KEYWORDS: Teplice, Rumburk, church music, composers, choir masters, 19th century, Deutschböhmen
Mgr. Ludmila Mikulášová, Ph.D. / Národní knihovna České republiky (National Library of the Czech Republic), Mariánské náměstí 190/5, 110 00 Praha 1

KEYWORDS: Teplice, Rumburk, church music, composers, choir masters, 19th century, Deutschböhmen
Mgr. Ludmila Mikulášová, Ph.D. / Národní knihovna České republiky (National Library of the Czech Republic), Mariánské náměstí 190/5, 110 00 Praha 1
KEYWORDS: digital libraries, copyright law, artificial intelligence, text and data mining, legal licenses, machine translation, automatic summarization, Czech Republic
JUDr. Bc. Lucie Smolka, Ph.D. / Lawado | law of ideas, Táborská 2370/189, 615 00 Brno
Mgr. Jana Hrzinová / Národní knihovna České republiky, Mariánské náměstí 190 /5, 110 00 Praha 1
Mgr. Václav Jiroušek / Národní knihovna České republiky, Mariánské náměstí 190/5, 110 00 Praha 1
Mgr. Lenka Maixnerová / Národní knihovna České republiky, Mariánské náměstí 190/5, 110 00 Praha 1
KEYWORDS: bees, beekeeping, entomology, early printed books, beehive, honey, National Library of the Czech Republic, provenance
Mgr. Markéta Bendlová / Národní knihovna České republiky (National Library of the Czech Republic), Mariánské náměstí 190/5, 110 00 Praha 1
KEYWORDS: transcription models, historical manuscripts, transcription of Czech documents, transcription of Slovak documents, Transkribus platform
prof. PhDr. Dušan Katuščák, PhD. (ORCID 0000-0001-7444-1077), Mgr. Klára Pohlová, Bc. Lukáš Němec, BcA. et Bc. Vojtěch Říha / Slezská univerzita v Opavě, Filozoficko-přírodovědecká fakulta, Ústav bohemistiky a knihovnictví (Silesian University in Opava, Faculty of Philosophy and Science, Institute of the Czech Language and Library Science), Masarykova třída 343/37, 746 01 Opava
KEYWORDS: disinfection, library, stamps, ink pencil, paper, conservation, butanol vapors, fixation
Introduction
Books and other types of library documents include various inscriptions and handwritten annotations, records of ownership, notes by readers, call numbers, and stamps of the document’s current and past owners, in addition to their texts. Such supplementary records are an important source of information about the book, its previous owners, readers, and the location where the book was created and stored. Especially, it is necessary to preserve library records without any changes. Such notes are not always made using durable, stable inks or dyes. This also applies to stamp inks. Currently, archival-quality inks and stamp inks, which are intended to be permanent, are preferred for registration records. However, very unstable ink pencils were used in the past, even in historical collections, reacting with a wide range of solvents of both polar and non-polar nature. The protection and eventual fixation of such records is an important part of any conservation or restoration actions on a book. Any possible dissolution and activation of a writing substance will not only make it impossible to identify the item in library records, but also means an irreversible damage to the document itself.
In the field of document disinfection, alcohols are one of the oldest antiseptic agents effective in high concentrations against a wide range of bacteria, fungi, and also against many viruses. The mechanism of action of alcohols on filamentous fungi consists in the coagulation of proteins in cell walls and cytoplasmic membrane. Alcohols also increase fluidity of lipids in cytoplasmic and mitochondrial membranes of fungi. This results in breakdown (lysis) of the outer cytoplasmic membrane, release of cell contents, and coagulation of enzymatic proteins (Karbowska-Berent et al., 2018). Some attempts to apply alcohols to decontaminate historical documents have been carried out in the past using various application methods and different concentrations. Aqueous alcohol solutions have been applied by spraying, immersion, and surface rubbing. A high efficiency of their vapours has also been demonstrated, which have proven to be very gentle on materials subject to treatment. It was found out that under certain conditions (enclosed compartment, 96% butanol solution, exposure time of 48 hours, temperature of 25 °C) both vegetative forms of fungi and their spores are eliminated (Orlita, 1991). However, Karbowska-Berent (2014) found unacceptable changes in some coloured media (print, ballpoint pens) when alcohol is applied by immersion. Bronislava Bacílková (2006) made similar observations in the National Archives‘ laboratories regarding pens, permanent ink/indelible pencils and markers, and established that with some types of writing materials, the text can dissolve or even bleed through to the paper’s reverse side. However, such orientation tests were only some auxiliary tests conducted while testing the effects of alcohol vapours on fungi. For this reason, further investigation was required to determine the stability of annotations, ink pencils and stamps and other recording media from a wide range of media (which we encounter in library documents) in butanol vapours, which have been used for many years in the National Library of the Czech Republic as a standard disinfectant for contaminated collections.
Experimental part
Objective of the work:
Alcohols, especially butanol, have been used for disinfection for a very long time. The recommended concentration varies between 50 and 90%, depending on specific conditions. Alcohol is used in the form of vapours to disinfect books and archival materials, as this application form has a very gentle effect on the materials being treated. However, with some writing materials, especially ink pencils, the text may dissolve and the colours may change. As mentioned above, preliminary tests of the solubility of writing materials have already been carried out in the past in the National Archives (Bacílková, 2003). The main objective of our work was to monitor visual changes in recording media, such as ink pencils and stamp inks, following exposure to butanol vapours under conditions set for the disinfection of library collections infected with fungi. Changes in the colour of the prepared samples were measured and any colour migration was documented by macro- and micro-imaging.
List of recording media:
Twelve different recording media (see Table 1) from the 1970s to 1980s were tested, including ink pencils (samples 1–8), stamp inks (samples 9, 11, 12) and fountain pen ink (sample 10). Red ink pencils are indicated by the index “a” in all the following graphs and tables, while blue ink pencils are indicated by the index “b”.
Ink pencils – a pencil lead in a wooden casing, pencil leads of different compositions and colours: classic silver, purple, red, and blue. The main component of ink pencils include water-soluble organic dyes, mostly anionic, such as Methyl Violet (C.I. Basic Violet 1), Malachite Green (C.I. Basic Green 4) or acid dyes such as eosin (C.I. Acid Red 87) (Ďurovič et al., 1999).
Stamp inks can be divided into metal and rubber stamp inks. Stamp inks are applied to paper by pressing a rubber or metal stamp immersed in a dye. Oil-free rubber stamp inks have been tested, which consist of cationic dyes dissolved in a mixture of water, glycerine or higher glycols and alcohols. In contrast to metal stamps, which have an oil composition that is insoluble in water, oil-free stamp inks are more or less readily soluble in water. Violet, blue and black stamp inks contain cationic dyes, while red and green stamp inks contain anionic dyes. Blue ink was mainly produced from basic arylmethane dyes (Basic Blue 11, Basic Blue 26, and Basic Blue 52, formerly Basic Violet 1, Basic Violet 3, and Basic Blue 9). Black paint was most often produced from stable nigrosine dyes (Ďurovič, 2002) (Maková, 2019).
Fountain pen ink is a mixture of synthetic tar dye in distilled water, preservatives (phenol, formaldehyde), and pH adjusters (acetic acid, sodium carbonate). An anionic red ink was tested, probably made of the bluish xanthine dye eosin B (Acid Red 91). Red fountain pen ink from around the 1980s (sample no. 10) was used to replace red stamp ink from the same period of time (Ďurovič, 2002).
The exact chemical composition of the recording media was determined for samples 1, 2, 8a and 8b (see Table 1) by LC/MS analysis performed at the Central Laboratory of the Institute of Chemical Technology, Prague. The analyses were performed on a high-resolution LTQ Orbitrap Velos (Thermo Scientific) mass spectrometer in several ionization modes: ESI+ (electrospray ionization in positive mode), ESI− (in negative mode), APCI+ (atmospheric pressure chemical ionization in positive mode) and APCI−. The extracted solutions of the recording media were injected into the mobile phase stream (methanol) via a 10 µl injection loop (Rheodyne).
Based on the results of the analysis, it was found that the Hardtmuth Koh-I-Noor silver ink pencil (sample no. 1) contains dyes based on a mixture of Methyl Violet 10B, 6B, and 2B. In the Mephisto ink pencil (sample no. 2), a dye composed mainly of Methyl Violet 10B was identified. The Hardtmuth Koh-I-Noor red ink pencil (sample no. 8a) contains the Solvent Red 43 dye, while the Koh-I-Noor blue ink pencil (sample no. 8b) shows the presence of the Acid Blue 93 dye.
Table 1 List of recording media used
| Set number | Recording medium: |
|---|---|
| 1 | Ink pencil Hardmuth Koh-I-Noor silver |
| 2 | Ink pencil Hardmuth Koh-I-Noor Mephisto purple |
| 3 | Ink pencil Hardmuth Koh-I-Noor COP 1561 Hard silver |
| 4 | Ink pencil Hardmuth Koh-I-Noor Versatil 5205 silver |
| 5 | Ink pencil L.C Hardmuth Mephisto COP 73B Medium silver |
| 6 | Ink pencil Bohemia Works Bluestar COP 2726 Soft silver |
| 7 | Ink pencil SUNPEARL 3453 red/blue |
| 8 | Ink pencil Hardmuth Koh-I-Noor COP 1561 E/G red/blue * |
| 9 | Stamp ink for textile NORIS 325 black |
| 10 | Ink for fountain pens Koh-I-Noor MSP 4201 red |
| 11 | Oil-free stamp ink for rubber stamps GAMA JK 738 341 blue |
| 12 | Oil-free stamp ink for rubber stamps J.P.K CHEM JK 738 341 blue |
Work procedure:
Test 1: Simultation of Disinfection of Freshly Applied Inks
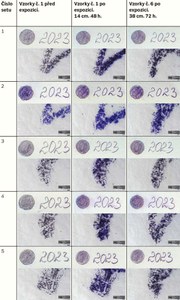
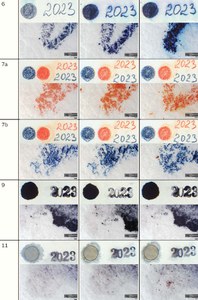
In the first test, the conditions of disinfection in butanol for freshly applied inks were investigated. For this purpose, twelve sets of samples were prepared. Each set contained six samples with inscriptions made using one of the recording media on handmade paper. The list of the recording media is given in Table 1. The samples of the recording media were applied to handmade paper from Velké Losiny, with a grammage of 240 g/m2. This is a hand-drawn graphic paper without transparency. The paper is made of a mixture of linen and cotton. The dimensions of the paper samples were 5 × 2.5 cm. The inscription “2023” was written on each sample with the selected recording media and a solid circle with an approximate diameter of 1 cm was created. Each sample was further marked with the sample number and set number (see Fig. 1). Rubber stamps were used to apply the stamp colours.

Fig. 1 Photograph of a sample taken with VSC 8000 in incident visible spectrum lighting (A. Kazanskii, National Library of the Czech Republic)
In the recording media sample sets prepared, their colour was measured in the spectrophotometer mode of the VSC 8000 (Foster + Freeman) video spectral comparator, hereinafter referred to as "VSC". The colours were analysed in a solid circle in three places with the calculation of the average values of colour change (see Fig. 2). Subsequently, individual samples were photographed using VSC in incident visible spectrum lighting (see Fig. 1).

Fig. 2 Sample colour measurement performed using VSC in spectrophotometer mode (A. Kazanskii, National Library of the Czech Republic)
The microphotographs of the recording media were taken using a Hirox RH-2000 3D digital microscope with the MXB 2500 lens at a mid-range 200× magnification and a light position of 34–32. The microphotographs were taken in the same area for all samples, at the bottom edge of the first number "2" of the inscription "2023" (see Fig. 3).
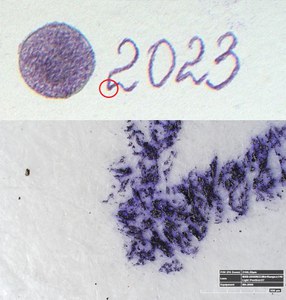
Fig. 3 Macro- and microimages of the sample made with the VSC and the Hirox RH-2000 3D digital microscope (A. Kazanskii, National Library of the Czech Republic)
All sets of samples were subsequently exposed to vapours of 94–96% 1-butanol solution (Penta s.r.o.) with water, in a hermetically sealed ARTWET disinfection chamber. The evaporation of the aqueous alcohol solution was ensured by open Petri dishes with a butanol solution, which were placed at the bottom of the disinfection box. The amount of solution corresponded to the volume of 900 ml of aqueous solution per 500 dm³ chamber. The samples were placed on cardboard, which simulated the cover of a book. They were placed on three retractable silicone meshes at distances of 14, 26, and 38 cm above the Petri dishes (see Fig. 4 and 5). The simulated disinfection process itself took place for 48 and 72 hours. Each sample in the set (a total of 6 samples) corresponded to specific disinfection conditions, particularly the combination of distance from the butanol source and the duration of action. Throughout the process, the temperature and relative humidity were monitored both inside the chamber and in the room.

