importance, influence (such as influencing documents, persons…).The comparative analysis enables the evaluation of relevance by examining the relationship between information need and the contents of the resource.
When deliberating upon the relationships of entities falling into the broadly delimited category of information resources, a number of things (participants) in mutual relationship can be considered: a vast group of documents or bibliographic entities – works and their expressions (identified via DOI28, VIAF29, ISTC30, ISAN and V-ISAN31, ISWC32), manifestations and items of works (identified via ISBN, ISSN, GTIN33), parts, volumes or components of works (with identifiers DOI, SICI34), collections and services (identifier ISCI35), persons, such as authors (with identifiers IČO36, VIAF, ISNI37) or users, organisations (identified, e.g., via IČ38, DIČ39, GLN40, VIAF, ISNI, ISIL41, library signs), themes, objects, contents or genres (identified by their titles or names), but also formats and data structures, signs and elements of language (words, collocations, statements, sentences, enquiries, references, citations, paragraphs, texts).
It is obvious that the scale of such entities is immensely broad, reaching from physical objects (analogue or digital ones) down to abstract concepts. The range of their relationships is not less diversified. Both abstract relationships of entities and concrete relationships of their instances can be considered, they can be mutual (such as unary relationships author – author, theme – theme), or combinational (such as author – work, work – theme). In addition to that the entities entering a relationship tend not to be black boxes, but have their internal structure. The internal relationships of the participating entities affect also the nature of their reciprocal relationship. Some relationships of information resources with entities outside of their domain need not be uninteresting, either (such as author – place of birth).
Standard ISO 25964, mentioned in part 2.3, is not the single manifestation of the information science experts´ concerning the problem of relationships. The relational typology of information resources has been studied by numerous authors, while their approach is often seen to differ, depending upon their philosophical platforms, and also the purpose for which they define the relationships. Let us offer, by way of example, the contrast between the extensive reviews of relationships defined within the framework of the thesaurus Agrovoc42 or the taxonomy of subject relationships prepared by D. Michel for a section of ALA, Association of Library funds and technical services, in 199643, on the one hand, and the very economic list of only three types of relationships in the Gene ontology44, on the other hand. Important achievements in the theoretical domain are the taxonomies of bibliographic relationships by Barbara Tillett and the review of relationships worked out within the FRBR model.
B. Tillett, in her dissertation of 198745, executed an analysis of relationships comprised in cataloguing rules; she first published the results in 199146 and a transformed version, complemented with concepts of the FRBR model, followed in 200147. The taxonomy consists of seven types of bibliographic relationships: 1. equivalence relationships – copy of the same manifestation (reproduction, facsimile, reprint, micrographic copy etc.), retaining the same contents and author´s responsibility, 2. derivative relationships, in UNIMARC format called horizontal – modification of the bibliographic unit based upon the given work (versions, translations, summaries, adaptations, changes of genre, such as dramatization, paraphrase etc.), 3. descriptive (reference) relationships – description, critique, evaluation or review of the contents of a bibliographic unit, 4. partitive relationships, in UNIMARC format called vertical, relationships of the type whole – parts between bibliographic units or parts, 5. accompanying relationships (relationships of extension, such as a work and an annex or appendix), 6. sequential relationships (follow-up relationships, in UNIMARC designated as chronological), 7. relationships of shared (common) characteristics (such as the same author, name, theme of bibliographic units). Jonathan Furner has suggested an extension of the above taxonomy in the group of shared characteristics, wherein he recommends also the inclusion of important relationships of citation, of relevance and relationships of content related characteristics.48
Another outstanding contribution is a review of relationships in the domain of knowledge organization worked out by Rebecca Green.49 She divides the relationships in two basic groups: mutual relationships of documents and relationships of concepts, reflecting, naturally, also the important relationship document – concept (the contents of the document). She integrates also the bibliographic relationships from the taxonomy by B.Tillett among the relationships of documents, mapping them in the light of the entities within the FRBR model, i.e. relationships between the entities of the first group, relationships of responsibility between the entities of the first and second group and subject relationships (a work has an subject). She complements the group of partitive relationships by adding relationships within the frame of the inherent structure of texts. In tune with J. Furner she highlights the importance of citation relationships of documents. The relationships of concepts according to Green create semantic relationships of equivalence, hierarchy and association and, again in line with J. Furner, relationships of relevance, i.e. relationships of information need or request and document.
