Keywords: watermarks, paper, paper mills, papermakers, databases, catalogues, musical sources, Union Catalogue of Music, RISM, Répertoire International des Sources Musicales, František Zuman
Mgr. Eliška Šedivá / Music Department, National Library of the Czech Republic, Klementinum 190, Praha 1, Czech Republic
Introduction
The employees of the Music Department at the National Library of the Czech Republic commenced their watermark research[1] in the music sources recorded in the Union Music Catalogue of the National Library of the Czech Republic in association with the RISM (Répertoire International des Sources Musicales) international register of music sources in 2014.[2] Even though the recording of watermarks (mainly in music manuscript sources) had already been undertaken to a certain extent within the framework of the creation of the Union Music Catalogue, the watermarks had not been systematically classified at that time, which would have enabled the identification of individual characteristics, the more reliable localisation of the used paper or the designation of the age of any undated documents. The idea of creating a special watermark catalogue within the framework of the Union Music Catalogue proved to be unrealistic at the beginning of our efforts to systematically compile information on this phenomenon. For this reason, we began to consider connecting this research to the RISM catalogue which provided us with the working environment for the description of the watermarks and enabled a direct link to be established between the research and the contents of the international database of music sources.
The recording of watermarks is undertaken simultaneously with the cataloguing of music sources for the RISM database and the results are published there regularly (ZUMAN 1923). However, this only involves the first of a number of outputs from this project. The second such output is the Dictionary of Czech Paper Makers, an extract from the seven different papers about historical Czech paper mills written by František Zuman, which is gradually being supplemented with discoveries of watermarks from music sources transferred to the RISM international database. The dictionary mainly serves cataloguers as a tool when identifying paper mill owners and paper mills, but in the future we are expecting it to be expanded and to be used with the framework of the prepared methodology for working with watermarks in music collections. The third output is a watermark database, where we are concentrating all the source findings and the currently known information about Czech watermarks.
František Zuman and his contribution to the history of Czech paper mills
The current research into watermarks would be difficult to undertake without the valuable contribution which the historian of Czech paper making, František Zuman (1870–1955) has left us in a wide range of work focussed on the production of paper and the history of paper mills and watermarks. He is the author of papers covering the extensive period from the 17th to the mid-19th century, including a smaller probe into the 16th century (ZUMAN, 1921a and ZUMAN,1927a). He is the author of general essays (for example, České filigrány XVII., XVIII. a první poloviny XIX. století), as well as essays focussing on a specific territory (for example, the paper mills in the catchment area of the Sázava or Otava Rivers or in the Lower Giant Mountains) or on specific paper mills (Trutnov, Prague). In them, he presented a deep insight into the activities of the paper mills and the lives of their operators. His more detailed work, such as the articles in Památky archeologické or in Zlatá Praha, filled in previously vacant areas in the history of Czech paper mills and provided further starting points for the identification of watermarks.
The Dictionary of Czech Paper Mills
We compiled the first dictionary of Czech paper mills containing most of the individuals and the places where they were active as identified by Zuman on the basis of Zuman’s extensive research, albeit that his research was focussed on the study of various forms of documents (documents, registry records, correspondence and other archive materials) and not only sheet music. The entry created for each given paper mill owner contains all the forms of his name (as they appear in Zuman’s work and in other sources, for example in the form of the inscription which often formed part of the watermark), the individual places where the individual was active in chronological order (a number of paper mill owners were active in two or more places) and the description of the watermarks pertaining to the given individual. In some of his treatises, Zuman also provided negative photographs of watermarks which can be compared with findings in the sources. The entries are concluded with quotations from the literature, most of which is Zuman’s work.[3] Even though Zuman did not work with musical documents, the watermarks are consistent to a significant extent in both the archive material and in the sheet music manuscripts. The work with musical sources has expanded our awareness of the production and distribution of (not only) Czech paper and its use in musical institutions and in places such as monasteries, church choirs, music associations, schools or, for example, aristocratic or burghers’ salons. A certain number of music documents contain a date written on the material by the music’s author, the copyist or another person and in exceptional cases it is possible to compile a detailed summary of the paper used in a given locality or in a specific place where music was performed.
This dictionary is currently accessible in electronic form from the website of the National Library of the Czech Republic[4] and from the homepage of the watermark database[5], according to which it is regularly supplemented and with which it is retrospectively connected by means of hypertext links.
Fig. 1.

A description of the watermarks
When describing the watermarks, we have used the established English terminology from the RISM international catalogue of musical sources and we have applied it both in the records in this database and in all other outputs (the Dictionary of Czech Paper Mills etc.). In the first phase of recording the watermarks, we used the environment of the RISM multimedia database in the Kallisto program which enables the insertion of a picture file and the inclusion of a short description with it. This internal database is especially used by cataloguers for entering the photographic documentation of sources. However, we used it as a working environment for the collection, description and classification of watermarks. The watermark records can be connected with the appropriate records of music sources as soon as they are created. Instead of a photocopy (which is most commonly used in these cases), we chose a black and white tracing on transparent tracing paper as the “sample” and the illustration of the given watermark. This may differ to a certain extent from the illustrations in other sources, but it essentially involves the same symbol which underwent some deformation over time as a result of the repeated use of the mould. In the interests of completeness, we have also included a photograph of the watermark from a specific source in the RISM record so that it is possible to compare it with the “sample” in the form of the tracing.
As well as the actual watermark, the tracing also includes the chain lines[6] and the scale, amongst other things. It may also include a view showing the placement of the symbol on a sheet of paper. The watermark tracings depict the maximum amount of detail which can be seen with the human eye, but this always depends on individual observation and the experience of the individual preparing the tracing. Emphasis is placed on the identification of the watermarks and the classification method rather than on the visualisation in the phase of the collection and initial classification of the material. A watermark’s name is created by means of a description of the individual symbols and parts thereof from left to right and from the top down as they are located on the page. The described figures are entered in square brackets, while any initials or inscriptions are listed without brackets. The left and right half-sheets are separated in the name by means of a slash, while the positions of the symbols on the sheet are also noted. Symbols which are located one under the other are divided with a vertical pipe.
Fig. 2. [coat of arms (Austria-Hungary, big, crowned) in cartouche with palm branches around]/ [3 peacock feathers (crowned) (= coat of arms, Harrach)] | IPM | G. An example of description and tracing of watermark by Jan Pavel Margott from Trutnov paper mill. This watermark on music manuscript 59 R 4361 from National Library of the Czech Republic (provenance of Koleč church) is dated 1807. As Zuman states, J. P. Margott worked in Trutnov paper mill between 1786 and 1819. Author of the tracing: Lucie Havránková.