Fig 4 Samples of ink pencils and stamps on cardboard in a hermetically sealed disinfection box (R. Zembjaková, National library of the Czech Republic)

Fig 5 A more detailed view of samples of ink pencils and stamps on cardboard in a hermetically sealed diinfection box (R. Zembjaková, National Library of the Czech Republic)
Test 2: Simulation of Disinfection of "Activated" Inks
To simulate the disinfection of "activated" inks, eight sets of samples containing all types of water-soluble ink pencils (sets 1-8, see Table 1) were prepared. During the application of the media to the paper, a small amount of distilled water was added locally to increase the reactivity of the inks. In all other respects, the procedure for preparing and disinfecting samples remained the same as in the first test. The aim of the activation was to partially simulate the application of a moistened ink pencil nib, the aging of the ink and its response to changes in external relative humidity over time. This test is for reference only and is used to observe the ink in different states. The application procedure described cannot be considered artificial aging.
Test 3: Simulation of Disinfection of Recording Media Fixed with Cyclododecane
Twelve sets were prepared to simulate the disinfection of fixed recording media (see Table 1). In this test, ink fixation was performed by applying a cyclododecane solution, followed by applying molten cyclododecane (Paulusová, 2000). A solution of cyclododecane/petroleum benzine was prepared by dissolving 10 g of cyclododecane in 8 g of petroleum benzine while stirring at normal laboratory temperature. The solution was applied using a small brush to the samples from both sides. Molten cyclododecane was prepared by dissolving cyclododecane in a solder attachment while maintaining a constant temperature of 70 °C. The molten material was applied with a small brush on both sides of the paper, creating a visible crust. In all other details, the sample preparation and disinfection procedure remained the same as in the first test.
Test 4: Simulation of Disinfection of Recording Media Fixed with Mesitol and Rewin Solutions
Twelve sets of samples were prepared to simulate the disinfection of fixed recording media (see Table 1). Ink fixation in Test 4 was carried out using the application of 1.2% Mesitol NBS solution and 6% Rewin EL solution (Bredereck 1988). The Mesitol NBS anionic agent was prepared by dissolving powdered Mesitol under constant stirring in deionised water. The liquid concentrate of the Rewin EL cationic agent was diluted to a 6% aqueous solution. The solution was applied by the immersion method, which proved to be the most gentle option for the recording media in this test.
For anionic agents such as ink pencils and fountain pens (sets 1-8 and 10, see Table 1), the samples were first immersed in the Rewin solution. After drying, they were immersed in the Mesitol solution. For cationic stamp inks, the procedure was reversed: the samples were first immersed in the Mesitol solution and then in the Revin solution. Finally, all the samples were thoroughly dried.
In all other aspects, the sample preparation and disinfection procedure remained the same as in the first test.
Results and Summary
Disinfection Temperature and Humidity
During the experiment, the room temperature ranged between 22.0 and 23.6 °C, and the relative humidity between 23.9 and 31.8 %. The temperature in the hermetically sealed box reached approximately the same values as in the room, but the relative humidity gradually increased, up to 79% in 40 hours (see Fig. 6). The minimum time required for effective disinfection is 48 hours, but the risk of activation of recording media, binders, and undesirable changes may increase.
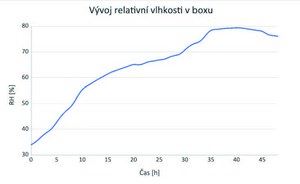
Fig 6 Development of relative humidity in a hermetically sealed box in standard 48-hour disinfection procedure
Results of test 1:
When measuring the colour changes of the samples, the results were expressed through the coefficient of overall colour change ∆E, which is a generally accepted indicator for monitoring colour differences. For better orientation, a scale was set to determine the degree of difference between two colours. Colour changes of ∆E less than 0.2 are considered negligible, changes ranging from ∆E from 0.2 to 0.5 are considered very small, changes ranging from 0.5 to 1.5 are considered small, changes ranging from 1.5 to 3 are considered clearly perceptible, changes ranging from 3.0 to 6.0 are considered medium, and ∆E above 6 indicates a high colour difference (Zmeškal 2002).
In the first test, the ∆E values for silver ink pencils (sets 1-6) exceeded 10, while for the purple Mephisto ink pencil they amounted to about 8. This indicates that there were significant and clearly visible changes in colour due to exposure (see Fig. 7). Such changes, including ink bleeding, are clearly visible in the macro- and micro-photographic documentation (see Table 2). The change in colour after 72 hours of exposure was dependent on the distance of the samples from the source of butanol, with the lowest values being achieved at a distance of 38 cm. The main effect that can be observed on microphotographic documentation is significantly lower degree of the medium’s bleeding. Water-soluble polar organic dyes are the main ingredient in silver ink pencils. The reason for such significant changes in colour and bleeding can be both high relative humidity and high concentration of butanol in the atmosphere during disinfection.
Minor colour changes were observed in the case of coloured ink pencils (sets 7-8), with the ∆E value reaching approximately 6, which corresponds to a moderate colour change (see Fig. 7). No bleeding was found. This suggests that the composition of the selected blue and red ink pencils shows higher resistance to water solubility and butanol vapours.
Stamp ink from set 9 showed significant ink bleeding during exposure in areas with a higher layer of ink. The intensity of such bleeding was dependent on the distance of the samples from the butanol source (see Table 2).
For liquid fountain pen inks and stamp inks (sets 10-12), even minor colour changes were recorded, with the ∆E value ranging from 1.5 to 3. There was also no bleeding of the recording media during the test, indicating a high resistance of such media to water solubility and butanol vapours (see Fig. 7).
For clarity, all tables with photographic documentation show three states of the samples: 1) state before disinfection, 2) state after disinfection with a minimum exposure time of 48 hours and a distance of 14 cm from the butanol source, 3) state after disinfection with maximum exposure time and distance.
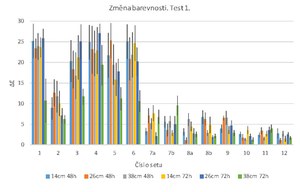
Fig. 7 Overall colour change ∆E of all sets in Test 1 as a function of exposure time and distance from the butanol source. Exposure time: 48/72 hours. Distance from butanol sources: 14/26/38 cm.
Table 2 Comparative macro- and microimages of Test 1 samples made using the VSC (upper part of the images) and the 3D digital microscope. Comparison of pre-exposure samples with post-exposure results. For the demonstration, exposure times of 48/72 hours and distances from butanol sources of 14/38 cm were selected. (A. Kazanskii, National Library of the Czech Republic)
Results of Test 2:
Already during sample preparation and the reaction of the colour component of the inks with water, all ink pencils (sets 1-6) underwent a significant colour change, with the ∆E value exceeding 10. On the other hand, blue and red ink pencils (sets 7-8) retained their original hue.
After the second test was conducted on all "activated" silver and coloured ink pencils (sets 1-8), the values of the overall colour change ∆E did not exceed ∆E = 5.7, regardless of the exposure time and the distance of the samples from the butanol source (see Fig. 8). This means that there were visible to invisible changes in colour as a result of exposure. The main change was in the slight bleeding of the ink, which is particularly evident at the edge of the record‘s trace on the microphotographic documentation, especially in silver ink pencil samples (see Table 3). In this test, we can assume that the relative humidity did not affect the change in the colour of those samples that had previously undergone a reaction with water. The main factor in the changes here may have been the effect of butanol, leading to further ink bleeding. With the exception of set 6, the observed adverse effect decreased with increasing distance from butanol sources, but did not affect the resulting ∆E values (see Table 3).
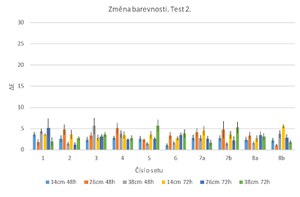
Fig. 8 Overall colour change ∆E of all sets of Test 2. Exposure time: 48/72 hours. Distance from butanol sources: 14/26/38 cm.
Table 3 Comparative macro- and microimages of Test 2 samples made using the VSC (upper part of images) and the 3D digital microscope. Comparison of pre-exposure samplse with post-exposure results. For the demostration, the exposure time is 48/72 hours and the distance from butanol sources is 14/38 cm. (A. Kazanskii, National library of the Czech Republic).
Results of Test 3:
The measurement of colour change in this test was complicated by the presence of a thick, gradually evaporating layer of cyclododecane on the surface of the recording media. This factor affected the reproducibility of the measurements and the resulting standard deviation values. The average values of ∆E in Test 3 differed only to a minimum extent from the results of Test 1, which indicates that under such conditions cyclododecane fixation can be considered as a less effective protection measure against the undesirable effects of disinfection (see Fig. 8).
As a result of exposure, all silver ink pencils underwent significant and clearly visible colour changes, with ∆E values exceeding 15. For the Mephisto purple ink pencil (set 2), the ∆E value reached approximately 8. The inks were bleeding regardless of the distance of the samples from the butanol sources and the exposure time. These results are evident in macro- and micro-photographic documentation (see Table 4). Minor colour changes were observed in coloured ink pencils (sets 7-8), with ∆E values ranging from 5 to 10. They also did not bleed during the test.
For stamp ink from set 9, there was still some ink bleeding during the exposure. For liquid fountain pen ink and stamp inks (sets 10-12), like in Test 1, the lowest degree of colour changes in the range ∆E from 2 to 8 and minimum degree of bleeding were observed (see Table 4).
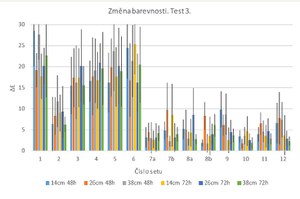
Fig. 9 Overall colour change E of all sets of Test 3. Exposure time: 48/72 hours. Distance from butanol sources: 14/26/38 cm.
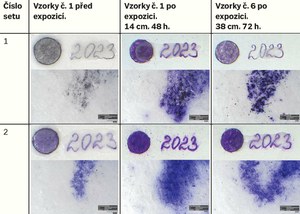
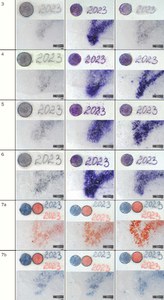
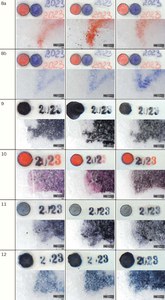
Table 4 Comparative macro- and microimages of Test 3 samples made using the VSC (upper part of the images) and the 3D digital microscope. Comparison of pre-exposure samples with post-exposure results. For the demonstration, the exposure time is 48/72 hours and the distance from butanol sources is 14/38 cm. (A. Kazanskii, National Library of the Czech Republic)
Results of Test 4:
Ink fixation in Test 4 using 1.2% Mesitol NBS solution and 6% Rewin EL solution can be considered as a partially effective method to protect against the adverse effects of disinfection. Unlike in Test 1, in which the inks were not fixed, the resulting average ∆E values for silver ink pencils (sets 1-6) in Test 4 were lower and dependent on the distance from the butanol sources. With an exposure time of 72 hours and a distance of 38 cm, the values for the silver ink pencils were below ∆E = 5.8, and below ∆E = 2.2 for the purple ink pencil (set 2). For the coloured ink pencil (set 7), there was an even smaller colour change, where the average value of ∆E reached 3. Unlike in Test 1, none of the ink pencils underwent bleeding. In the case of the stamp ink (set 9), it did not bleed during the exposure only at a greater distance from the butanol sources (28–38 cm). The stamp ink (set 11) measured showed lower to medium colour changes ∆E in the range from 1.1 to 3 (see Fig. 9).
For the ink pencil (set 8), fountain pen ink (set 10), and stamp ink (set 12) sets, there was considerable bleeding during fixation by immersion in the Revin or Mesitol NBS solutions, which made it impossible to achieve reproducible results. In sets 6, 7 and 11, a slight but still undesirable bleeding was observed during fixation, as can be seen in the photographic documentation (see Table 5). Such reactions of the recording media constitute a fundamental flaw in the method. Based on the tests conducted, it has been shown again that before each application of solutions of the Mesitol NBS and Rewin fixatives, it is necessary to conduct combined solubility tests and, if necessary, use solutions with different concentrations adapted to specific types of recording media (Bredereck 1988).
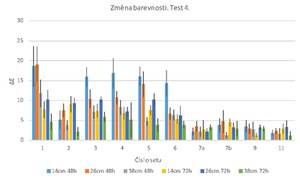
Fig. 10 Overall colour change ∆E of all sets of Test 4. Exposure time: 48/72 hours. Distance from butanol sources: 14/26/38 cm.