The relationships upon which most authors agree irrespective of some partial differences, represent a rather narrow, but generally acceptable common platform. The relationships of equivalence, hierarchy (generic, partitive, instantional) and association are not only accepted by theoreticians, but – as shown in part 2.3 of the present study – they have been included also into the international professional standards and, most essentially, they are implemented in most computer programmes enabling access to information resources to the present day users. It is usually no problem to differentiate between the meaning of the concepts of equivalence, hierarchy and association on the theoretical level. Regarding equivalence we suppose that the semantics of linked elements is the same, regarding association we suppose different meanings of he linked elements with some common feature, and we will designate as hierarchical such relationship where there is the relationship of similarity between the contents of its elements, most often expressed as inclusion (the meaning of the supraordinated element is included also in the meaning of the subordinated element). However, in the practice of everyday work with information resources we come across problems. Most frequently there is a problem concerning the determination of the demarcation line on the continuous scale from equivalence to association, but also problems of equivalence – hierarchy can occur (e.g. synonyma are generally considered as cases of meaning equivalence, but it is not exceptional to find hierarchical pairs designated as synonyma50). As shown by the UML example, the relationships of partitive hierarchy are implemented as association relationships in the present computer programmes. The differences of granularity ("size " of elements within the relationship) are the cause of varying extent of detail of the defined relationships. Differences as to the precision of determination of a relationship make their mapping difficult (how should we map, e.g., index relationships "see", "see also "or the predicate of language OWL owl:sameAs with the triple of relationships expressed in the scheme SKOS as skos:broadMatch, skos:closeMatch and skos:exactMatch?).
In spite of the above qualifications we have determined this triple of semantic relationships as the primary facet in our review of the most important relationships of information resources. It is complemented by two secondary facets containing also essential categories enabling the broadening and deepening of the analysis of the relationships under scrutiny by adding a technological and a language dimensions.
|
primary facet |
secondary facets |
|
|
semantics |
data structure |
permanence, dependence upon the context |
|
equivalence hierarchy (generic, partitive, instantional) association |
linear tree-type network relational |
paradigmatic relationship syntagmatic relationship |
Table 1 Review of key relationships of information resources
The submitted draft of taxonomy in Table 1 is the result of an analysis of theoretical principles of various scientific disciplines. We are aware of the fact that its applicability to the fields of information resources may require very meticulous investigations and testing on an empirical basis. It will be necessary to document the suggested categories with concrete examples, in particular from the following key domains: 1. conceptual (linguistic-semantic) level of relationships within the whole scope of the communication chain – expression and interpretation of conceptual relationships by the author, producer, processor, reader, addressee, while the actor in all these cases can be both a person and a machine; 2. bibliographical relationships (especially in the FRBR model); 3. relationships in the knowledge organization systems; 4. relationships in the Semantic Web.
Conclusion
The problem of relationships of information resources is a typical interdisciplinary issue. Experts from various disciplines look for such relationships or structures that can best reflect the way they themselves perceive the world. Changes in defining the relationships of information resources react to changes undergone by the information resources. The sequential paradigm of written documents was replaced by tree structures of the first databases in mid 20th century, and at the turn of the new millennium by the hierarchical principle of document structuring in the SGML, HTML and XML format. In parallel with that, the relational database structures were able to put themselves through in a not negligible segment of document processing, whose handicap of total dissimilarity with reality was compensated by the firm foundation of the mathematical principles of the theory of sets and of relational algebra. The present day witnesses the advent of network relationships and structures in the form of Semantic Web and linked data, implemented as interlinked, directed and typed graphs. In parallel with that also the paradigm of relations is seen to change: whereas the two-value Boolean logics used to be valid in the closed database environment, fuzzy logics is seen to govern in the open environment of linked data. Also this is certainly just an imperfect image of the infinitely variable and dynamic reality. However, the best options for expressing the complexity of reality appear to be offered by the network relationships – out of all models that have been suggested down to this day. Their implementation in the triple RDF format, in connection with the web technologies, represents an optimum result by combining the advantages of relational and network structures. They enable achieving very fine granularity while intercepting relationships down to the level of single facts. It is a question whether such structure can provide also the necessary extent of abstraction that is essential not only for the representation of reality, but in particular for understanding the same.