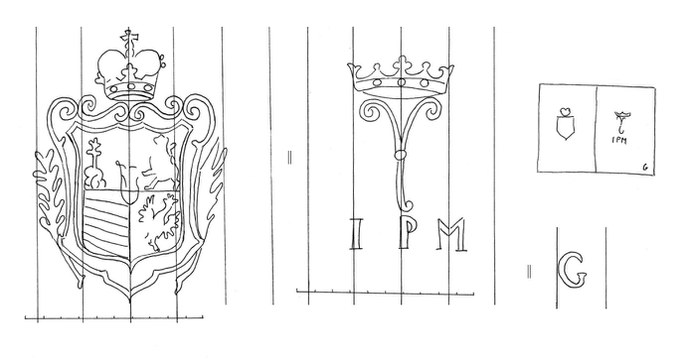
Music collections
The collection, identification and recording of watermarks in music sources take place within the framework of the processing of music collections for the RISM database.[7] The collections which have been included in this research (and in which the watermarks have also been strictly described during cataloguing) come from various locations and different types of musical institutions. The team of cataloguers works does not only work with collections stored at the National Library of the Czech Republic (CZ-Pu), but also, for example, with collections from the National Museum – the Czech Museum of Music (CZ-Pnm).[8] The collections most commonly contain music manuscripts and printed sheet music from the second half of the 18th century and the first half of the 19th century. We can summarise this by stating that as far as the watermarks in music collections were concerned we were interested in the period approximately between 1750 and1850, exceptionally with some overlap into the early 18th century.
The music collections catalogued (including the records of the watermarks) in the Union Music Catalogue and the RISM database:
a) collections with comprehensive watermark records: 1) the music collection from the church in Koleč (in: CZ-Pu): 177 shelfmarks, 91 new watermarks; 2) the music collection from the church in Řetová (in: CZ-Pu): 218 shelfmarks, 78 new watermarks; 3) the music collection from the Želiv monastery (in: CZ-Pnm): 528 shelfmarks, 188 new watermarks; 4) the music collection of Count Christian Philip Clam-Gallas from the château in Frýdlant (in: CZ-Pnm): 1572 shelfmarks, 426 new watermarks;
b) collections with incomplete records of watermarks: 1) the music collection of the Hübner family from Dlouhý Most (in: CZ-Pu); 2) the music collection of the Strachota family from Panenský Týnec (in: CZ-Pu); 3) the music collection of Jan Nepomuk Kaňka from the château in Jetřichovice (in: CZ-Pu); 4) the music collection of the Hospital of the Brothers Hospitaller in Kuks (in: CZ-Pnm).
The records of the watermarks are continuously uploaded to the RISM database via the multimedia database, where they receive an identification number and are subsequently connected to the source records. They are also included in the watermark database under the same name, where information about the paper mills and their owners, source dates or publishers who used the given paper to print music are also gathered. Finally, the information about the watermarks is added to the dictionary of paper mill owners (provided this involves a watermark of Czech origin).
The database of watermarks in the music sources recorded in the Union Music Catalogue of the National Library of the Czech Republic[9]
The database of the watermarks found in the music sources recorded in the Union Music Catalogue of the National Library of the Czech Republic (known as the Bohemian Watermark Database = BWD) was created in 2016 and it is the main output of this watermark research. The foundation of the database consists of a list of paper mill owners and paper mills in the territory of Bohemia and Moravia which has been compiled on the basis of the legacy of František Zuman (and partially supplemented with information from G. Eineder). As of today, we have records of 726 Czech paper mill owners and 235 paper mills dating from the 16th century to the end of the 19th century.
It is possible to search in the database using the name of the watermark or its individual parts or according to the name of the paper mill owner, the paper mill, the country or the publisher (in the case of printed sheet music). There are indexes and a summary of the countermarks available which assist users to become acquainted with the contents of the database. It is possible to search for the individual entries in this selection separately or in combination with others. It is also possible to search for all the watermarks in a specific collection (provenance) and to subsequently arrange the results as needed (for example, alphabetically by paper mill owner, paper mill or country of origin).
The record of a specific watermark contains the name in the header, the identification number, information about the paper mill and the mill owner (if they are known), the source of the tracing (the library siglum and the shelfmark of the document from which the watermark has been traced) and the provenance. Any further information is used to record the archived original tracings.[10] The dates in the sources and the bibliography conclude this section of the description. There is also a space reserved for notes. It is possible to scroll through the records and to use the active entries to reach other results.
A number of watermarks have not been able to be traced due to their poor legibility or other losses of integrity. As such, if a record does not include a tracing of the watermark, a photograph is included and this will remain the case until such time as we find material from which it is possible to acquire a tracing and to supplement the record.
As the name of the database clearly shows, this involves watermarks in the music sources held in the collections of Czech institutions, but for all that we have not limited ourselves to exclusively Czech watermarks. The composition of the collections has necessarily also led us to work with paper from abroad. We have endeavoured to identify it on the basis of the available literature and digital sources and we have then included the information about this paper in the database.
Table 1. Czech and foreign paper in music collections (1. 7. 2016). The music collections marked* with complete watermark registration. Abbreviations in footnotes. [11]
|
Music collections |
A |
CH |
CZ |
D |
GB |
I |
PL |
N |
F |
[n] |
total |
|
Koleč, church (CZ-Pu)* |
1 |
|
46 |
|
|
|
|
|
|
44 |
91 |
|
Řetová, church (CZ-Pu)* |
|
|
45 |
|
|
|
|
|
|
33 |
78 |
|
Želiv, monastery (CZ-Pnm)* |
1 |
|
96 |
3 |
|
4 |
1 |
|
|
83 |
188 |
|
Clam-Gallas, Frýdlant (CZ-Pnm)* |
8 |
6 |
60 |
27 |
|
190 |
|
7 |
11 |
117 |
426 |
|
Hübner family, Dlouhý Most (CZ-Pu) |
1 |
|
28 |
|
|
|
|
|
|
16 |
45 |
|
Strachota family, Panenský Týnec (CZ-Pu) |
|
|
21 |
|
|
|
|
|
|
25 |
46 |
|
J. N. Kaňka, Chateau Jetřichovice (CZ-Pu) |
|
|
12 |
|
|
|
|
|
|
10 |
22 |
|
The Kinský Library, Prague (CZ-Pn) |
1 |
|
8 |
1 |
|
2 |
|
|
|
8 |
20 |
|
National Library of the CR (CZ-Pu) |
|
|
53 |
3 |
1 |
|
2 |
3 |
1 |
27 |
90 |
|
Bohemian Watermark Database (1. 7. 2016) = 1006 |
|||||||||||
Table 1 shows the apparent dominance of Czech paper in the aforementioned Czech collections, while the as yet unidentified watermarks may also be of Czech origin (the same symbols are repeated here, but without any other nominal or place information). The countermarks which most frequently appear in Czech watermarks (see table 2): a shield (83 occurrences);[12] the fleur-de-lis (57) either standing alone or in combination with a shield (various sizes and positions on the sheet have been found); the crowned Hungarian coat-of-arms (41) regularly supplemented with initials or an inscription on the opposite half-sheet; a cartouche (31) as a decorative oval frame for other countermarks; a cross (27), often the patriarchal cross; a star (26) and a crescent (19) most frequently together in a paired watermark; a posthorn (23) designating writing paper which has different properties than the paper which was regularly used to copy out works of music (it is usually finer and of different dimensions); a two-headed eagle (21) usually with a large crown and a shield or coat-of-arms, it may be holding a sword, a sceptre or an orb in different combinations; an anchor (19) either standing alone or placed in a shield - this was one of the most popular symbols among Czech paper mill owners; a mitre (17) which may also stand alone or crown a shield with ecclesiastical insignia (see below); the Bohemian lion (17); a heart (13) or keys (12) most frequently crossed, supplemented with initials or an inscription, etc.. We have set out the names of the paper mill owners and the paper mills where we have recorded the most watermarks to date in table 3.