Table 5 Comparative macro- and microimages of Test 4 samples made using the VSC (upper part of the images) and the 3D digital microscope. Comparison of pre-exposure samples with post-exposure results. For the demonstration, the exposure time is 48/72 hours and the distance from butanol sources is 14/38 cm. (A. Kazanskii, National Library of the Czech Republic)
Conclusion
Silver ink pencils proved to be the most problematic group of recording media that were tested. Under normal disinfection conditions, such inks significantly change colour and bleed, regardless of the distance from the source of butanol. Where silver ink pencils are water-activated before writing, a greater distance from the butanol source may reduce the rate of their bleeding and prevent further significant discolouration. A combination of Mesitol NBS and Revin EL solutions can be used to fix silver ink pencils, which reduces possible discolouration and minimises bleeding of recording media during disinfection. However, it is essential to carefully select the concentration of the solution and the method of its application. It is also recommended to perform a solubility test to avoid damage to the record. Purple ink pencils showed similar behaviour to silver ink pencils during the test, but the colour changes were less pronounced. Even smaller colour changes were observed with coloured ink pencils, such as red and blue. Such recording media showed moderate colour changes with no signs of bleeding.
Stamp inks and ink for fountain pens demonstrated significantly higher stability compared to silver ink pencils in the standard disinfection procedure. Such recording media showed a significantly lower colour change and most of them did not bleed. On the other hand, it has been shown that the fixation of these recording media using a combination of Mesitol NBS and Revin EL solutions bears a considerable risk due to the high probability of their dissolution during fixation. The ink for NORIS stamps (set 9) deserves special attention. Unlike other stamp inks, it showed significant bleeding during disinfection, with the degree of bleeding depending on the distance from the butanol source in the chamber.
The fixation method using cyclododecane proved to be ineffective in preventing changes in recording media during standard disinfection.
The tests conducted are only a simulation of the actual disinfection process, where other factors affect the activation of dyes in older records. Real-life aged records may have different environmental interaction characteristics and the dyes contained in them may be in a different chemical state as a result of natural aging. Therefore, further research will continue to test the interaction of naturally aged records with butanol vapours.
Bibliography:
BACÍLKOVÁ, Bronislava, 2015. Studium účinků par butanolu a jiných alkoholů na plísně. Online. Praha: Národní archiv. Available at https://old2.nacr.cz/wp-content/uploads/2015/11/butanol.pdf. [accessed on 2024-01-11].
BREDERECK, Karl a SILLER-GRABENSTEIN, Almut, 1988. Fixing of ink dyes as a basis for restoration and preservation techniques in archives. Restaurator. Issue 9, pp. 113-135.
ĎUROVIČ, Michal, 2022. Restaurování a konzervování archiválií a knih. Praha: Paseka. ISBN 80-7185-383-6.
ĎUROVIČ, Michal; DENDEROVÁ, Michaela; MATUŠÍK, Jan a STRAKA, Roman, 1999. Fixace novodobých psacích prostředků syntetickými polymery – studium odstranitelnosti a fyzikálně-chemických vlastností některých vybraných fixačních prostředků. In: X. seminář restaurátorů a historiků: Referáty. Litomyšl, 24.–27. září 1997. Praha: Pobočka ČIS při Státním ústředním archivu v Praze, p. 248.
KARBOWSKA-BERENT, Joanna, 2014. Dezynfekcja chemiczna zabytków na podłożu papierowym – skuteczność i zagrożenia. PDF. Toruň: Wydawnictwo Naukowe Uniwersytetu Mikołaja Kopernika. ISBN 978-83-231-3088-8.
KARBOWSKA-BERENT, J. et al., 2018. The initial disinfection of paper-based historic items – Observations on some simple suggested methods. Online. International Biodeterioration & Biodegradation. Vol. 131, pp. 60-66. ISSN 0964-8305. Available at https://doi.org/10.1016/j.ibiod.2017.03.001 [accessed on 2024-01-11].
MAKOVÁ, Alena a HAFKOVÁ, Zuzana, 2019. Záznamové prostriedky a možnosti ich fixácie pre vodné konzervačné procesy. Bratislava: MV SROV. p. 6-16. ISBN 978-80-971767-5-4.
ORLITA, Alois, 1991. Nový systém devitalizace plísní na historických písemnostech. In: Sborník 8. semináře restaurátorů a historiků, Železná Ruda – Špičák. Praha: Státní ústřední archiv v Praze. pp. 258-267.
PAULUSOVÁ, Hana, 2003. Využití cyklododekanu pro přechodnou fixaci vodorozpustných barviv. In: XI. seminář restaurátorů a historiků: Referáty, Litoměřice, 13.–16. 9. 2000. Praha: Státní ústřední archiv v Praze. pp. 250-255.
ZMEŠKAL, Oldřich; ČEPPAN, Michal a DZIK, Petr, 2002. Barevné prostory a správa barev. Online. Vysoké učení technické v Brně. Available at http://imagesci.fch.vut.cz/download/stud06_rozn02.pdf. [accessed on 2024-01-11].
KAZANSKII, Andrei; ZEMBJAKOVÁ, Rebeka a NEORALOVÁ, Jitka. Stálost inkoustových tužek a razítek v parách butanolu při standardním postupu dezinfekce. Knihovna: knihovnická revue. 2024, Vol. 35, Issue 2, p…ISSN 1802-3252.
]]>KEYWORDS: Bezno, Březno, Skalsko, church music, thematic catalogue, collection of sheet music, composers, teachers, choir directors, 18th century, 19th century
KEYWORDS: education, convents, monasteries, Middle Ages, manuscripts, incunabula, Benedictines, Domi- nicans, Poor Clares, Premonstratensians, reading, breviaries, psalters, Bible, Kingdom of Bohemia, Bohemia, women, book culture, vernacularization, German, Czech
Keywords: linked data, BIBFRAME, RDF, IFLA LRM, metadata, cataloguing, MARC format, library cooperation
This study was created on the basis of institutional support for the long-term conceptual development of the National Library of the Czech Republic as a research organization provided by the Ministry of Culture of the Czech Republic (DKRVO 2024-2028), Area 11: Linked Open Data.
Introduction
In December 2006, the Library of Congress (Washington, D.C.) established the Working Group on the Future for Bibliographic Control, led by José-Marie Griffiths (University of North Carolina, Chapel Hill). One of the Group's task was to collect new knowledge on the impact of standards for the processing of bibliographic and authority records and cataloguing procedures on the management of information resources in libraries and in their access to them in the new information and technological environment (Library of Congress, 2006).
In January 2008, the Group published an important report On the Record (Library of Congress. Working Group on the Future of Bibliographic Control, 2008). In chapter 3.1 Web as Infrastructure, the report stated that the MARC format is built on forty-year-old programming techniques and is not in line with the present day’s programming styles. The MARC format is used exclusively in the library environment and is not compatible with other systems working with bibliographic data. A broader use of bibliographic data requires a format that will accept and distinguish metadata created by experts, generated automatically, and created by users, including annotations (reviews, comments), and data on the use of the source.
Based on the recommendations formulated in this report, on October 31st, 2011, the Library of Congress announced the Bibliographic Framework for the Digital Age initiative, or BIBFRAME (Library of Congress, 2011).[1] The announcement of the BIBFRAME initiative was one of the important impulses in the development of new bibliographic data formats based on the RDF[2] (Resource Description Framework) model. One of the arguments for choosing the RDF model was the fact that it is a method recommended by the World Wide Web Consortium (W3C) for conceptual description or data modeling in the Web environment.
The use of RDF and other techniques supported by the W3C consortium generally allows for better integration of data from library systems and other cultural heritage systems in the Internet environment with the aim of advanced and broader user access to information (Library of Congress, 2011). One of the main results of this initiative is the creation of an ecosystem of models, ontologies and other tools for the creation and management of linked data with the same name BIBFRAME, which is gradually being implemented in selected library databases around the world.
In addition to the BIBFRAME format, another significant achievement in this area is the development of an RDF-based RDA ontology based on the RDA cataloguing rules: Resource Description and Access – Official version . RDA Official together with BIBFRAME represent two initiatives that influence one another and are also gradually complementary, which must be seen as successors to the MARC 21 format and the RDA cataloguing rules in the Original version (currently used in the Czech Republic) for bibliographic and authority data.
How will we reaspond to this development in the Czech Republic? Is it possible to gradually change the data formats in libraries in our environment? What would be neeeded to prepare for such a change to occur?
The Goal of the Study and the Methods Used
The goal of the study is to analyse the possibilities of implementation and use of linked data formats in the environment of Czech libraries. Based on the research and analysis of sources from other countries, we will introduce the topic of linked data formats and the possible advantages of their implementation. We will evaluate the current state of processing and cooperation in the field of bibliographic and authority data in the Czech Republic with a focus on preparing data for possible conversion into linked data formats. For the research, we used mainly the analysis of bibliographic and authority data of the Czech National Bibliography. We describe the processes of processing bibliographic and authority data in the Czech Republic. We identify areas for improving and optimizing the exchange and sharing of data in the library network, as well as for cooperation among libraries and surrounding systems, especially the publishing sector. We present the advantages of implementing linked data formats for collaboration in libraries and among libraries and surrounding systems in the Web environment. The study is intended to contribute an outline of a solution for the implementation of an ecosystem of linked open data in the Czech Republic.
From MARC to Linked Data
Bibliographic and authority data processing in the Czech Republic is shaped by a number of standards. MARC 21 has been used as the main exchange format since 2004, with the RDA Cataloguing Rules (Original version) being used in combination with the MARC 21 format starting from 2015. These international standards are supplemented by methodologies and interpretations published on the National Library of the Czech Republic’s website devoted to cataloguing policy. However, for over almost two centuries, a number of other standards and methods have been used in our territory. Many collections have historically been processed on cataloguing cards according to various standards. The cards only began to be converted into a machine-readable form in the 1990s onwards as part of retrospective conversion (machine reading of cards) or retrospective cataloguing (with a document in hand) projects. As a result, we can really find a mixture of many different approaches and rules in today's databases.
Since we have adopted MARC 21 as a standard in the Czech Republic in 2004, it might seem that it has been a relatively modern format. However, the opposite is true. MARC 21 closely follows its predecessors, whose creation dates back to the 1960s. Therefore, the format has gone through almost sixty years of history, and as discussed in the On the Record report (Library of Congress. Working Group on the Future of Bibliographic Control, 2008), it was created using relatively old programming and data management techniques, from today's point of view. The MARC 21 format is closely related to Anglo-American cataloguing procedures, its form was influenced by the form of a paper cataloguing card. It is still necessary to use punctuation according to the ISBD standard (International Standard Bibliographic Description) for the data structure in some fields and subfields. The overall structure is very outdated and inflexible. It cannot respond well to the present day’s data models (e.g., IFLA Library Reference Model, hereinafter referred to as IFLA LRM, Riva, 2017). The MARC 21 format is often used in library systems not only as an interchangeable data format. Library systems often offer forms for cataloguing based on individual fields of the MARC format, the fields are marked with appropriate tags, the librarian writes down the indicators, marks the individual subfields, and must use the prescribed punctuation.
MARC 21 (or other MARC formats) is used exclusively by the library community and is essentially incomprehensible to other systems used in memory institutions (archives, museums) or in publishing and book market systems. For the above reasons, as well as for the benefit of better communication of data within the broader environment of libraries on the Internet, and especially for easier communication of data in the Web environment, it would be more appropriate to abandon the MARC formats and start using formats based on more general standards also used outside library sector.
Libraries around the world have worked with MARC formats and related technologies (e.g., Z39.50) for a really long time, using them to share hundreds of millions of bibliographic and authority records. "Everything from system integration to all cataloguing work is built on the MARC 21 format," as the National Library of Sweden’s experts state (2019). It is therefore very difficult to put an end to such practice and start using completely new procedures and techniques. In order to evaluate the possibilities of converting existing bibliographic and authority data into linked data formats, it is necessary to examine in more detail the processes of creating bibliographic and authority records in the Czech Republic and especially the cooperation in their creation.
First of all, we will explain in more detail how to work with linked data in libraries abroad and what impact the implementation of linked data formats could have on the entire data processing process in libraries.
The Topic of Linked Data in Libraries
The use of linked data in library systems is not a new topic in the Czech Republic. Already in 2010, Jindřich Mynarz and Jan Zemánek (Mynarz and Zemánek, 2010) published a paper titled Introduction to Linked Data in the Knihovna plus, where they characterize the principles of linked data formats and their (as they themselves state) technological profile. A large part of the paper is devoted to the use of linked data in the library sector, as an example from the Czech Republic, they mention the conversion of the Polythematic Structured Entry Index to the SKOS format (National Technical Library, 2016–2024).