This study is a partial solution output of the project NAKI DF13P01OVV013 Knowledge base for the field of information and knowledge organization, as implemented at UISK FF UK in Prague.
Bibliography
BEAN, Carol A. and Rebecca GREEN, ed. Relationships in the organization of knowledge. Dordrecht: Kluwer Academic Publishers, 2011 (reprint of 2001). ix, 232 s. Information science and knowledge management, vol. 2. doi:10.1007/978-94-015-9696-1. ISBN 978-90-481-5652-8 (brož.). ISBN 978-94-015-9696-1 (Online).
ČSN ISO 1087-1 (01 0501). Terminologická práce – Slovník – Část 1: Teorie a aplikace. Praha: Český normalizační institut, 2002. 38 p.
FURNER, Jonathan. Bibliographic relationships, citation relationships, relevance relationships, and bibliographic classification: an integrative view. In: Clare Beghtol, Jonathan Furner, Barbara Kwasnik, ed. Proceedings of the 13th Workshop of the American Society for Information Science and Technology Special Interest Group in Classification Research, November 17, 2002, Philadelphia, PA. Medford (N.J.): Published by Information Today for the American Society for Information Science and Technology, © 2004, p. 29–37. ISBN 978-1-57387-199-0. Advances in classification research, vol. 13. ISSN 2324-9773. doi:10.7152/acro.v13i1.13833.
GREEN, Rebecca. Relationships in knowledge organization. In: Knowledge organization. 2008, 35(2–3), 150–159. ISSN 0943-7444.
HJØRLAND, Birger. Are relations in thesauri "context-free, definitional, and true in all possible worlds"? In: Journal of the American Society for Information Science and Technology. July 2015, 66(7), 1367–1373. doi:10.1002/asi.23253. ISSN 1532-2882 (Print). ISSN 1532-2890 (Online).
ISO 704:2009. Terminology work – Principles and methods. 3rd ed. Geneva: International Organization for Standardization, 2009. 65 p.
ISO 24156-1:2014. Graphic notations for concept modelling in terminology work and its relationship with UML – Part 1: Guidelines for using UML notation in terminology work. 1st ed. Geneva: International Organization for Standardization, 2014. 24 p.
ISO 25964-1:2011. Information and documentation – Thesauri and interoperability with other vocabularies – Part 1: Thesauri for information retrieval. 1st ed. Geneva: International Organization for Standardization, 2011-08-08. 152 p.
ISO 25964-2:2013. Information and documentation – Thesauri and interoperability with other vocabularies – Part 2: Interoperability with other vocabularies. 1st ed. Geneva: International Organization for Standardization, 2013-03-04. 99 p.
KHOO, Christopher S. G. and Jin-Cheon NA. Semantic relations in information science. In: Annual review of information science and technology. Vol. 40. Blaise Cronin, ed. Medford (N.J.): Information Today on behalf of American Society for Information Science and Technology, 2006, chapter 5, p. 157–228. Annual review of information science and technology, vol. 40. ISSN 0066-4200 (Print), ISSN 1550-8382 (Online). doi:10.1002/aris.1440400112. ISBN 978-1-57387-242-3.
SVENONIUS, Elaine. Subject languages: referential and relational semantics. In: The intellectual foundation of information organization. Cambridge (Mass): MIT Press, 2000, chapter 9, p. 147–171. ISBN 978-0-262-19433-4.
TILLETT, Barbara B. Bibliographic relationships. In: Carol A. Bean and Rebecca Green, ed. Relationships in the organization of knowledge. Dordrecht: Kluwer Academic Publishers, 2011 (reprint of 2001),p. 19–35.
Comments
1Allemang, Dean and James Hendler. Semantic web for the working ontologist: modelling in RDF, RDFS and OWL. Morgan Kaufmann, 2008, p. 31. ISBN 978-0-12-373556-0.
2 CELBOVÁ, Ludmila. Informační zdroj. In: KTD: Česká terminologická databáze knihovnictví a informační vědy (TDKIV) [online]. Praha: Národní knihovna ČR, 2003– [cit. 2015-10-03]. Available from: http://aleph.nkp.cz/F/?func=direct&doc_number=000000887&local_base=KTD.