Table 2. Watermarks in Bohemian Watermark Database (a selection of main countermarks). A part of unidentified watermarks [un]* can be of Czech origin.
|
countermarks (BWD) |
A |
CH |
CZ |
D |
GB |
I |
PL |
N |
F |
[un] |
total |
|
shield |
6 |
5 |
83 |
9 |
|
26 |
|
7 |
2 |
83 |
221 |
|
lily (french) |
|
4 |
57 |
6 |
|
11 |
|
6 |
|
46 |
130 |
|
coat of arms (Hungarian) |
|
|
41 |
|
|
|
|
|
|
19* |
60 |
|
cartouche |
1 |
|
31 |
1 |
|
2 |
|
|
|
18 |
53 |
|
cross |
|
|
27 |
4 |
|
|
|
|
4 |
15 |
50 |
|
double-eagle |
|
|
21 |
|
|
|
|
|
|
28* |
49 |
|
heart |
1 |
|
13 |
|
|
1 |
|
|
3 |
28 |
46 |
|
posthorn |
|
|
23 |
|
|
|
|
1 |
|
21 |
45 |
|
star |
3 |
|
26 |
|
|
6 |
|
|
|
9 |
44 |
|
crescent |
3 |
|
19 |
|
|
11 |
|
|
|
10 |
43 |
|
anchor |
1 |
|
19 |
1 |
|
1 |
|
|
|
11 |
33 |
|
mitre |
|
|
17 |
|
|
|
|
|
|
15* |
32 |
|
keys |
|
|
12 |
|
|
|
|
|
|
18 |
30 |
|
Bohemian lion |
|
|
17 |
|
|
|
|
|
|
9 |
26 |
|
arrow and bow |
|
|
|
|
|
18 |
|
|
|
|
18 |
|
stag |
|
|
1 |
|
|
|
|
|
|
8 |
9 |
|
crown |
|
|
2 |
1 |
|
3 |
|
|
|
2 |
8 |
|
St. Johannes Nepomuk |
2 |
|
|
|
|
|
|
|
|
6 |
8 |
|
unicorn |
|
|
1 |
|
|
|
|
|
|
7 |
8 |
|
wall coping |
|
|
3 |
|
|
|
|
|
|
3 |
6 |
|
snake |
|
|
3 |
|
|
|
|
|
|
2 |
5 |
Table 3. Czech paper makers in Bohemian Watermark Database with most watermarks.
|
Paper makers (CR) |
worked |
Paper mill |
Watermarks |
|
KIESLING family |
1800c–1850c |
Vrchlabí |
35 |
|
HELLER, Jan Antonín |
1808–1841 |
Ledeč nad Sázavou |
20 |
|
KLUSÁČEK, Jakub |
1818–1848c |
Červená Řečice |
12 |
|
APPELTAUER, Josef Antonín |
1807–1851 |
Velhartice |
10 |
|
FÜRTSCH, Jan Jiří snr. |
1773–1812 |
Postřekov |
10 |
|
BAYER, Ondřej I. |
1762–1796c |
Stříbro |
9 |
|
HELLER, Josef Benedikt |
1779–1829c |
Staré Hory / Ronov |
9 |
|
HALÍK, Tomáš |
1828–1851 |
Havlíčkův Brod |
8 |
|
PŘÍHODA, Kristián |
1740–1788 |
Červená Řečice |
7 |
|
FÜRTSCH, Jan Jiří jnr. |
1812–1844 |
Postřekov |
6 |
|
SCHÜTZ, Josef I. |
1796–1826c |
Rádlo |
6 |
|
WINTERNITZ, Abraham & Emanuel |
1825–1865c |
Lochovice |
5 |
|
ZÖH, Petr |
1816–1846c |
Trutnov |
5 |
|
MARGOTT, Jan Pavel |
1786–1819 |
Trutnov |
4 |
|
PLENINGER, Antonín |
1819–1851 |
Kolinec |
4 |
|
REK, Ludvík |
1749–1773c |
Ronov |
4 |
|
RICHTER, Josef III. |
1796–1822 |
Dolní Litvínov |
4 |
|
RITSCHEL, František I. |
1792–1827a |
Benešov nad Ploučnicí |
4 |
|
RITSCHEL, František II. |
1816–1840 |
Svídnice |
4 |
|
WERNER, Mathias |
1765–1795a |
Velké Losiny |
4 |
The identification of unknown watermarks
As has already been stated, the recording and detailed identification of the watermarks in the music sources recently commenced at the Music Department of the National Library of the Czech Republic. Four music collections have now been fully processed in the aforementioned manner: the collections from the churches in Koleč and Řetová (in: CZ-Pu), from the Želiv Monastery and from the château in Frýdlant (in: CZ-Pnm). The significance of this for the source research of watermarks is that a) a large amount of comparative material, i.e. watermarks which are already known from the literature (Zuman), is now available in relation to musical sources, i.e. in a new context and with new information (the date or provenance stated by the copyist, the year of publication in the case of printed sheet music, notes made by previous owners, dedications, specific historical events, during which this material was used and even a piece of music written on a certain type of paper are all important pieces of information in this case) and b) there have been extensive additions of as yet unknown countermarks or new combinations of known symbols and supplementary inscriptions identifying the manufacturers of the paper.
In the case of the watermarks which have already been recorded by Zuman (or any other researchers), we have appended the date in the music source and compared it with the period of the paper mill owner’s activities in the given location. Sometimes, we have expanded the timeframe for these activities stated by Zuman and, of course, we have reckoned with a certain overlap in the use of the paper after the completion of the producer’s activities. We have not only come across the natural deformation of watermarks (the emblems, inscriptions and chain lines change their shape insignificantly after each use and the life cycle of the moulds was relatively short), but also the deliberate modification of the countermarks ranging from diverse variations of the same symbols through to the removal and replacement of certain sections. We can give the example of the watermark of Andreas Bayer from Stříbro, which is frequently represented in the collections and which Zuman found in a document dating from 1796 and described thus: “… there is a dimerous watermark from his workshop: the first half-sheet includes a lily, while the countermark on the second is similar to a four with WAB (= ? Andreas Bayer) beneath it.”[13] This watermark can be found in several variants in the collection of the Strachota family from Panenský Týnec (1801), as well as in the archive of the château chapel in Frýdlant, in the Kinský Library (in: CZ-Pn) or in the church collection from Koleč. This last case includes an apparently later variant of this watermark which was changed by the paper maker’s son and successor, Georg Bayer: he replaced the middle letter in the WAB trigram with “G” (= Georg). The dimerous watermark with the initials WGB is apparently evidence of the way in which these signs were adapted in paper making families. This watermark has yet to appear in the literature and the identification of the initials would probably not have been possible without the systematic classification and research into whole collections. We can use this example to show the time overlap in the use of the paper: according to Zuman, Georg Bayer took over the paper mill at the end of the 18th century and he was supposedly followed by Margaret Bayer in 1810. As the sources from the church in Koleč show, however, Andreas Bayer’s paper with the initials WAB was still in use (and apparently also in production) in 1812.