In the following years, papers in Czech mentioning these topics would follow, by Barbora Drobíková (2013, 2014), Klára Rösslerová (2016, 2017a, 2017b, 2018), and Helena Kučerová (2018, 2019). An important achievement in this area are the projects of the National Library of the Czech Republic related to the interconnection of the TDKIV terminology database and the name authority database with Wikidata, which are described mainly in the works of Linda Jansová (2019, 2020) and Zdeněk Bartl (2019). The possibilities of using linked data in the Knihovny.cz database are described by Michal Denár and Josef Moravec (2023).
For more information about linked data in libraries, you can use the links page on the Information for Libraries portal (National Library of the Czech Republic, 2024). In 2023, the Cataloguing and Linked Data webinar was organised by the Union of Librarians and Information Workers of the Czech Republic (SKIP ČR). Videos from the webinar are available on the SKIP ČR website.
A large number of papers have been published and written on the topic of linked data in libraries abroad in the last twenty years. A systematic review of published resources on the topic of linked data in libraries was presented by a team led by Panorea Gaitanou in the Journal of Information Science (Gaitanou, 2024). The paper summarizes works published between 2008 and 2019. It deals exclusively with articles published in expert periodicals written in English, book chapters, and papers in proceedings. It does not include any theses or dissertations, white papers, or similar sources.
The results of the systematic review are divided into several chapters:
- Linked Data Implementation in the Cultural Heritage Domain, including subchapters: Linked Data Implementation in Libraries and Bibliographic Control, Linked Data Implementation in Specific Projects, Specific Approaches to Linked Data and Methodologies;
- Description of Specific Bibliographic Models, including subchapters: FRBR , BIBFRAME, and RDA models;
- Interoperability Issues: Mapping and Crosswalks, including subchapter Mapping and Crosswalks Using the BIBFRAME model;
- Other Issues, including subchapters: KOS (Knowledge Organization Systems), Linked Data and Metadata Quality, Privacy in Libraries, Librarian’s Position o in the Linked Data Environment, and Educational Material.
The authors processed a total of 239 sources. The above chapter and subchapter titles clearly show which topics were most often covered by the published sources in the period 2008–2019. These are mainly topics related to bibliographic and authority control, the IFLA LRM and BIBFRAME models, interoperability of metadata in library systems with an emphasis on the transition to new linked data formats. The systematic review confirmed the fact, as the authors themselves state, "that linked data are becoming the mainstream trend in library cataloguing especially in the major libraries around the world as well as the most important research projects initiated by libraries in an attempt to make bibliographic data and collections more discoverable in the WWW and their users, more meaningful as well as more reusable " (Gaitanou, 2024, p. 218). However, thanks to such a detailed overview, it is also clear that there are topics that many authors have not yet touched on in their research work from the period 2008–2019. Gaitanou and colleagues state that these are mainly topics related to metadata quality control, lack of rules for handling (meta)data and sharing (meta)data in RDF format, and other topics.
From more recent works, we would like to mention Sophie Zapounidou's dissertation from 2020 entitled Study of Library Data Models in the Semantic Web Environment, in which she compares FRBR, BIBFRAME, RDA and EDM models . Julie Unterstrasser's 2023 thesis is also very inspiring, showing how the transition to the linked data format has affected the work and practice of librarians at the National Library of Sweden. The author emphasizes the significant shift in the work of cataloguers "from cataloguing to catalinking", or from cataloguing to creating links, as a fundamental change in the paradigm of bibliographic and authoritative processing of information resources in libraries. The aspect of the necessary further education of librarians in the field of linked data is also important.
The importance of the topic of linked data is shown not only by the articles published or dissertations, but also by specific ongoing projects to implement linked data formats into bibliographic control processes in many large libraries around the world. Since 2017, the BIBFRAME Workshop in Europe (https://www.bfwe.eu/) has been held annually to bring updates on the state of linked data formats’ implementation from European countries with a large number of current papers by prominent authors in this field. The studies and conference papers by Ian Bigelow with co-authors from the University of Alberta (e.g., 2020, 2022, 2023), Tiziana Possemato with co-authors from the Casalini Libri Library (e.g., 2020, 2022, 2023), which is the organizer of the workshop, or Stanford University’s Nancy Lorimer (e.g., 2022, 2023) or Library of Congress’s Sally McCallum (e.g. 2022, 2023), and many other experts are inspiring.
The number of projects already implemented for the conversion of bibliographic and authority data into linked open data formats is also shown in the Proposal for the Publication of Linked Open Bibliographic Data, a 2023 study by F. A. de Jesus and F. F. de Castro, who identified a total of 58 projects from around the world, projects of national or university and specialized libraries and networks in Spain, Finland, Sweden, Germany, Hungary, and, especially, the United States of America.
The need to switch to linked data is also shown by the 3R Project, which aimed to completely redesign the RDA rules in the Original version to the RDA in the Official version. The RDA Official includes the RDA Registry as its integral part – ontologies for the RDA/RDF linked data format. The aim was also to completely redesign the RDA Toolkit, individual instructions and paragraphs with regard to the use of rules in combination with linked data formats (e.g. Alemu, 2022, p. 197; Oliver, 2021). It is assumed that from 2026 onwards, RDA will only be used as rules in the Official version, and the Original version will be cancelled.
Entity-Oriented Cataloguing: How Bibliographic and Authority Data Management Can Change
As early as 1995, Michael Heaney published an important study dealing with object-oriented cataloguing (Heaney, 1995). The AACR2R cataloguing rules were the context of his study. Heaney called for greater emphasis on the precise identification of the different types of authority that can be interlinked. Networks of linked authorities would then represent individual records. It can be said that such a visionary work can now be completed in a certain way. In the context of linked data formats, new terms emerge, such as identity or entity management or entity-based cataloguing (e.g., Durocher et al., 2020; Stalberg et al., 2020; MacEwan, 2022; Zapounidou et al., 2024).
Linked data technology is based on precise identification of structured data that represents entity instances and the relationships between them using unique URIs (entity instances, relationships, and their corresponding URIs are registered in controlled dictionaries and ontologies). Structured data representing certain types of entities and controlled dictionaries, as Zapounidou et al. (2024) wrote, are the very heart of the cataloguing process known as authority control. At this point, the authority control processes, as we know them from library databases, coincide with linked data management technologies. However, managing linked data requires highly automated processing based on URIs. We often rely on human interpretation and the use of textual chains in authority control processes, e.g., at the level of the selection of authorized input elements according to various cultural and linguistic conventions (see Zapounidou et al., 2024 for more details).
If we discuss entities, then linked data formats, whether we mean, e.g., BIBFRAME or formats based on RDA/RDF and IFLA LRM, will require management of all entities that occur in bibliographic databases. This concerns not only entities that are in the area of interest of authority control today, such as names (personal, corporate), titles of works, geographical names, or subjects. In the language of the IFLA-LRM model (Riva et al., 2017), there are also entities related to expression, manifestation, item, agent, nomen, or time span. For instances of all entities, it is necessary to manage value vocabularies with unique URIs. Document identification (today represented by a bibliographic record) will then be formed as a network of mutual relationships among entity instances (individual occurrences of entities, e.g., a specific person, a specific place), and both relationships and individual entity instances will be represented by URIs (in reference to J. Unterstrasser (2023) above: "from cataloguing to catalinking".)
Advantages of Linked Data Implementation Not Only for Cataloguing
So far, we have only dealt with the implementation of linked data formats in the field of library data management or cataloguing. However, the advantage of deploying linked data formats is best reflected in the interconnection of library databases and external resources in the Web environment, in better visibility of libraries on the Web, and thus in better services to library users. MARC formats are not easy to understand for other systems outside the library community. Linked data formats can enable better interoperability of data across communities – the publishing environment, the GLAM sector – galleries, libraries, archives, museums. Publishing data in linked data formats will make it easier for web search engines to index data from library databases and make the data visible in normal web searches. Such data will enable the interconnection of library databases with external sources of information, such as GeoNames or Wikidata, and enriching the user interfaces of library catalogues and discovery systems from external sources.
The first outputs of data enrichment projects from external sources can also be tested in the Czech Republic, e.g., in the Knihovny.cz portal, as described by Denár and Moravec (2023). The NKlink tool is another example of a good practice (Jonáčková & Dostál, 2020), which enriches authority records with external identifiers, including Wikidata identifiers. The ability to enrich library data with data from external sources is one of the most common arguments for the deployment of linked data formats in libraries and the replacement of obsolete MARC formats. Because the introduction of linked data will help to work with data much more efficiently, it can offer users new search options that are currently only available in complicated ways or are not available at all.
Situation in the Czech Republic
Cooperative Production of Bibliographic Records
The cooperative production of bibliographic records in the Czech Republic is built on several pillars. The main pillar comprises centrally defined standards, such as cataloguing rules (in the Czech Republic, these now include RDA: Resource Description and Access, Original version) and the exchange format (MARC 21 bibliographic and authority format). Other important pillars comprise building of the Czech National Bibliography (including a set of national authorities) and producing union catalogues, to which Czech libraries can contribute new bibliographic records and from which libraries can download records for use in local databases.
The Czech National Bibliography (CNB)
Under the Act No. 257/2001 Sb. (hereinafter referred to as the Library Act), Section 9(2b), the National Library of the Czech Republic "prepares the national bibliography and ensures the coordination of the national bibliographic system". According to the subsequent sections of the same Act, all regional libraries (Section 11(2a)) and specialized libraries (Section 13(2a)) collaborate on this task.
The basis of the CNB consists of libraries within the so-called "cluster": the National Library of the Czech Republic, the Moravian Library in Brno (also in the role of the regional library of the South Moravian Region), and the Olomouc Research Library (also in the role of the regional library of the Olomouc Region). These libraries work within a shared database. In addition, the records of regional libraries are received by the CNB through the Union Catalogue of the Czech Republic. Bibliographic records for fiction are contributed by the Municipal Library in Prague as part of the Central project (Lichtenbergová, 2023). Development of the CNB is one of the so-called national functions of the National Library of the Czech Republic. The CNB database is a very important and irreplaceable source of information on published cultural heritage in the Czech Republic.
The CNB currently makes 1.2 million records available. The contribution to the creation of the bibliography can be illustrated by the statistics of the originators of records generated according to the new RDA rules in force since 2015. Since that year, 209 thousand records have been created according to the RDA, including:
- 64 thousand records by the National Library of the Czech Republic – location code ABA001
- 19 thousand records by the Moravian Library in Brno – location code BOA001
- 18 thousand records by the Olomouc Research Library – location code OLA001
Together, these three libraries have created about a half of the bibliographic records at the CNB since 2015. Other regional and other specialized libraries participated in creating another hundred thousand records, and several records were even originate from a foreign library. The Municipal Library in Prague contributed with almost 13 thousand records16.
Union Databases
The Union Catalogue of the Czech Republic, a centralized heterogeneous union catalogue, contains 8.4 million bibliographic records, including the CNB records. It has been available electronically since 1995 (Svobodová, 2003). Currently, 530 libraries collaborate on its development (Union Catalogue of the Czech Republic, 2023). According to the Act No. 257/2001 Sb., Section 9 (2a)), the Union Catalogue of the Czech Republic is produced by the National Library of the Czech Republic. In addition to the CNB, the building of the Union Catalogue is also part of the so-called national functions of the National Library of the Czech Republic.
Only monograph records can be contributed to the Union Catalogue via the OAI-PMH protocol. For serial resources, it is possible to update subscriptions of individual titles using an online form. The frequency of contributions varies. When data is entered into the Union Catalogue, multiplicity and quality of records are checked. In the event that an entry already exists in the Union Catalogue of the Czech Republic (hereinafter referred to as the SKC), only the location code of the new (sending) library is registered and a link is created to its local catalogue. For a new record, the entire record is inserted into the SKC, including the link to a local base. Where a record does not have the desired quality, it is returned to the sending library for correction. Some libraries do not provide their entire collections for harvesting in the SKC database, but only a certain selected part, e.g., by document type.
We should mention the Knihovny.cz portal as another representative example of union databases, which now includes 100 libraries. In addition, the portal provides access to other resources that it harvests, including the Union Catalogue of the Czech Republic (Knihovny.cz, 2024b). Using the Z39.50 protocol, libraries can have their individual profiles defined, which allow them to search and download records from various Czech and foreign sources (Knihovny.cz, 2024a). The advantage of the Knihovny.cz database is that it often receives records of a larger part of the collections from libraries. It is therefore a relatively interesting source of, for example, audiobook recordings or special documents such as talking books or board games.
Given the role of the Knihovny.cz portal, the titles here do not have a truly collective record (SKC). For the purposes of searching, the system works with each record that it has received from all libraries that hold the title. The records are interconnected using duplicate control (Kurfürstová et al., 2023). A different record is used at different times, for example, based on a home library of a logged-in user, or the selection of a library when searching. All records in the Knihovny.cz index are then offered through Z39.50. Their quality varies considerably. At the same time, however, the portal often provides records that are not available in other sources.