3 WIERZBICKA, Anna. Sémantika: elementární a univerzální sémantické jednotky. Praha: Karolinum, 2014, p. 160–161. ISBN 978-80-246-2289-7.
4 Cited according to: Internetová jazyková příručka [online]. Praha: Jazyková poradna ÚJČ AV ČR, ©2008–2015 [cit. 2015-10-03]. Available from: http://prirucka.ujc.cas.cz/?slovo=vztah.
5 Birger Hjørland pointed to the arbitrariness of relationships in the recently published paper devoted to the relationships in thesauri: HJØRLAND, Birger. Are relations in thesauri "context-free, definitional, and true in all possible worlds"? In: Journal of the American Society for Information Science and Technology. July 2015, 66(7), 1367–1373. doi:10.1002/asi.23253. ISSN 1532-2882 (Print). ISSN 1532-2890 (Online).
6 All examples in brackets concern concrete statements in Fig. 1.
7 Note: There are certain limitations for the combinations of values, such as: the relation 1 : N can be only asymmetrical, not symmetrical.
8 For more detail see, e.g. ČERMÁK, František. Jazyk a jazykověda: přehled a slovníky. 2. reprint 3. enlarged edition. Praha: Karolinum, 2001, 2004, 2007. Chapter 1.52, Structure of the sign and its relationships, p. 24–28. ISBN 987-80-246-0154-0.
9 SVENONIUS, Elaine. Subject languages: referential and relational semantics. In: The intellectual foundation of information organization. Cambridge (Mass): MIT Press, 2000, chapter 9, p. 147–171. ISBN 978-0-262-19433-4.
10 For more detail see, e.g. ČERMÁK, František. Jazyk a jazykověda: přehled a slovníky. 2. reprint 3. enlarged edition Praha: Karolinum, 2001, 2004, 2007. Chapter 4.0, System and text (langue et parole), p. 80–91. ISBN 987-80-246-0154-0.
11 "However, it should be born in mind that there is no sharp demarcation line in the field of syntagma between the fact of language, as a sign of collective usage, and the fact of speech, depending upon individual liberty. It is difficult to classify certain combinations of units in quite a number of cases, since their creation has been due to factors of both type, in proportions that can be hardly differentiated." SAUSSURE, Ferdinand de. Kurs obecné lingvistiky. Comments by Tullio de Mauro; from the French original translated by František Čermák. 1. ed. Praha: Odeon, 1989, p. 154. ISBN 978-80-207-0070-4.
12 "There are two referential relationships serving for the interpretation of a sign, the relation to the code and the relation to the context […]." JAKOBSON, Roman. Poetic function. [From Czech and foreign originals selected and arranged by Miroslav Červenka] Edition of this collection 1. Jinočany: H & H, 1995, p. 57. ISBN 80-85787-83-0.
13 ISO 704:2009. Terminology work – Principles and methods. 3rd ed. Geneva: International Organization for Standardization, 2009. 65 p. – Only the 2nd edition is available in Czech translation as yet: ČSN ISO 704 (01 0505). Terminologická práce – Principy a metody. Praha: Český normalizační institut, 2004. 43 p.
14 ISO 1087-1:2000 Terminology work – Vocabulary – Part 1: theory and application. 1st ed. Geneva: International Organization for Standardization, 2000. 41 p.
15 ISO 25964-1:2011. Information and documentation – Thesauri and interoperability with other vocabularies – Part 1: Thesauri for information retrieval. 1st ed. Geneva: International Organization for Standardization, 2011-08-08. 152 p. – ISO 25964-2:2013. Information and documentation – Thesauri and interoperability with other vocabularies – Part 2: Interoperability with other vocabularies. 1st ed. Geneva: International Organization for Standardization, 2013-03-04. 99 p.
16 ČSN ISO 1087-1 (01 0501). Terminologická práce – Slovník – Část 1: Teorie a aplikace. Praha: Český normalizační institut, 2002. 38 p.
17 National Information Standards Organization
18 British Standards Institution
19 Considering the fact that the standards focus upon the so-called special language used in a certain delimited field, I wish to draw attention to two designation types: terms and proper names.