Fig.3. Watermark of Ondřej Bayer with inicials WAB (a) and later version of this watermark with a change WGB by Jiří Bayer (b). Watermark a) see CZ-Pnm/ XLII B 241 (Clam-Gallas, Frýdlant), half-sheet: fleur-de-lis (7,5 × 4,5 cm), right half-sheet: inicials WAB with emblem (4,5 × 5 cm). Watermark b) see CZ-Pnm/ 59 R 4495 (Koleč, church), left half-sheet: fleur-de-lis (8,5 × 5 cm), right half-sheet: inicials WGB with emblem (4 × 6 cm).
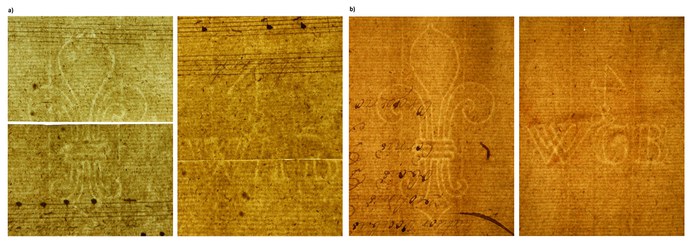
We have always endeavoured to identify any discovered watermarks using the literature. In approximately half the cases, however, this has involved new findings and a large number of them do not contain any nominal information. We have differentiated between monomial, dimerous and multiple element watermarks. In the case of watermarks which were created in Bohemia in the period between 1750 and 1850, we have most frequently come across dimerous watermarks, i.e. with a countermark of medium dimensions on the left half-sheet and the paper mill owner’s initials or full name on the right half-sheet. The initials or extensive inscriptions can sometimes also state the place of production (of course, in the form used in the given period). Some paper mills also marked their paper with a number signifying the type (quality) of paper. This number (for example, N 1, N 2, N 3, N 4...) can usually be found in the right or left-hand lower corner of the sheet or in exceptional cases in the middle.[14] However, when collecting watermarks in music sources, we have not always found sheets of paper where all of the elements of the watermark have been preserved. Only rarely have we come across a watermark’s uncut dimensions, whereby the original size of the mould, in which the sheet of paper was produced, constitutes an important part of its identification. We therefore often only have the countermark (or part thereof) or the information on the adjacent half-sheet. A number of Bohemian watermarks are monomial. They may be located in the centre of the sheet or only on one of the half-sheets.
However, even in these cases, it is possible to follow the indications which lead us to a specific paper mill owner (including in the case of any as yet unregistered and often incomplete watermarks), thanks to the monitoring of the contexts within the specific collections as contained units. The four aforementioned collections, whose research has been completed, have not only provided a large volume of new data in the area of watermarks, but they have also enabled us to complete watermarks, which we would never have placed within the given context, if we had assessed them independently of the collection from which they come. We have proceeded from the fact that places with long-term musical operations (such as church choirs or monasteries) took delivery of paper from their environs and all the collections completed to date have confirmed this fact.
It is known that each paper mill owner had several moulds for paper production and that a different watermark was usually made for each of them. As such, we can find several different symbols (pertaining to a single paper mill owner), which were created by the same person (the author of the drawing and the mould) at the same time. It is not only the countermarks which are repeated in this case, but also the specific style and aesthetic formation of the watermark.
For example, the completion of the new watermarks inside the collection from the church in Řetová (the District of Ústí nad Orlicí) helped to clarify the origin of the watermarks pertaining to the paper mill in nearby Žamberk. A dimerous watermark depicting the crowned Hungarian coat-of-arms with the adjacent inscription SEMFTEMPERG, which unequivocally refers to this place, can be found in the collection. During processing, the same Hungarian coat-of-arms was discovered, but the paper mill owner had replaced the designation of the place of production with his initials MS. According to the dating in the Řetová sources (1823, 1830, 1831) and the information contained in G. Eineder’s work, this probably involved the paper mill owner Martin Ševčík, who was active in Žamberk around 1818.[15]
Another example of the completion of the watermarks within the entire music collection (this time only with indirect support from the literature) involves the collection of watermarks by Johann Georg Zays, who was active in Janovice nad Úhlavou (Veselí, the District of Klatovy) after 1763, contained in the collection of the Strachota family from Panenský Týnec (in: CZ-Pu). Even though this collection has so far been only partially researched from the point of view of the watermarks, the information and the method used to produce the countermarks have enabled the identification of some paper producers and the designation of a number of their symbols. The new information includes, for example, a multiple element watermark which displays the Bohemian lion in the middle of the sheet with the initials I. G. Z. (= Iohann Georg Zays) on the left and the majuscule I (= Ianowitz) in the middle of a six-pointed star on the right (see Fig. 4a). Zuman mentioned this paper mill owner, but it would seem that he did not manage to find a watermark from this location. Thanks to the peculiar design of the Bohemian lion in this watermark and the repetition thereof in the material which was used by the same person (in this case, the copyist and owner of the collection, Josef Cyril Strachota (1746‒1809)), we have also been able to identify other “related” watermarks which bear the year of the paper’s production “1777” (see Fig. no. 4b, c). This corresponds to the period of the copy, while the quality (the colour, delicacy and dimensions) also corresponds to the aforementioned watermark with the initials I. G. Z.
Fig. 4. Watermark of Jan Jiří Zays from paper mill in Janovice nad Úhlavou (1777), a) CZ-Pu/ 59 R 3505, b) CZ-Pu/ 59 R 3519, c) CZ-Pu/ 59 R 3518. Author of the tracing: Lucie Slivoňová.