Current Collaboration Workflow
In addition to the indisputable advantages that result from the development of the CNB and union databases for cooperative cataloguing, it is also possible to observe certain weaknesses that have accompanied the existing models of cooperation throughout the existence of library databases, and not only in the electronic environment. We could summarize them using two concepts of multiplicity and asynchronicity. This is reflected in practice, for example, in the following situation: a library requests a complete record of a title that has just been delivered, for example in the Union Catalogue of the Czech Republic. If the library does not find it there, then it will have to create such a record. This can happen in the span of hours or days in a number of libraries. If a library cooperates with the SKC, the record created by it will be harvested via the OAI-PMH protocol, sometimes with a weekly (or even monthly) periodicity. In the SKC, multiplicate records of various quality are created, which must be deduplicated in a complex way. Moreover, it is not easy to apply partial changes to deduplicated records based on records sent from libraries. At a certain point, the system only registers that the title exists in the given library.
Thus, part of the work generated by this parallel activity is not relevant to the cooperative system. In individual libraries, records of varying processing complexity and quality are created in such manner. This does not mean that the system is poorly designed. All negative properties are based on the multi-speed dynamics of the distribution of records in the system. This is partly due to the fact that harvesting records from hundreds of libraries is time-consuming, as is the subsequent deduplication and further processing on the part of the union databases. The MARC format also plays a role, as its structure often does not allow for effective qualitative evaluation of individual records with regard to the creation of a high-quality union record. Algorithm-based evaluation weighs are used, but these tend to work with formal record checks. This is also due to the fact that the amount of information in the MARC structure is recorded only as text, without placing it in a broader context or assigning a specific meaning to the information. The whole process is made even more complex by the complicated syntax and rules for creating records, which in some respects allow different approaches to description or notation.
As mentioned above, the CNB is produced mainly by the three major libraries in the cluster. These libraries obtain published documents in the Czech Republic mainly in the form of legal deposits. This in itself often brings significant delays in the processing of documents that have been available on the market for some time. In reality, regional or specialized libraries are able to obtain these documents earlier than the "cluster" libraries, and are forced to be the first to process the documents. Given the requirements of their users, they often cannot wait for a high-quality record to be created at the CNB or for the record to be downloaded into the union databases. Although the CNB forms the basis for the SKC, especially in the area of Czech production, it may happen that the records in the CNB differ from the records of the same titles. They contain some practical information that will be appreciated by both lending service workers and readers. An example can be an indication of pertinence to a cycle or high-quality annotation.
The biggest problem of the current cooperative system is the considerable number of duplicates and multiplicity of records. These are created by the fact that records from local databases are received in central union databases at different times. This is mainly due to the acquisition policy of individual libraries in connection with distribution. In addition, libraries send their records to union databases at various frequencies. As regards fiction, the Central project managed by the Municipal Library in Prague (Projekt Central, 2024b), has significantly helped with the speed of cataloguing new titles. The project purchases fiction 3 times a week and process around 16 titles a day. They state that they send new publication records to the Union Catalogue 3 to 7 days of publication. However, asynchronicity occurs here as well. According to statistics, the project will cover approximately 80% of fiction published in our territory by the largest Czech publishing houses (Projekt Central, 2024a).
Design/Outline of a Vision for Future Solutions
In the cooperation model, where the recording is created only after the document is published and placed on the market, these weaknesses cannot be avoided. This situation could be addressed in many cases by creating a record before the document is issued or, at the latest, in parallel with its launch.
An important player could be the newly built joint database of libraries and publishers called the Register of Czech Books, sometimes also called ReČeK for short (Maixnerová, 2023). Thanks to it, libraries could obtain basic metadata before the title is released. The project could offer a usable data alternative to "cataloguing in a book", which has only partially spread in our environment, rather in professional literature. Thanks to the direct recording of values by the publisher, the record could be more complete than the CIP and ISN (reported books) databases currently provide. In addition, metadata will be available for download before the publication of the book in the library network (e.g. for acquisition purposes), starting with the creation of a record and in one place. The persistent entity identifier will remain the same and public, but the metadata will be further added during the cataloguing process. Until the title is actually published, the data can be edited to react, for example, to changes in the title or the number of pages.
If each such title also received a unique identifier (before the ISBN and the CNB), it would be possible to create records referring to this identifier. If a central metadata repository is also created in the National Library, it would be technically feasible to distribute all changes in records to the entire ecosystem. This would create a single record that would be distributed by the system to local databases. This solution could prevent the creation of different versions of records between the central database and the local record in the connected library. At the same time, the central record could be complemented and improved in a cooperative way. Any change would soon be reflected in all local copies. In addition, it would be possible to insert certain data only for local use, or, conversely, to hide some information for use in a specific library.
National Authority Files
Today, we can no longer imagine high-quality bibliographic records without access point based on authority files. Authority files are an important building block of bibliographic databases, allowing to uniquely identify specific instances of entities, link bibliographic records, and playing a significant role in searching databases and metadata. At present, library databases mainly use authority records for persons (personal names), corporations, subject terms/descriptors, formal descriptors, geographical names, titles of works and expressions (in the form of authority records for anonymous works, or in the authority records of the name-title type for works listed under the author's name). However, the representation of the authoritative forms of the above-mentioned types of entities is far from being one hundred percent in bibliographic records.
As an example, the CNB database contains 866 thousand records with the field 100 (Main entry – personal name). There are 797 thousand occurrences of the subfield 7 that contains an authority record’s identifier. Of the 731 thousand occurrences of the 700 field (Added entry – personal name), the subfield 7 with an authority record identifier has 628 thousand occurrences.
The CNB database can be considered a very well-managed database with the best quality of cataloguing possible. Personal names are the most common and most commonly produced authority records in general. Nevertheless, even in the CNB’s fields 100 or 700 for personal names, not all forms of names are based on authority files. Such a situation is quite logical, because the CNB contains different layers of records from different periods.
Table 1 Proportion of identifiers completed for CNB personal and corporate authority records
In addition to the data that can currently be linked to authority records, there is also data in bibliographic records for which it would be appropriate to create authority records or controlled vocabularies for the sake of unambiguity of search and linking, but this is not done as a result of the cataloguing traditions. These concerns mainly data on publishers (the issue was addressed, for example, by Drobíková et al., 2016), places of publication or production of documents. We can also include the issues of recording time/date or time span (the time span occurs in many fields of bibliographic and authority records – e.g., date of publication, field 264, 008; date of record creation, field 008/00-06, date of record update, 005, dates related to the document’s content given in the subject fields – 648, 045, for authority records, these concerns data associated with individuals, corporations, with the time-limited existence of administrative units, or with the creation or updating of a work, or its expression, the creation of a recording, etc.).
Collaboration on Authority Records
In the case of authority records, cooperative creation in the Czech Republic is used mainly for authority records of personal, corporate and geographical names. The cooperative creation of other types of authority records (subject terms, title authority records) is limited to the cooperation among the relevant departments of the National Library of the Czech Republic and cluster libraries due to the more demanding administration, complexity of the structure, and dependence on the terminological systems of individual subject areas. In practice, therefore, we often encounter situations, in which libraries use non-authoritative forms of names and titles in the relevant fields (title, subject). The possibility of linking such records may be significantly limited for these reasons.
Like in the case of collaborative production of bibliographic records, there is a delay and a certain asynchronicity in the creation of authoritative records, too. Authority records for authors are usually created only after the publication of a document, generally a printed one, especially a book. To a lesser extent, article production is taken into account, and authors of articles in Czech periodicals or periodicals published in our territory are taken into account. The scientific community publishing articles abroad or the authority files for their research workplaces often do not even fall within the scope of Czech national authority files. A similar situation is common for other types of documents, such as electronic textbooks or educational videos.
Authors (and other originators) of works that are published only electronically now also remain unprocessed. Where an electronic legal deposit is received, there will be a need to create authority records even for authors who have not yet been processed. This may mean an additional burden for the National Library of the Czech Republic. In the future, the solution is to decentralize the production of authority files as much as possible among a larger number of cooperating entities that will form a single metadata base together. This system should be designed in such a manner as to allow for different levels of rights for registration and suggesting modifications. The solution must be set up so that despite the participation of a broader community, duplicate records are still minimized . The complete elimination of duplicates is unlikely to be avoided in the future, but efforts will continue to minimize their occurrence, both at the process level and through the use of technical tools and procedures.
Independently of authority record production, a unique identification of authors is being expanded using other types of identifiers around the world and in the Czech Republic, e.g., ORCID identifiers (Open Researcher and Contributor ID) for publishing in the field of science and research or the ISNI identifier (International Standard Name Identifier) . Experts from universities and research institutions may apply for the ORCID identifier before a publishing activity takes place. The identifier assigned then accompanies them in the publication of various sources (e.g., studies, textbooks, articles in electronic form), whether in the Czech Republic or abroad.
Linked Data as a Means for More Efficient Library Collaboration As we mentioned earlier, the MARC format now affects the entire process of producing and distributing metadata. Using a timeline of the process of creating one particular record in the Union Catalogue of the Czech Republic (SKC), we can demonstrate how the current model works.
We chose the work Šikmý kostel (The Leaning Church), Part Three, by Karin Lednická, as a sample record. The title was published on 15/04/2024 and its record appeared in the SKC on the next day, on 16/04/2024. Unfortunately, it contained an incorrect CNB number (field 015). Since it was a planned and anticipated title, the interest in the record from libraries was considerable. The record began to spread across libraries via the Z39.50 protocol, including the error. There is no way to count the number of downloads. Only some of the libraries that used the record are involved in the cooperative cataloguing for the SKC. This means we can only monitor the number of imports from individual libraries. Individual imports can be related to specific days and times, but these are often not the same as the date of entry into local databases.
As we mentioned above, imports to the SKC usually take place in weekly cycles, but in practice we encounter both shorter and significantly longer intervals. The error was corrected on 24/04/2024 by an SKC employee. Automatic editing of records in local databases after a change in SKC is an issue, and thus records are usually updated manually, or not updated at all. Some errors may remain in the library databases. In a sample of records, we found some records not containing any CNB numbers at all. This may be a problem in the future, as it is a key identifier that can play an important role in future migration to linked data formats, as well as help in further work with metadata. Without the identifier, unique identification is difficult to imagine .
Fig. 1 Šikmý kostel (The Leaning Church), Part Three (2024): a timeline of record changes
The transition to linked data should also include a set of strategic decisions that will help us tackle most of the problems brought about by the existing system of cooperation during the change. We should focus on two key aspects that we have identified, i. e., time asynchronicity between the need for a record and its delivery to the central repository, and the absence of a unique title identifier that is available before release. Another key feature of the new solution is an ability to distribute all changes from the repository to the participating institutions very quickly, almost in real time.
The Register of Czech Books (ReČeK) should be given an essential position in the planned system. This database should be co-created as a joint work of publishers, libraries, and the Czech National Agency for ISBN and ISMN. It will contain information about books from the moment they are included in the publishers' editorial plans. Publishers require an ability of ReČeK to provide structured information on titles in the ONIX format , which they set as a pre-condition for their cooperation. The ONIX format is successfully used internationally for the needs of publishers, distributors, and booksellers. ReČeK should then enrich information from publishers with contextual information that is important for use in libraries (linking authors to personal authority records, subject authority entries mapped to publisher's subject description, publishers' databases, etc.). The plan is that an ISBN will be assigned immediately when a record is imported to ReČeK. The system must then be able to provide the "library version" of the metadata to libraries, at least for a transitional period, in the MARC format, and, at the same time, in a structure suitable for linked data creation.
When creating a record in the ReČeK database, a record should ideally be created at the same time in the central metadata repository (with feedback to the ReČeK system). The linked data structure will allow for a better description of the interrelationships among entities. It will be necessary to rethink the ways in which certain kinds of records are created.
According to the instructions currently in place, it is possible to create either a collective record for all volumes (top-down), or records of individual parts (bottom-up) for multi-volume monographs. The instructions define some cases for choosing either of the options. Unfortunately, due to varying interpretations of the instructions, it happens that different libraries create records for the same titles using both top-down and bottom-up approaches. It is not always easy to distinguish such records from each other at first glance. Their structure can be very similar. Especially, when searching via Z39.50, it is not clearly stated anywhere in the interface whether a record concerns a single title or a series of titles. It is possible to distinguish such cases only with the help of some (basically partial) aspects of the record – for example, the year of publication can be written as a range for a series, the physical description will contain the number of volumes instead of the number of pages, and so on, for group records the code "a" should be given at position 19 in the LDR . Sometimes it happens that a collective record with the CNB number is downloaded to a local database, which is then modified using the bottom-up approach and the CNB is not removed, which then causes complications in the identification of the document.