20 In this case the term inclusion is used in its general meaning, not in the strict sense of the theory of sets or formal logics.
21 In parts 5.1.2 and 5.1.3 the standard ISO 25964 offers, for orientation, a selection from some categories: objects, things and their physical parts, materials, activities or processes, events or occurrences, properties of persons, things, materials or activities, fields or scientific disciplines, units of measurement, types of persons and organizations, individual entities designated with proper names – places, specific objects, topographic phenomena, individuals, organizations, companies.
22 Note: This structure is sometimes also called hierarchical, but for the purpose of differentiation from the relationship of the same name we will prefer the term tree structure derived from the graph theory.
23 Standard Generalized Markup Language
xxiv ISO/IEC 19505-1:2012. Information technology – Object Management Group Unified Modelling Language (OMG UML) – Part 1: Infrastructure. 1st ed. Geneva: International Organization for Standardization, 2012. 220 p. – ISO/IEC 19505-2:2012. Information technology – Object Management Group Unified Modelling Language (OMG UML) – Part 2: Superstructure. 1st ed. Geneva: International Organization for Standardization, 2012. 740p.
25 ISO 24156-1:2014. Graphic notations for concept modelling in terminology work and its relationship with UML – Part 1: Guidelines for using UML notation in terminology work. 1st ed. Geneva: International Organization for Standardization, 2014. 24 p.
26 Data model available on: http://www.niso.org/schemas/iso25964/Model_2011-06-02.jpg [cit. 2015-10-03].
27 Whereas the class diagram focuses upon modelling concepts and their abstract relationships (i.e. concept models), the diagram of objects enables the depiction of concrete individuals or instances (called objects in UML) and their concrete relationships.
29 Virtual International Authority File
30 International Standard Text Code
31 International Standard Audiovisual Number and ISAN Version
32 International Standard Musical Work Code
34 Serial Item and Contribution Identifier
35 International Standard Collection Identifier
36 Identification Number of person in the Register of Persons of the ČR
37 International Standard Name Identifier
38 Identification Number of Organization in the Register of Companies of the ČR
41 International Standard Identifier for Libraries and Related Organisations
42 Available from: http://aims.fao.org/aos/agrontology [cit. 2015-10-03].
43 MICHEL, Dee. Appendix B: Taxonomy of subject relationships. In: Subject data in the metadata record: recommendations and rationale: a report from the ALCTS/CCS/SAC/Subcommittee on Metadata and Subject Analysis. July 1999. Available from: http://www.ala.org/alcts/mgrps/camms/cmtes/ats-ccssac/srrsreport-B2 [cit. 2015-10-03].
44 Available from: http://geneontology.org/page/ontology-relations [cit. 2015-10-03].
45 TILLETT, Barbara Ann Barnett. Bibliographic relationships: toward a conceptual structure of bibliographic information used in cataloguing. Los Angeles, 1987. xxi, 306 p. Thesis (Ph.D.). University of California, Graduate School of Library and Information Science.
46 TILLETT, Barbara B. A taxonomy of bibliographic relationships. In: Library resources &technical services. April 1991, 35(2), 150–158. ISSN 0024-2527 (Print). ISSN 2159-9610 (Online).
47 TILLETT, Barbara B. Bibliographic relationships. In: Carol A. Bean, Rebecca Green, ed. Relationships in the organization of knowledge. Dordrecht: Kluwer Academic Publishers, 2011 (dotisk vydání z r. 2001), p. 19–35.
48 FURNER, Jonathan. Bibliographic relationships, citation relationships, relevance relationships, and bibliographic classification: an integrative view. In: Clare Beghtol, Jonathan Furner, Barbara Kwasnik, ed. Proceedings of the 13th Workshop of the American Society for Information Science and Technology Special Interest Group in Classification Research, November 17, 2002, Philadelphia, PA. Medford (N.J.): Published by Information Today for the American Society for Information Science and Technology, © 2004, p. 29–37.
49 GREEN, Rebecca. Relationships in knowledge organization. In: Knowledge organization. 2008, 35(2–3), 150–159. ISSN 0943-7444.
50 In fact, this is permitted also by standard ISO 25964, enumerating in part 8.1 four types of equivalence, of which two are hierarchical (broader – narrower meaning, complex equivalence).