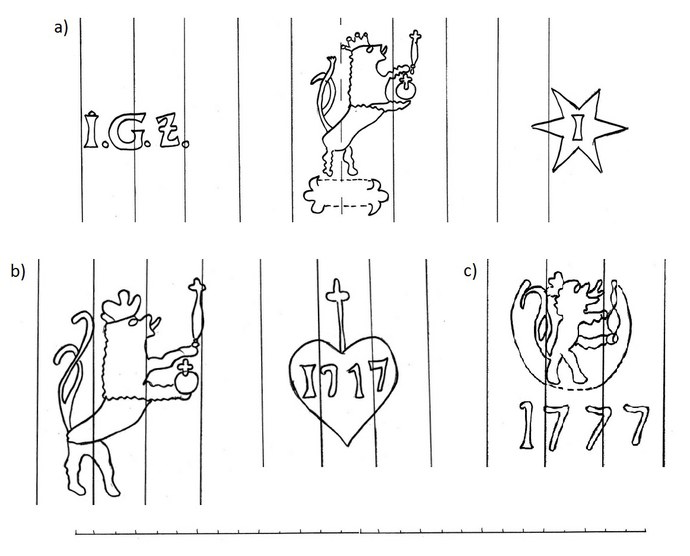
We can find a relatively rich repertoire of Bohemian watermarks in the sources from the music collection from the church in Koleč. The dominant group of watermarks, which has been preserved within one unit and which at the same time represents one of the most frequented groups in the researched music sources, consists of the paper mill marks of Johann Georg Fürtsch (active between 1773 and 1812) (ZUMAN, 1932, p. 21; ZUMAN 1934a, p. 20–21) and his son Johann Georg Fürtsch junior, who operated the paper mill in Postřekov after his father until 1844 (ZUMAN 1934a, p. 21). The older watermarks dating from the end of the 18th century and belonging to J. G. Fürtsch senior consist of the initials IGF, the inscription KOTENSCHLOS (Chodenschloss = Trhanov) (1794, 1799, 1809) and two crossed keys with the same inscription (1794, 1809). The son of this paper mill owner used a popular symbol, the fleur-de-lis, also with the inscription KOTENSCHLOS (on the same or the adjacent half-sheet or in the lower corners) (1816, 1827, 1830). We have so far found the products of this paper mill in all the researched collections and it would appear that it was amongst the most frequently used in the area of the music sources of the first half of the 19th century. The aforementioned symbols are usually repeated (the lily, the keys or the two-headed eagle), but the best-known dimerous watermark from the Postřekov paper mill is clearly the fleur-de-lis with a shield with a diagonal stripe beneath it on the left-hand half-sheet and with the inscription KOTENSCHLOS on the right-hand half-sheet. This watermark clearly already dates from the time of J. G. Fürtsch senior, because it has been found, for example, in printed music from Prague dating from 1797 and 1800.[16] A number denoting the type of paper was later added in the left or right-hand lower corner, for example N 4 (Kinsky: 1825, 1826).[17]
The catalogues of the watermarks in the music collections – the Želiv Monastery
The first attempt to create a printed catalogue of watermarks was undertaken in May 2016, when the thematic catalogue of the music collection from the Premonstratensian monastery in Želiv was published as the 9th volume in the Catalogus artis musicae in Bohemia et Moravia cultae series of the National Library of the Czech Republic. Alongside the introductory study dedicated to the history and musical life of the monastery and the actual body of the catalogue of preserved sheet music (now stored in the collections at the National Museum – the Czech Museum of Music), it contains the most detailed catalogue of watermarks from a music collection ever published in this publishing series (SEMERÁDOVÁ, ŠEDIVÁ 2016). This collection provides ideal conditions for research into watermarks, because a large number of the pieces of sheet music there are dated and often include extensive notes made by the copyists. This mainly involves music parts which were copied by alumni (the pupils at the Latin grammar school). Their work, which apparently took place in closed groups (a given pupil frequently always completed the parts for the same instrument or voice), was supervised by the regenschori. He later confirmed his supervision with a note on the cover for the parts and he usually dated his signature. It is precisely this dating in the sources which is essential for the systematic work with watermarks. Thanks to the specific formation of the Želiv collection, we have many supporting points which we have drawn on in the watermark catalogue and during comparisons with other collections.[18]
The watermark catalogue has been created in two parts: a) a tabular list of the watermarks with names corresponding to the form used in the RISM database and the watermark database (BWD), along with a list of the individuals from the environment of the Želiv monastery who used the paper with the given watermark to copy musical works and the dates in the sources, while the last entry is a reference to the thematic catalogue for the specific piece of sheet music; b) the second part consists of the pictorial annex where almost all the watermarks from the given collection have been reproduced.[19]
Thanks to the fact that the Želiv monastery purchased paper from its vicinity (especially from the paper mills in the area along the Sázava River), it has been possible to reconstruct certain stages in the operations of the most frequently appearing paper mills and to substantiate the watermarks used in this period. This has been managed to the greatest extent in the case of the paper mill in Červená Řečice which is a mere five kilometres from the Želiv monastery. We have collected a total of 18 watermarks from the paper mill’s production in the period between 1740 and 1848. There were only three owners of the mill during this period: Christian Příhoda (active [20] from ca 1740 to 1788), his son Václav Příhoda (1788‒1818) and Jakub Klusáček (1818‒1848c) (ZUMAN, 1934a, p. 24; ZUMAN 1936, p. 54–67). The watermarks designating the paper produced by Christian Příhoda especially display shields and ecclesiastical insignia. There are several shield variants which are crossed by a crosier and an archbishops cross, while there is a mitre instead of a crown and the initials CP appear below the shield. One watermark from the period when Christian’s son Václav Příhoda took over the paper mill has been preserved in the Želiv collection: a crowned Hungarian coat-of-arms on the left-hand half-sheet and the inscription W PRZIHODA on the right-hand half-sheet. This paper was used around the year 1805 for copying music parts, but it was also suitable as an envelope for older materials. We are aware of a total of 11 different watermarks from the workshop of Jakub Klusáček dating from the period between 1824 and 1841. Like his predecessor, Klusáček also used the crowned Hungarian symbol along with an anchor placed either independently or within a shield or a post horn in a crowned shield.[21] We do not comprehend these shields as coats-of-arms in the true sense of the word, because they did not belong to noble individuals. This involved a merchant “trademark”, a symbol which was only used for the purpose of protecting the manufacturer. The paper mill owner Klusáček appended his initials or his entire name written either in majuscule or in italics to these symbols. He also used the initials J. K. or R. R. (Roth Retschitz).
A relatively large number of watermarks from this collection come from another paper mill in the Sázava River area, from Ledeč nad Sázavou. This mainly involves the production of Johann Anton Heller (active between 1808 and 1832) (ZUMAN, 1934a, p. 17; ZUMAN 1936, p. 45–47) which is most commonly labelled simply with the inscription A HELLER along the lower edge of the sheet. In other cases, the name was supplemented, for example, with the crowned Hungarian coat-of-arms, an anchor or the aforementioned merchant’s trademark which once again consisted of an anchor in a crowned shield. We have also come across the location information LEDETSCH which either stands independently or in combination with the name of the paper mill owner.
The watermarks of Thomas Hallik from what is now Havlíčkův Brod (active in 1828‒1851c) (ZUMAN 1934, p. 9; ZUMAN, 1936, p. 27) have been found in the Želiv collection in sources dating from the mid-19th century, i.e. towards the end of the manual production of paper. His paper differs from the others mainly due to its larger dimensions and finer structure. Judging by the central symbol, a post horn, which was used in combination with information about the location D. BROD (= Deutschbrod, also D: Brod in italics) and his name T. Hallik, this was probably writing paper. The right or left-hand section of the watermark is always depicted as a mirror image and so the paper was made so that the sheet could be folded over before use (as was the custom when writing correspondence). The post horn was occasionally replaced with the symbol of the Bohemian lion, while the remainder of the watermark remained unchanged. One specific point of interest is connected with T. Hallik’s products in the Želiv collection. This paper was used to write out the bombardone instrumental part, which was added to the original orchestration of older works in the mid-19th century.