In the linked data structure, we have significantly more options for connecting individual entities into logical units, including hierarchical links. We can easily distinguish such entities by having different classes. Links can change dynamically over time. For a better understanding, we give a specific example, again using the title Šikmý kostel (The Leaning Church).
In the CNB database, there is a so-called collective record for the Šikmý kostel (The Leaning Church) series, and the record has been assigned its own CNB identifier. The record also contains the ISBNs of the individual parts. At the same time, there may be separate records for the individual volumes in the Union Catalogue of the Czech Republic and in local library catalogues. In a description using linked data, we can link the records of individual parts to each other.
Similarly, for example, in the case of personal authority records, different identities of persons can be combined. Again, there is no need to create an umbrella record that contains various reference forms of names, pseudonyms or language variants of names. Everything can be defined by mutual relationships of entities. However, a collective entity may also exist, depending on the ontology used/designed.
When designing formats and links, we should not remain limited by the established approaches to description, which have been influenced by the UNIMARC format over the decades, later by MARC 21 and the cataloguing rules used. Rather than that, we should start from more general principles in order to create structures that allow us to describe reality in a straightforward manner. Linked data records can gradually grow and gain in complexity. In the beginning, there may be a simple vertical structure, which may form complex tree structures as the number of volumes increases. However, linked data, unlike the MARC format, will allow us to look at these structures from many angles and directions, depending on what interests us. Metadata can be produced in a decentralized way, but the results will be available in one place.
Decentralization of metadata production will allow the involvement of different players, and specialization in a certain area will then play an important role. Part of the work will be done automatically by bots specialized in specific tasks. For example, bots in the Wikidata project add identifiers to existing items from external sources, or add links to each other.
Prerequisites for Transition to Linked Data
The RDF data model, as the cornerstone for linked data technologz, distinguishes (in addition to an empty node) two basic types of nodes that can occur in data triplets at an item’s location – URI (or IRI) and the so-called literals. Our goal should be to make the most of URIs referencing an item. This leads us to obtain as much information as possible from authority files, ontologies, thesauri, and controlled vocabularies. Therefore, we need to have these building blocks ready before we start producing records as linked data. The first decision is the selection of suitable sources that will be the basis of future metadata.
Authority files are one of the important sources. We cannot do anything without name and subject authority records, converted into linked data formats. We should also map suitable sources at the national level, but we must not forget about sources from other countries. For example, we do not have an up-to-date controlled vocabulary with data on publishers at the moment. This could be provided by the ReČeK in the future. The next step will be to prepare the suitable sources for use in practice. This will involve conversions to the necessary formats and structures. The resulting ontology map should be constantly maintained by a curatorial team, which should search for new sources and oversee the relevance of existing sources.
Work in other types of record editors is also a prerequisite . The creation of linked metadata will be significantly different than in the current cataloguing editors that we commonly use for MARC (a cataloguer will perform "linking" rather than "cataloguing"). Some fields will be linked to large value lists, and an editor will have to work well as a guide. Loading values should not slow down the work significantly.
Table - SWOT analysis
Where are We Heading?
The transition to linked data is not merely replacing one metadata type with another. Linked data brings a very different approach to recording reality using metadata. If we embrace this change, then new possibilities will open up for libraries, especially in the area of cooperative metadata production. This should not make us complacent; we must also strive to ensure that the newly designed system provides tools that will allow us to better manage the quality of metadata and make the process of its production more transparent.
Abandoning the MARC format, which is understandable only to libraries, provides us with a unique opportunity to open up data even more for further use outside of our ecosystem. It is not enough to just expose packages of data under a suitable open licence. We also need to offer the right tools to work efficiently with millions of records. Such tools include APIs (Application Programming Interfaces), which are a necessary basis for ensuring integration to information systems or applications. For analytical purposes, we should offer a certain form of a query service, which allows us to obtain various types of structured information in the form of queries. Last but not least, we must offer a user-friendly search interface to professionals and the general public.
The transition from the MARC format will be gradual. We have to take into account that for the transitional period of time we will create metadata both in the MARC format and in the linked data structure. If we are to work efficiently, we cannot create all the data in both ways. Probably the best way is to create linked data that contain specific MARC fields. From such hybrid records, it is possible to generate records of a sufficient quality level in the MARC format without redundant duplicated work. This is the path that some libraries are currently taking in other countries. In the design of the future system, that part working with the MARC format should exist as a temporary module that can be safely switched off when it is no longer needed.
When designing the system, we should always be aware of the limitations that exist in the current solution. These include:
- occurrence of multiplicate records in the metadata ecosystem,
- different approaches to describing different types of documents,
- central repository built on proprietary technology that does not allow access from different systems,
- very limited possibilities of distributing changes in records to local databases,
- limited possibilities of logging activities in the repository,
- inability to perform more complex queries on datasets,
- in the event of a failure of the central repository or a distribution service, the necessary data is not available,
- inability to export from the repository in a format other than MARC,
- limited capabilities to perform more complex analytical or statistical queries on the data in the repository.
The figure below shows a schematic design of the system’s individual modules for shared creation and distribution of metadata. So far, it is a more general concept that is based on two requirements: the system will use linked data and functionalities and will try to address the existing limitations and problems of cooperative metadata production, especially on the blueprint of the Union Catalogue of the Czech Republic and its existing services.
The metadata repository is at the heart of the solution. The repository is intended to be centralized, with decentralized distribution of metadata to local databases in the participating libraries. The repository should be independent of the library system that will be used by the National Library of the Czech Republic in the future or that will be used for the administration of the Union Catalogue of the Czech Republic. It should also be possible for library systems and other systems to cooperate with the repository. Records in local databases will be exact copies of a central record, including identifiers. Thanks to the fact that the identifiers are of the URI type and always fall into a specific namespace, the data is compliant – unlike records in the MARC 21 format, where the identifiers are usually valid only locally and the link to the original record may be lost. Any change in the central record will be readily synchronized with local databases.
A local database will also serve as a redundant backup, from which it is possible to restore records in the central repository. Each local repository has the option to attach locally used information to the record, which will not be synchronized with the central record (it will exist in a different namespace). The local system and search interface will make it possible to hide part of the information from the central record that is not used in a particular library, or, on the contrary, to display additional information from external sources according to current needs, or to attach information important only for a specific local library to the local record and it is not distributed to the central repository.
All the building blocks needed to create records will be stored in the repository, including not only instances of entities that we use to identify authors or for subject description, but also values from various lists or vocabularies. These will be obtained by converting existing authority files, but it will also be possible to obtain them from various external sources. However, such sources will first have to be selected, and have their quality and long-term sustainability evaluated.
Robust tools must be available to efficiently manage the data stored in the repository. Since the solution will significantly reduce duplication, it will be possible to focus more on quality. To that end, repository administrators will need tools that allow them to proactively scan for possible errors and fix them quickly. At this level, we should also count on the deployment of automated tasks based on machine learning. Each such task should be trained on the data available in the repository and its functionality verified by experts. Such tasks can help troubleshoot errors in metadata acquisition. They can also enrich or link individual entities to each other.
By linking individual entities as building blocks, successors to today's records will be created to identify documents, their contents, people, but also the actual libraries. Such a solution must be ready to provide both linked data and data in the MARC format for a transitional period, but without the need to create entire records twice. This can be achieved, for example, by temporarily including a portion of specific MARC fields in the linked data format records. This involves some fields that would be complicated to generate from linked data in the required syntax. This is currently quite common in libraries in other countries. In this manner, it is possible to create records in the linked data format and, at the same time, enable the distribution of metadata in the MARC format. Traditional protocols such as OAI–PMH and Z39.50 will continue to be available for distribution. When the moment comes that MARC records are no longer needed, it will be possible to turn off the entire module that handled the MARC distribution.
The solution envisages a close liaison with the planned ReČeK database, which is to be developed with the direct participation of publishers. It is supposed to make it possible for publishers to enter information about titles planned for release. Post-publication data will be available in the ONIX format for book distribution. At the same time, the data will also be used by the ISBN Agency, which will assign ISBNs to individual titles based accordingly. Libraries will also utilize the data. They will have information about upcoming titles, e.g., presale lists, which can significantly benefit the cooperative metadata creation system. Each newly entered title in ReČeK should automatically receive a unique title identifier, through which it will be possible to identify the title throughout the process before and after release. It will be possible to enter a record in the central repository having a relatively high level of quality as soon as the title is officially released. Where a library links it to its local database and later expands or modifies it, the system will overwrite such changes for all libraries where such a record occurs. No changes will take place in a local system.
This should be possible thanks to an editor that will write directly to a central repository. When you try to create a new record, it is first verified that the record for the requested document does not already exist in the repository. If it exists, the creator can extend it or keep it. If the record is not available, the creator will be given the option to create it. Technically, this process must be set up to carefully manage access to the repository and actively prevent duplicate records. A rights system should also be part of the access control for writing. Some users may have higher rights (writing specific "fields", deleting, overwriting values, etc.), others will have limited rights. Rights may be granted by the administrator on the basis of meeting formal conditions, but also on the basis of measuring the quality of record processing.
Users who will create quality records can then obtain higher rights thanks to a good reputation. On the other hand, erring users can lose their rights. The system should also offer the possibility of obtaining and providing feedback. Users should be able to flag errors or inaccuracies. Admin intervention, such as when fixing a bug, could trigger a notification to notify the user that they made a mistake and how it was fixed.
There should also be an API that allows you to pass data from systems other than library ones. It should be possible to add not only various identifiers to existing records or create entire records, but also to add additional information. The API should then ensure that the data is properly mapped between the external system and the repository. The output of the system should be several tools with both public and non-public access regimes. An example of public disclosure would be a search interface that allows anyone to search the records in the repository. We can imagine it as a search in the current Union Catalogue of the Czech Republic or in the database of authorities. API and query services will also be publicly available. Through them, it should be possible to obtain data according to the specific needs of users.
It should be possible to limit the use of public service functionalities in terms of licenses and functionality. In parallel, there will be tools for partners. Their use will also be contractually regulated and their use will be regulated by a contract and the services provided will be tailored to the needs of partners. We can imagine other memory institutions, companies, offices or libraries as partners.
As is already the case, it should be possible to download entire data packages in various formats under the appropriate license and with the appropriate documentation. It should be possible to modify and extend the functionalities of individual modules of the intended solution, as the needs of users grow.
The query service module should be created to allow users to create more complex queries on top of the entire repository. A search can provide significantly more comprehensive search results than a standard search above an index. Such services can be used for various specific types of search, such as domain analysis, science mapping, or book production, based on different aspects.
An important part of the system should be an analytical module. It should provide administrators as well as users with real-time information about the repository. Each user should have data that will make them perceive the repository as a living but transparent organism. First of all, administrators need to know a lot of information about what is happening in the repository, how users behave, and also about how the whole system works.
Since the solution should provide services at the national level, it will be a key system. Its development should be managed by a team at the National Library of the Czech Republic, where all knowledge about its functioning must be concentrated in order to ensure the long-term sustainability of the system, guarantee its maximum functionality and reliability. For economic reasons, the individual modules, or their parts, will be assembled from existing solutions. The actual development would cover the interconnection of individual parts into a functional unit and possibly some partial components. For reasons of sustainability and flexibility, the solution should avoid the use of proprietary products. All development should be made available to the public under an appropriate open license.
Using open development methods will allow more developers to be involved in the process and work to be decentralized. Developers can also change over time without such a change jeopardizing further development. The leadership of the development and its direction must be in the hands of the National Library of the Czech Republic. It can also invite other participating libraries. Such cooperation could be beneficial not only in strategic decisions, but feedback from the libraries involved should contribute to a better-functioning solution as a whole.
Fig. 2 Diagram of the joint cooperative metadata creation system
Discussion
The transition to linked data in libraries is the biggest change in the last three decades. However, it is not just a matter of changing the metadata format. The change means a comprehensive transformation of the entire ecosystem of metadata creation and use. The basic building blocks for linked data have their origins in philosophy and logic. The structure of linked data depends on the ontologies used. Its goal is to describe the real world (SOWA, 1995). This provides a robust foundation for the entire ecosystem of linked data and is a crucial shift away from the single-purpose MARC 21 format.
The ability of individual entities to connect with each other erases the hitherto noticeable boundaries between record types. In fact, the bibliographic record as we know it today will cease to exist. The level of detail displayed by users can vary depending on the requirements of a particular application and the needs of the user. Because we describe real-world entities in linked data, it does not matter whether we describe a book, a person or, for example, an institution (a library). Systems can be created over the linked data that are able to offer searches not only for titles and their authors, but can also link information about libraries, in which the entities searched are available. It is possible to ask a question such as: Find the book "1984" by the author "George Orwell" located in wheelchair-accessible libraries that are open on Saturdays. If we also pay intensive attention to machine processing of full texts in content classification, we can offer search tools that will allow detailed mapping of literature with regard to time, form, places, or topics. The biggest change compared to using MARC is not in how much information describes an object in a record, but how this information is written and how it can be used further. The MARC structure as such makes it possible to make good use of the individual information written in it, but it is not possible to link this information to one another. And if it is possible, such links are often stored in local systems and do not spread throughout the ecosystem. In each of local systems, such links must then be re-established.
In order to be well prepared for the transition to the linked data ecosystem, it is important to open a discussion about the issues of how to describe and identify entities (entity instances) and whether we could optimize some aspects in this area today, even though we are still working with the original formats in the established cataloguing practice. The topics we encountered in our analyses for the purposes of this study relate mainly to the following areas:
The list is far from exhaustive. However, the problems identified in these areas are quite significant and already complicate the communication of records both within the library network and the communication of data between libraries and surrounding systems.
Conclusion
The path to linked data will be challenging. It will require a change in the approach and the way of thinking that has influenced librarians and library systems for several generations. In other countries, this issue has been dealt with for several years. On the other hand, there is a certain delay in our settings. However, the advantage may be the opportunity to use the existing knowledge and learn from mistakes that are logically avoided by pioneers.
Valuable information is available from colleagues in other countries on how to go through the whole process in terms of personnel management in libraries. It will be necessary to explain at all levels why we need the change, what it will bring, and what it will require from each of those involved. A crucial step will be to start an early supporting process of retraining the personnel who create metadata. For example, the experience from Sweden speaks of a key role of lifelong learning as a fundamental pillar for a successful transition to linked data.
It is very important that the topics of linked data become gradually embraced by expert discourse in libraries so that the library community gains a broader awareness of the issue and can prepare well for this change. We believe that the present paper has contributed by suggesting a procedure for cooperative metadata creation, which solves most of the weaknesses that the existing shared cataloguing system suffers from, with the help of linked data. This proposal is based on a careful examination of limitations and shortcomings. We are aware that the proposal is still general and cannot give answers to all questions. It was created to open a discussion and to make it possible to further focus on individual parts of the system, as well as to gradually refine its future form. Nevertheless, we think that change is feasible in our environment.
Bibliography
ALEMU, Getaneh, 2022. The future of enriched, linked, open and filtered metadata: making sense of IFLA LRM, RDA, linked data and BIBFRAME. London: Facet Publishing, 2022. ISBN 9781783304943.
BARTL, Zdeněk, 2019. Soubory národních jmenných autorit a propojená data (linked data). In: Knihovny současnosti 2019. Online. Praha: Sdružení knihoven České republiky; V Brně: Moravská zemská knihovna, 2019, s. 66–70. ISBN 978-80-86249-89-6, 978-80-7051-278-4. Available at https://sdruk.cz/wp-content/uploads/2020/04/Sbornik_KKS19.pdf. [accessed on 2024-05-25],
BERNERS-LEE, Tim, 2006. Linked Data. Online. W3, 2006-07-27, last change 2009/06/18 18:24:33. Available at https://www.w3.org/DesignIssues/LinkedData.html. [accessed on 2024-06-28].
BIGELOW, Ian and Pretty HEATHER, 2020. BIBFRAME Readiness: A Canadian Perspective. In: BIBFRAME in Europe Workshop. Online. September 22, 2020, Available at https://www.bfwe.eu/virtual_2020. [accessed on 2024-06-28].
BIGELOW, Ian and SPARLING. Abigail, 2022. BIBFRAME Implementation at UAL: Planning for Success. Online. In: BIBFRAME Workshop in Europe. Online. September 20th, 2022, Available at https://www.bfwe.eu/budapest_2022. [accessed on 2024-06-28].
BIGELOW, Ian and SPARLING, Abigail, 2023.UAL LSP Migration Planning: BIBFRAME Needs and Requirements. In: BIBFRAME Workshop in Europe. Online. Brussels, September 20th 2023. Available at https://www.bfwe.eu/brussels_2023. [accessed on 2024-06-28].
ČESKO. Zákon č. 257/2001 Sb. Zákon o knihovnách a podmínkách provozování veřejných knihovnických a informačních služeb (knihovní zákon). Online. Available at https://www.zakonyprolidi.cz/cs/2001-257. [accessed on 01.02.2024].
DENÁR, Michal a MORAVEC, Josef, 2023. Využití propojených dat v portálu Knihovny.cz. IT lib. Online. 2023, č. Speciál 2, s. 26–46. ISSN 1335-793X. Available at https://itlib.cvtisr.sk/clanky/vyuziti-propojenych-dat-v-portalu-knihovny-cz/. [accessed on 2024-06-28].
DROBÍKOVÁ, Barbora, 2013. Standardy pro knihovní katalogy v sémantickém webu. Knihovna: knihovnická revue. Online. Roč. 24, č. 2, s. 72–83. ISSN 1801-3252. Dostupný z: http://knihovna.nkp.cz/knihovna132/13272.htm. [accessed on 2024-05-25].
DROBÍKOVÁ, Barbora. 2014. RDA a BIBFRAME: budoucí standardy bibliografické kontroly?, 2014. In: Knihovny současnosti 2014. Online. Ostrava: Sdružení knihoven.S. 109–118. Available at https://ipk.nkp.cz/docs/knihovny-soucasnosti/knihovny-soucasnosti-2014. [accessed on 2024-05-26].
DROBÍKOVÁ, B.; ODEHNALOVÁ, M.; JURANOVÁ, E.; KRÁLOVÁ, K. a SVATOŠ, L., 2016. FRBR and the publication statement: the problem of identification of relationships and attributes of the entity Manifestation. ProInflow. Online. Roč. 8, č. 1.Available at https://doi.org/10.5817/ProIn2016-1-2. [accessed on 2024-05-25].
DUROCHER, Michelle et al. 2020. The PCC ISNI Pilot: Exploring Identity Management on a Global, Collaborative Scale. Cataloging & Classification Quarterly. Roč. 58, č. 3–4. DOI: 10.1080/01639374.2020.1713952.
EDItEUR, 2024. Mapping from BISAC 2023 to Thema v.1.5. Online. EDItEUR, akt. 2024-03-21. Available at https://www.editeur.org/151/Thema/. [accessed on 2024-06-11].
EUROPEANA Foundation. Europeana Data Model (EDM). Online. Den Haag: Europeana Foundation. Available at https://pro.europeana.eu/page/edm-documentation. [accessed on 2024-06-28].
FORTIER, A.; PRETTY, H. J. & SCOTT, D. B., 2022. Assessing the Readiness for and Knowledge of BIBFRAME in Canadian Libraries. Cataloging & Classification Quarterly. Online. Roč. 60, č. 8, s, 708–735, Available at https://doi.org/10.1080/01639374.2022.2119456 .[accessed on 2024-05-25].
GAITANAU, P., ANDREOU, I., SICILIA, M.-A., & GAROUFALLOU, E. 2024. Linked data for libraries: Creating a global knowledge space, a systematic literature review. Journal of Information Science. Online. 2024, roč. 50, č.1, s. 204–244. Available at https://doi.org/10.1177/01655515221084645. [accessed on 2024-05-25].
HEANEY, Michael, 1995. Object-Oriented Cataloging. Information technology and libraries. Roč. 14, č. 3, s. 135–153. ISSN 0730-9295.
Identifikátory.cz: stránky o perzistentních identifikátorech, 202. Online. Národní technická knihovna. Available at https://identifikatory.cz/cs/. [accessed on 2024-06-13].
IFLA Study Group on the Functional Requirements for Bibliographic Records, 2021. Funkční požadavky na bibliografické záznamy. Online. Překlad Ludmila Celbová. Praha: Národní knihovna ČR, 2001. Available at https://www.ifla.org/wp-content/uploads/2019/05/assets/cataloguing/frbr/frbr-cs.pdf. [accessed on 2024-06-11].
]]>Keywords: non‑invasive survey safety, video spectral comparator, multispectral analysis, radiography, paper, leather
]]>Keywords: digital humanities, OCR, READ‑COOP, artificial intelligence, Transkribus platform, HTR+, SKRIPTOR project, Andrej Kmeť, schwabacher, fraktur, antiqua, read & search
Introduction
The most significant progress in research, development and applications in digitisation in the social sciences and humanities, i.e. in digital humanities has occurred mainly in the last ten years. The subject of professional interest is automatic optical character recognition (OCR) OCR of ordinary printed documents has long been sufficiently managed with the help of high-quality OCR tools. In the recent years alone, dozens of researchers and experimenters have been working on the more demanding issue of OCR of historical manuscripts and prints using artificial intelligence. Progress was made with the implementation of the READ project, , which, as a scientific basic research project, was directly subordinate to the European Commission and was evaluated annually by independent reviewers . Other platforms, applications, and transcription tools are also being developed. The main outcome of the READ project is the usable Transkribus platform and tool, which is a global innovation focused on transcription of historical manuscripts and documents. So far, Slovakia has been the only Central and Eastern European country that seeks to elaborate on the initiatives of the European READ fundamental research in the SKRIPTOR applied research project.
Digital humanities and project READ
We consider digital humanities as the common name and summarising methodology for all applications of information and communication technology in social sciences and humanities, in the related fields and disciplines and the corresponding practice. Such methodology was comprehensively applied in the READ Project, which was implemented under the Horizon 2020 program . The READ Project was supported by the European Union with a sum of EUR 8,2 million. The financing period ended on June 30th, 2019. Since 2016, the University of Innsbruck has conducted research into the basic technologies of text segmentation, recognition of handwritten text, key word search for historical documents, and instruments for publication of results. Teams of universities in Valencia, Rostock and the Vienna Technical University and other research institutions participated in all areas of research. Cooperation with other partners from Europe and the world has been developed. The research and development activities continue. Thousands of users of the Transkribus platform create new models of transcription based on historical manuscript and printed collections of national institutions, especially libraries and archives. Collaboration with the community of researchers around the Transkribus platform can be useful for Slovak and Czech expert community in digital humanities.
The common vision of scientists, experts and other users is for publicly available transcription models to gradually become a useful shared tool for automatic transcription of historical documents. It is necessary to attain such a level that it is no longer necessary to create separate models for each collection of manuscripts and printed materials. For users, it should be a kind of a "black box", in which artificial intelligence selects the most suitable model from integrated models for transcription of historical prints, manuscripts, typescripts and other documents that the user wants to study or make available. However, there is a long way to go to this goal and a need to create many partial models.
It is important that Slovak and Czech experts be part of the joint international effort and that the future "black box" be ready to provide assistance to all in transcription of historical collections and documents. At this stage of development, it is important to focus on preparing partial transcription models for historical manuscripts printed materials based on larger collections that contain hundreds and thousands of pages. . We recommend focusing on documents in Western Slavic languages, Czech, Slovak, Upper Sorbian and Lower Sorbian, and Polish. The nature of the collections also requires that attention be paid to Latin, German and Hungarian. We ought to create one integrated model for handwritten documents and one for old and rare prints based on our own models. This is a task that no one else will do for us.
Current State of Research and Applications
The existing information resources on OCR, on the one hand, relate to ongoing theoretical research on artificial intelligence itself. The authors of the theoretical works are mainly computer scientists and mathematicians . On the other hand, there are works whose authors are from the environment of social sciences and humanities, i.e. digital humanities . They focus on the topic of OCR and HTR from user perspective in terms of the practical applicability of existing OCR tools and platforms. Moreover, theoretical papers or user contributions can be divided into two groups according to whether they concentrate on OCR of printed or handwritten works (HTR).
A comprehensive overview of the READ project is included in a project study (Mühlberger 2016) and a collective study of READ researchers (Mühlberger et al. 2019), which is the first published overview of the use of HTR+ by a broad expert community and showing the current application manuscript recognition technology in cultural heritage sector. The collective study (Mühlberger, et al. 2019b) points to the development of character recognition methods.
Since the mid-20th century, character recognition of printed and handwritten documents has developed along with OCR. First, the scanned images of the printed text were converted to machine code and compared with the finished script templates. Printed documents contain characters from predefined, ready-made character sets, making comparison easier. However, even OCR software for printed characters are capable of further "training".
Unlike printed texts, handwritten texts pose a different problem due to the many differences in handwriting, authors and their hands, and changes in handwritten materials over time, numerous glyphs, tokens, personal and linguistic styles, etc.. Manuscripts have become a new challenge for computer scientists. First, in the 1980s, research and development on handwriting recognition was developed using statistical methods. This was followed in the 1990s by research and development of pattern recognition combined with artificial intelligence and the development of deep neural networks in the 2000s and 2010s. It was also a period of significant development and increasing the capacity of information and communication technology.