The paper mill owner Adalbert Hallik, probably is not relative to the aforementioned mill owner, (active in 1820‒1834) (ZUMAN,1934, p. 29–30; ZUMAN 1936, p. 68) from Zahrádka on the Želivka River (the District of Havlíčkův Brod) especially supplied paper to the Želiv monastery in the second quarter of the 19th century. His paper bears the name A HALLIK and the place of production ZAHRADKA in several variants. Once again, the motif of the anchor was repeated and the paper mill owner placed it in the centre of a crowned shield and added his name written in italics on the adjacent half-sheet. Secondly, he placed the anchor in the middle of the sheet and placed the inscription A. / HALLIK around it.
The other paper mills admittedly do not belong to the Sázava river area and in some cases they were somewhat distant from the Želiv monastery, but for all that their paper designed for copying musical works made its way to the monastery. For example, there are samples of the production from the paper mill in Svídnice (the District of Chrudim) from three different stages of the activities of the Ritschel family: Josef Ritschel (active from 1784c to 1809) (ZUMAN 1932, p. 28), whose workshop produced a watermark with a large crowned W, the inscription SWIDNIZ and the initials I. R., followed by Anton Ritschel (active from 1809 to 1816) (ZUMAN 1934a, p. 7), who appended a figure of a lion and his initials to the information about the place of production, and finally Franz Ritschel (active from 1816 to 1840) (ZUMAN,1934a, p. 27), who used the crowned Hungarian coat-of-arms with the inscription SWIDNITZ and his whole name F RITSCHEL. We should also mention the paper mill in Postřekov (the District of Domažlice), which has already been mentioned elsewhere in association with the collection from the church in Koleč. The Želiv collection also contains preserved copies of the aforementioned paper with the inscription KOTENSCHLOS produced by Johann Georg Fürtsch the younger. A number of watermarks from the Velhartice paper mill (the District of Klatovy) come from the paper mill owner, Josef Anton Appeltauer (active from 1807 to 1851) (ZUMAN 1934a, p. 28–29; ZUMAN, 1934b, p. 31–33). As in the case of the aforementioned paper mill owners, here too we find initials or information about the place of production. The fleur-de-lis is a frequent figure, either self-standing or in combination with a shield as in the case of the Postřekov paper mill.
The Vrchlabí paper mill of the Kiesling family is also significantly represented among the manuscripts dating from the 1830s. This involves products from the workshop of Anton Johann Kiesling (born: 1766 ‒ died: 1838) and his brother Heinrich (died: 1862) (ZUMAN 1940, p. 31) marked with the initials K & S and usually supplemented with a fleur-de-lis in a crowned shield completed underneath with a symbol in the shape of a number four. A. J. Kiesling’s brother Karl August Kiesling (died: 1818) (ZUMAN 1940, p. 97–103) also used the fleur-de-lis in combination with a shield with a diagonal stripe and the initials GK or the inscription “Gebrüder Kiesling”. Later, we can find the inscription CAKE (= Carl August Kieslings Erben) in the lower right-hand corner of the sheet in combination with the fleur-de-lis in a crowned shield.
The conformity of the used countermarks, both in the paper from those mills located in a single region and in those more distant, over a relatively long period of time is apparent in this summary of the most important watermark discoveries. The named paper mills are amongst those which are most frequently represented in the collection and six fundamental (apparently the most popular at that time) countermarks are repeated there: the shield, the fleur-de-lis, the Hungarian coat-of-arms, the post horn, the anchor and the Bohemian lion. These are also the countermarks which have been most frequently preserved in the musical material which has been researched to date, as has been shown above (see table 2).
The newly completed watermark research in the Clam-Gallas music collection from Frýdlant
The re-cataloguing of the music collection of Count Christian Philip Clam-Gallas (1748-1805) for the RISM database was completed in 2016. This extensive collection containing over 1500 shelfmarks was originally the active archive for the château orchestra in Frýdlant, but now the collection is stored at the National Museum – the Czech Museum of Music. This especially involves an orchestral (and chamber) repertoire, most frequently in the form of instrumental parts, but there are also some operatic scores with the performed parts and various works of music designated for domestic production. Some of these pieces of music (nowadays, there are ca 80 shelfmarks which are exclusively operatic arias) were originally part of the private collection of Countess Marie Caroline Josepha Clam-Gallas (nee Špork) (1752‒1799) and they were apparently added to the collection before it was stored at the National Museum.
Here too, records of all the watermarks were compiled and a catalogue similar to that for the collection from the Želiv Monastery was put together during the cataloguing.[22] Given the fact that this involves an aristocratic collection, it is completely different from the monastery collection in its repertoire composition, type of material, scope and the characteristics of the specific internal units. The catalogue has therefore been divided into groups according to the country of origin of the watermarks and subsequently according to the individual paper mills, provided they are known.
As stated in Table 1, a total of 190 watermarks of Italian provenance have been found there and this is especially a result of the fact that the orchestra repertoire[23] was mainly secured by means of the purchase of instrumental parts from the Viennese professional copyist workshops. They used light, delicate Italian paper which was mainly imported from the areas of Lombardy, the area around Venice or Friuli-Venezia Giulia (Toscolano, Bergamo, Vaprio, Venice, Cordenons (= Pordenone) etc.). There are a total of 60 newly identified Czech watermarks, whereby a further 117 have not yet been designated, but a certain part of this group will most probably be identified in time. In addition, German (27), French (11), Austrian (8), Dutch (7) and Swiss (6) watermarks have also be found.
The watermarks from the printed music, which constitutes approximately one third of all the material, have also been recorded here for the first time. As well as sheet music published by German (Berlin, Dresden, Leipzig and Offenbach am Main), Dutch (Amsterdam), French (Paris), Italian (Florence, Venice) or Czech publishing houses (Prague), an extensive collection of sheet music published in Vienna (Artaria & Comp., Giovanni Cappi, Christoph Torricella, Johann Traeg, Joseph Eder, K. K. Hoftheater-Musikverlag, Ludwig Maisch, Thadé Weigl, Tranquillo Mollo, Chemische Druckerei etc.) has also been preserved.
Watermarks in printed sheet music
Given the fact that the goal of the Prague RISM workgroup (and also the team involved in the watermark research) is to fully process the music collections, including any printed sheet music, the watermarks from this type of document have also been included in the watermark database. The presence of watermarks in sheet music has been somewhat neglected to date, but it has been shown that interesting findings can also be made here and that in certain cases a watermark can be used, for example, to identify fragments or to elaborate on the origins of those pieces of sheet music, which are lacking any publishing information.[24] The watermark database can now be used to search according to the publishers who used a specific type of paper to print music. It has been supplemented with dates which are most frequently derived from the number of the printing plate. In the case of the Viennese printed sheet music, which constitutes a significant set of the sources not only in the aristocratic music collections, we have used the publisher catalogues compiled on the basis of source research or according to the period sales catalogues of the individual companies. These lists, which have been compiled by Alexander Weinmann and published in the Beiträge zur Geschichte des Alt-Wiener Musikverlages series, constitute an important tool for dating these printed documents. In the case of Czech publishers, we have been able to make use of Karel Chyba’s inventorial work Slovník knihtiskařů v Československu od nejstarších dob do roku 1860.
Let us once again return to the music collection of Count Clam-Gallas or to the printed part thereof. This involves the first collection in which the printed sheet music has been researched from the point of view of the watermarks. The temporal focal point, for example, of the aforementioned Viennese printed sheet music is around the year 1800. The following table sets out the paper mills which supplied material to ten Viennese publishing houses between 1800 and 1812. As is apparent here, not only Italian paper was used, but also German and Italian paper (Kiesling, Vrchlabí).
Tab. 4a. List of the kinds of paper used in 10 Viennese publishing houses between 1800–1812 based on the watermark registration of music prints in the collection of Count Clam-Gallas from Frýdlant (CZ-Pnm). *Marked music print is not from this collection, but from music collection of the National Library of the CR (CZ-Pu).

Tab. 4b. List of watermarks and paper mills.
|
|
Watermark (RISM, BWV) |
Paper maker, paper mill |
|
A |
GA | F [in shield] / [3 crescents] |
Fratelli Andreoli, Toscolano (Lombardia, Italy) |
|
G 1 |
[crescent] | [star (6 points) in shield (crowned)] / VG |
Valentino Galvani, Cordenons (Friuli-Venezia Giulia, Italy) |
|
G 2 |
[3 stars (6 points, 4 points) in shield (crowned), crescent above] / VG |
|
|
G 3 |
VG |
|
|
H |
Luzern / Hartmann | 1802 [in shield] |
Hartmann, Luzern (Switzerland) |
|
K 1 |
GEBR: KIESLING |
= Gebrüder Kiesling, Vrchlabí (Czech Republic) |
|
K 2 |
G. KIESLING |
|
|
K 3 |
13 / KIES[LING] |
|
|
K 4 |
GEBR KIESLING |
|
|
M 1a |
[crescent] | [star (6 points) in shield (crowned)] / P. A. M. (no. 1) |
P. A. Mathes, Unter-Waltersdorf (Austria) |
|
M 1b |
[crescent] | [star (6 points) in shield (crowned)] / P. A. M. (no. 2) |
|
|
M 2 |
P. A. M. / [crescent] | [star (6 points) in shield (crowned)] |
|
|
M 3 |
P. A. M. |
|
|
U |
[coat of arms with wolf (standing in profile)] | IAV | WOLFEG |
Joseph Anton Unold, Wolfegg (Baden-Württemberg, Germany) |
The conclusion
The systematic study of watermarks requires continual vigilance during research into the sources, accuracy, an aesthetic sense when drawing the watermarks or a critical view when evaluating the countermarks. The watermarks in music sources are bearers of information and they can also be valuable aids in such serious matters as authorship or the year of the creation of the piece of music. The sense of this research lies in finding links between the watermarks (the commercial brand of the paper from the specific time and place) and the actual music, individuals, places or events. The known and generally accepted terminology and the strict rules for the description of countermarks enable the cataloguing and subsequent searching for both individual components and complete watermarks using the database. The English terminology and the description principles have been adopted from the cataloguing practice of the RISM database and therefore the watermark database is especially user friendly to researchers who work with the international catalogue of music sources. It has therefore grown out of the already introduced system as an additional tool for the area of the description of watermarks and it enables the understanding of the context within the framework of the individual music collections and the relationships which they may have in common, including on an international scale.
In conclusion, I would like to thank all my colleagues who have contributed to the watermark research at the National Library of the Czech Republic: Mgr. Zuzana Petrášková, Bc. Lucie Havránková, Mgr. Lucie Slivoňová, Bc. Štefánia Demská, Mgr. Jakub Michl and Dr Michaela Freemanová, Ph.D. Special thanks goes to Mgr. Radovan Zahořík for the technical realisation and operation of the watermark database and for his technical support.
The list of used literature
BASTLOVÁ, E., 2013. Collectio operum musicalium quae in Bibliotheca Kinsky adservantur. 1. vyd. Pragae: Národní knihovna ČR. 381 s. Catalogus artis musicae in Bohemia et Moravia cultae. Artis musicae antiquioris catalogorum series; vol. VIII. ISBN 978-80-7050-626-4.
EINEDER, G., 1960. The Ancient Paper-mills of the Former Austro-Hungarian Empire and their watermarks. Monumenta chartae papyraceae historiam illustrantia 8. Hilversum, Holland: Paper Publications Society.
CHYBA, K., 1966. Slovník knihtiskařů v Československu od nejstarších dob do roku 1860. [Prague]: the Museum of Czech Literature.
SEMERÁDOVÁ, P. a E. ŠEDIVÁ, 2016. Catalogus collectionis operum artis musicae de Monasterii Siloensis. 1. vydání. Pragae: Národní knihovna ČR. 2 volumes (660 pages). Catalogus artis musicae in Bohemia et Moravia cultae. Artis musicae antiquioris catalogorum series; vol. IX/1-2. ISBN 978-80-7050-664-6.
WEINMANN, A., 1979. Vollständiges Verlagsverzeichnis Senefelder, Steiner, Haslinger: (Wien 1803-1826). Bd. 1, A. Senefelder, Chemische Druckerey, S. A. Steiner & Comp. München: E. Katzbichler. Musikwissenschaftliche Schriften; Bd. 14. Beiträge zur Geschichte des Alt-Wiener Musikverlages; Reihe 2. F. 19. ISBN 3-87397-113-5.
ZUMAN, F., 1921a. Přehled papíren v Čechách v 17. století. Český časopis historický XXVII. [Prague], p. 162–170.
ZUMAN, F., 1921b. Privilegium papírny jáchymovské. Památky archeologické XXXII. [Prague], p. 259.
ZUMAN, F. 1921c. Papírna v Prášilech. Zlatá Praha XXXVIII. [Prague: J. Otto], p. 183–185.
ZUMAN, F., 1922a. Filigrán mimoňský a hamerský. Památky archeologické XXXIII. [Prague], p. 158–160.
ZUMAN, F., 1922b. Inventář bělské papírny z r. 1723. Památky archeologické XXXIII. [Prague], p. 344.
ZUMAN, F., 1923. České filigrány XVI. století. Památky archeologické XXXIII. [Prague], p. 277–286.
ZUMAN, F., [1927a]. České filigrány XVII. století. Památky archeologické XXXV. [Prague: nákl. vl.], p. 442–463.
ZUMAN, F., 1927b. Papírny Starého města pražského. Technicko-průmyslový archiv 1. Prague: The Czechoslovak Technical Museum in Prague IV
ZUMAN, F., 1931a. Přehled papíren v Čechách v 18. století. Český časopis historický 38. [In Prague: F. Zuman]. p. 80–90, 294–316.
ZUMAN, F., 1931b. Papírna trutnovská. In Prague: Printed by the Royal Bohemian Society of Sciences.
ZUMAN, F., 1932. České filigrány XVIII. století. Rozpravy České akademie věd a umění, tř. I, č. 78. In Prague: Printed by the Czech Academy of Sciences and Art.
ZUMAN, F., 1934a. České filigrány z první polovice XIX. století. Rozpravy České akademie věd a umění, tř. 1, čís. 81. In Prague: Printed by the Czech Academy of Sciences and Art.
ZUMAN, F., 1934b. Pootavské papírny. In Prague: the Royal Bohemian Society of Sciences
ZUMAN, F., 1936. Posázavské papírny. In Prague: the Archive for the History of Industry, Trade and technical Work.
ZUMAN, F., 1940. Podkrkonošské papírny. In Prague: Printed by the Czech Academy of Sciences and Art.
[1] A watermark is an imprint of a visual symbol or inscription made using copper or brass wire attached to the screen of the wooden frame so that its elevation above the screen causes a weakening of the layer of the pulp and leads to the creation of the paper mill’s logo. The watermark not only designates the actual product (it protects both the paper mill and the purchaser), but also its quality, type and format. The use of the visual symbol by the paper mill was not in any way random. It spoke of the place of origin by means of heraldry and respected the family traditions or the owners of the paper mills or the wishes of the suzerain who had issued the producer with authorisation (the privilege) to operate the paper mill. Watermarks substantiate the existence of the used paper in a certain period and clarify its origins. They therefore constitute a substantial component of the sources and are bearers of information.
[2] Available from: http://www.rism.info/.
[3] When entering the locations from the area of Moravia and Silesia, we have so far used Georg Eineder’s extensive compendium (EINEDER, G., 1960) and other smaller works focusing on specific paper mills.
[4] Available from: www.nkp.cz.
[5] Available from: http://aleph.nkp.cz/web/watermarks/eng/bohemian_papermakers_vocabulary.pdf.
[6] The mould in which the paper was produced consisted of a frame, a screen and a top frame. The screen consisted of finer wires places close to one another, which reinforced the frame internally. The mark of the screen can be seen on the sheet as a faint dense horizontal line. The warp has a similar function and it was wired vertically within the form, this time using thicker wires. The watermark was soldered to the warp. These vertical lines can be marked in the tracings with sequence numbers, but the counting from left to right is only noted in those cases when the entire uncut sheet of paper is available. We have, however, come across cases where the warp was wired both vertically and horizontally.
[7] It is often possible to identify the copyist or the copyist workshop or to clarify the date thanks to the watermarks, especially in the case of extensive and less clear collections which require a systematic approach both before processing and during the work.
[9] Available from: http://aleph.nkp.cz/web/watermarks/cze/intro.htm.
[10] This involves the catalogue number, under which the watermark tracings are physically stored at the Music Department of the National Library of the Czech Republic.
[11] A (Austria), CH (Switzerland), CZ (the Czech Republic), D (Germany), GB (Great Britain), I (Italy), PL (Poland), N (the Netherlands), F (France), [n] (undesignated, but this may involve Czech paper in a number of cases based on the quality and the types of countermarks).
[12] We consider shields (like cartouches) to be one of the regular parts of a watermark, while other symbols (this may involve individual components) are often located inside the shield or the cartouche.
[13] „ …the Archive of the Ministry of Internal Affairs, Commerciale 1796‒1805, 6/2: The report of the Burgomaster in Stříbro dating from 9th September 1796 …“ (ZUMAN, F., 1932, p. 28).
[14] According to our findings to date, this label was used, for example, by J. A. Appeltauer’s paper mill in Velhartice, J. A. Heller’s paper mill in Ledeč nad Sázavou, T. Halík in what is now Havlíčkův Brod or the Kiesling family in Vrchlabí.
[15] EINEDER, G., 1960, p. 129. Zuman states that M. Ševčík was active as early as in 1799 (ZUMAN, F., 1931a, p. 308).
[16] This involves the publication of two Nationalgesänge by Bedřich Dionys Weber commissioned by Johann Ferdinand Schönfeld and František Jeřábek in Prague which have been preserved in the collection of Count Christian Clam-Gallas of Frýdlant, which is now stored at the National Museum – the Czech Museum of Music (CZ-Pnm/ sig. XLII C 276). RISM A/II: 551006815. Dated copies from 1807 have also been preserved (CZ-Pu, without provenance), 1815 (Želiv, in: CZ-Pnm), 1817 (Kinsky, in: CZ-Pn).
[17] The music collection in the Kinský Library (the Library of the National Museum, CZ-Pn) was entered into the RISM database in 2010. The watermarks from this collection were later included in the watermark database in the form of photographs. The thematic catalogue for the collection with a brief description of the watermarks was published in 2013 (BASTLOVÁ, E., 2013).
[18] The following text is a modified extract from the introduction to the watermark catalogue (SEMERÁDOVÁ, P. – ŠEDIVÁ, E., 2016, p. 95–97.
[19] The watermarks have been arranged in the catalogue a) according to the paper mill (watermarks which have been able to be identified have been included in this group according to the paper mill they belonged to and arranged chronologically according to the dates in the Želiv sources (W 1-75), b) according to the individual symbols (if the origins of the watermark have not been confirmed, W 76-163), c) the initials and inscriptions arranged alphabetically (W 164-198) and d) poorly legible watermarks (W 199-226) are named in the table without a pictorial section. The comprehensive photographic documentation of the watermarks was undertaken when processing the collection for the RISM database. As such, there are also photographs of those watermarks which we have not been able to include in the catalogue due to their lack of physical integrity, incompleteness or illegibility.
[20] Hereafter, the dates stated next to a paper mill owner indicate the period when he was active.
[21] The symbol of the post horn is usually found on writing paper, which is noticeably finer than other paper, but, as the sources from the Želiv collection (and others) have substantiated, this paper was also used for writing music.
[22] The thematic catalogue of the Clam-Gallas music collection is under preparation and is planned as a further publication in the Catalogus artis musicae in Bohemia et Moravia cultae edition of the National Library of the Czech Republic.
[23] Symphonies, divertimentos and chamber music most frequently by the following authors: J. K. Vaňhal, J. Haydn, J. Schmittbauer, F. X. Dušek, J. Chr. Bach, V. Pichl, C. Stamitz, A. Fils, F. L. Gassmann, K. F. Abel and T. S. Müller etc.
[24] Let us state the example of the identification of fragments of printed sheet music using the watermark database in the case of sheet music from the collection of the Monastery Church of the Nativity of Our Lady in Želiv (CZ-ZEL/ sig. Hu 20, in: SEMERÁDOVÁ, P. and E. ŠEDIVÁ., 2016, no. 583, RISM A/II: 551001585). 14 printed instrumental parts were found for an A major clarinet concerto, but, along with the title page, page 1 in the solo clarinet part which contained the first incipit (which was crucial for the identification of the work) was missing. The incipits of the other movements were not identified in either the RISM database or the UMC. The author of the piece and the publisher were therefore unknown. The number of the printer’s plate in all the parts was “1515” and the watermark with the inscription GEBR KIESLING was the only guide to identifying the sheet music. The watermark, newly listed in the watermark database, was used, amongst others, by the Viennese Chemische Druckerei. The publisher’s catalogue from this printing works listed Franz Alexander Poessinger’s (1767‒1827) clarinet concerto under no. 1515 (WEINMANN, A., 1979, p. 88). In cases such as this, it is possible to use the watermark as a guide towards the publishers and printers and at the very least to reduce the list of possible candidates.


















