Mass digitization projects have been implemented in several developed countries and massive digital repositories and archives of printed and manuscript documents have been created . After mass digitization, the time has come to use the digital content obtained by digitizing manuscripts. To obtain usable, editable text from scanned images of handwritten documents, advanced Transkribus recognition technology – HTR+ and PyLaia machines can be used .
The project has all the attributes of a digital humanities methodology. In particular, these attributes include: (a) the cooperation of researchers; (b) scientification in the social sciences and humanities; c) interdisciplinarity; d) teamwork (interinstitutional, interstate, universities, libraries, archives, galleries, museums); e) heavy involvement of IT professionals in research, education, and knowledge dissemination; f) artificial intelligence (artificial neural networks, Hidden Markov Model (HMM)).
Advances in Research Hodel described the progress of printed text recognition based on optical type recognition (Hodel et al 2021). Hodel also deals with the most important practical aspect of transcription, namely the question of what accuracy or error rate in transcription is. Based on empirical data from the READ research and based on the findings of Günter Mühlberger (2019), Hodel lists three error classes. He considers it to be confirmed and verified to state that that: a) if the character error rate (CER) is less than 10%, which means 10 or less errors per hundred characters, then the transcription result is good, readable and, if appropriate, further editing of the output is possible; b) if the CER is ≤ 5%, then the transcription result is very good; (c) if the CER is below 3%, then the transcription results can be considered great, and any CERs below 2.5% are excellent.
Hodel pursues the goal of transcription without training and states that in order to create an optimal universal model of transcription of manuscripts of various hands, styles, scripts, periods, etc., which would not always require the preparation of separate models, it is necessary to have as many excellent models as possible. He believes that such transcription models should probably be developed for various similar classes of manuscripts, such as the cursive Gothic script of the 19th century, which is the subject of his attention.
Strobel too contributes to progress in the field of optical character recognition (OCR) (Strobel et.al 2020). Based on an analysis of the effectiveness of some OCR systems on printed German historical newspapers (Fraktur), the authors concluded that a sufficient training sample (so-called ground truth) is 50 newspaper pages. They base their findings on a comparison of five OCR systems: 1) ABBYY FineReader XIX10 (FRXIX) , version 2005, 2) ABBYY FineReader Server 11 (FRS11) integrated in previous versions into the 3) Transkribus and HTR+ Transkribus systems, 4) Kraken, 5) Tesseract.
Drobac (2020) provides insight into the effectiveness of OCR in historical newspapers and magazines published in Finland. The National Library of Finland has created an OCR corpus of more than 11 million pages using ABBYY FineReader for historical text. The estimated accuracy of OCR text was between 87% – 92% at the character level, which is quite low for scientific research.
Martinek et.al. (2020) presents in his theoretical experimental study a system of segmentation of printed text and OCR. He deals with a set of methods enabling to perform OCR of historical prints in German based on a small amount of training data. He describes his OCR system that uses recurrent neural networks. He focuses on partial processes of OCR system, mainly on page layout analysis, including the segmentation of the text block and lines, and on OCR itself. The experiments described are aimed at determining the best way to achieve good OCR results for historical German printed documents. For the experiment, they used digitised archival materials from the Porta fontium project from the Czech-Bavarian border. Specifically, it was 10 pages of newspapers Ascher Zeitung from the second half of the 19th century printed with Fraktur. They used 7 pages for training, 1 page for validation and 2 pages for evaluation of effectiveness. Additional 15 pages were used for page template identification and segmentation training. The authors consider the obtained results to be comparable or even better than the results of several recent systems. In the case of a Fraktur from a German newspaper, they achieved the following CER values in comparison with other systems: Porta fontium CER 0.024. Tesseract (deu_frak) CER 0.053. Tesseract (Fraktur) CER 0.045. Transkribus CER 0.027. It is not known whether the Czech experiments, including the application Pero OCR aim to create a competitive or supportive activity against the Transkribus platform and towards a specific freely available tool for the transcription of historical manuscripts and prints.
Martin Kišš (2018) deals with the topic of recognition of modern printed texts written by fracture in his thesis. He based his research on the TensorFlow tool, originally developed by Google and available as open-source machine learning platform. Part of his approach is a built-in generator of artificial historical texts. Using the generator, he created an artificial data set on which he trained a neural network for line recognition. He tested this neural network on real historical lines of text and achieved a success rate of 89.0% character accuracy after training.
Significance and Features of the Transkribus Platform
In addition to basic research, creating the Transkribus research platform was one of the main objectives of the READ project. About 2.5 million euros of 8.2 million euros were invested in the development of the research infrastructure . Now follow-up projects arise, in which basic and applied research continues. Adopting the Transkribus platform can also have significant economic effects.
According to data from the internal documentation of the READ project, the market prices of manual transcription of historical manuscripts range from 10 EUR to 30 EUR or more for simple English, German, Latin for a particular manuscript. Assuming 15 per page as the average cost, the READ Project's researchers generated monetary value of 4 to 6 million euros. This data represents an added value and a potential source of development of the newly established READ-COOP association and a convincing confirmation of the basic concept of research directed towards new knowledge and, at the same time, towards the commercial use of tools that are the results of the application of new knowledge. The approximate cost of transcription, including VAT, is shown in the table below .
Tab. 1 Automated transcription pricing
Representatives of digital humanities in Slovakia have various attitudes towards this initiative. Ranging from enthusiastic expressions of approval and admiration to very reserved or negative attitudes (such as "it's nothing for us", "we have other worries", "artificial intelligence will not replace us as experts"). These are often reactions that, on the one hand, verbally declare an interest in "digitisation" and "artificial intelligence", but on the other hand they show a lack of understanding and knowledge of the issues and possibilities of digitisation and the use of artificial intelligence. The attitudes suggest a preference for traditional paradigms of work and research rather than an actual effort to seek innovative tools to access and interpret our vast historical written heritage as part of Europe's cultural heritage.
As concerns the transcription of the Slovak language, this language was listed in the final report of the READ project thanks to our initiative, without any support and essentially without any interest of national institutions, archives, libraries, museums, and the academic sector. It was a job, to which the project’s author has devoted more than 3,000 hours since 2017 and financed until 2020 only his own resources. The results, know-how and experience achieved led us to an effort to introduce the revolutionary and innovative Transkribus platform in Slovakia and the Czech Republic , especially into the educational system, as well as into the practice of memory institutions through research and development projects. Of course, we also respect other transcription tools.
The Transkribus platform is free (open source) software with a guarantee of safe use for registered clients of the platform. Anyone can create their own account and then download the Transkribus Expert Client for free, or use the simpler Transkribus Lite tool. An API is available to connect clients' computers or mobile devices to the platform. Most of the software tools are free software that can be obtained from GitHub.
Alternatives to the Transkribus platform
In the study, we focus exclusively on the Transkribus platform and the transcription of manuscript collections and, marginally, on the transcription of printed materials. However, there are a number of other transcription tools. For example, OCR4all was developed to digitize old printed texts. Furthermore, the eScript application, which is used to transcribe handwritten and printed materials. The Rescribe tool is designed for desktop computers to use OCR on image files, PDFs, and Google Books. Applicable transcription tools include Pero.cz. The ABBYY Cloud OCR SDK is a high-quality cloud-based application via a web API. There are also more than 10 alternatives to ABBYY Cloud OCR SDK. The best alternative is Online OCR, which is free of charge. Other great sites and apps similar to ABBYY Cloud OCR SDK include Kofax Omnipage, Geekersoft OCR Word Recognition, and i2OCR. Quartex (Adam Matthew Digital 2018) is comerrcially available. In the future, researchers are faced with the task of developing a meta-analysis with criteria for evaluating the functionality and quality of transcription tools, applications, and platforms. However, the purpose of this study is not to evaluate other transcription systems.
READ COOP
The project was completed on June 30th, 2019. Subsequently, an international association was READ-COOP SCE (Societas Cooperativa Europeae – SCE) was established on July 1st, 2019. Its goal is to maintain and further develop the Transkribus platform. The experts and institutions are interested in the continuation and development of the Transkribus service. Presently, in October 2022, there are more than 90 000 users of Transkribus who work with the platform.
Figure. 1 Distribution of the Transkribus platform in Europe (Source: readcoop.eu, as of September 2022. As of August 2022: Members of READ-COOP SCE – READ-COOP (readcoop.eu))
Project SCRIPTOR
Slovak experts have responded to the new trends in OCR and research of historical documents with the SKRIPTOR project (Katuščák and Nagy, et al. 2019). The project has both European and national dimensions. The SKRIPTOR project is a direct continuation of the European READ Project. The technological and scientific innovations of the READ project are based on the use of artificial intelligence and digital humanities methodology. The task of the SKRIPTOR project researchers is to implement and disseminate the latest technological innovation and knowledge about the effective access of the professional and lay public to the Slovak and foreign written heritage.
The strategic objective of the SKRIPTOR project is to create conditions at the national level for a competent partnership of Slovak researchers with top European research, to establish and then actively engage in multilateral scientific European cooperation. The SKRIPTOR project is implemented in the field of history and archiving. It also spills over into library and information science.
The SKRIPTOR project focuses on modern documents. However, the collections that are subject to investigation and access may also include major recent texts and documents and incunabula, 16th-century printed materials, historical magazines, newspapers, as well as valuable 18th-20th-century materials.
The aim of creating new models using the Transkribus platform is to confirm its effectiveness and achieve in our collections a reduction in the price of transcription from 30 euros for manual transcription of a page to less than one euro per page for automatic transcription of texts.
In the SKRIPTOR project, we have preliminarily selected the following collections for research and experimental transcription: 1. Slovak and Czech Fraktur (Schwabacher and Antiqua); 2. Andrej Kmeť - personal handwritten letters; 3. Martin Lauček - Collectanea; 4. Postil of Izák Abrahamides Hrochotský from 1600 – 1601; 5. Postil of Juraj Schmideli-Kováčik from 1598 – 1607; 6. Canonical visitations of the Banská Bystrica Diocese from 18th to 19th centuries; 7. Hurban, J. M., handwritten documents; 8. Roman Catholic registries; 9. Forest Land Registers of Theresian Regulation; 10. Plot Records of Stable Land Register; 11. Congregation Records, Regional Records; 12. Other collections of written documents identified during archival research.
Fig. 2 Handwriting of Martin Lauček. From neat to more freeform handwriting
So far, in 2022, some outputs and related activities are available in the SKRIPTOR project: Publications: NAGY, I. (2021), TOMEČEK, O. (2021), BÔBOVÁ, M. (2021), KATRENIAK, M. (2022), KATUŠČÁK, D. (, 2020, 2021), KOVÁČOVÁ, K. (2022). Furthermore, the draft of the HITEXT project in the Czech Republic TAČR (2020) and NAKIIII(2022): KATUŠČÁK, D. (2020 and 2022). Participation in a student scientific conference in Opava, activities in the student grant competition SGS/5/2022 (SGS SU Opava). It is important to learn the functionality of the Transkribus platform and transfer knowledge to the education process in Slovakia and the Czech Republic.
Transcription Workflow
Based on our own experience, we understand transcription as a complex process, which presupposes mainly determination, availability of financial resources, and infrastructure. The main processes include:
Preparation. In particular: Information archival research (heuristics), identification of possible collections and documents, resolution of conditions of availability of collections and documents, quantification and selection of documents for transcription (number of pages and homogeneity of manuscripts), agreement with the owner or custodian of the collection on the place and method of scanning and rights,
Scanning. In particular: scanning, photographing documents, naming and organising directories and files on a computer, archiving source files (TIFF, RAW) and backing up derived files (JPG, PDF, PNG, etc.)
Fig. 3 A student of librarianship at the Silesian University scanning a manuscript text for her thesis in the archive in Jeseník using ScanTent and DocScan
Installation of Transkribus Expert Client and work with the Transkribus platform. In particular: consulting the Transkribus documentation, choosing the image format for Transkribus, quality control and preparing images for uploading to Transkribus, choosing the method of uploading files, creating your own collection, uploading selected files to the Transkribus platform in a collection
Manual transcription. In particular: selection of samples of pages for manual transcription according to the specifics of the manuscript, decision on sharing the collection with collaborators and their roles, manual transcription of the sample for the training set
Segmentation of pages and metadata. In particular: segmentation of pages or entire sets, quality control and correction of manual transcription and segmentation, document metadata, page metadata, structural metadata, comments, KWS.
Creation of a transcription model in the Transkribus Expert Client. In particular: training the machine to learn the transcription model, checking the quality and efficiency of the model and correcting the training set, restarting the model creation and checking the quality of the model, selecting ground truth for quality pages, using the model to transcribe all segmented pages in the collection
Access and use of transcription results. In particular: exporting results in different methods and formats, editing and correcting transcription results in Transkribus Lite, using a transcription model, making transcription results available on a local network or publishing transcription results on-line for use via read&search (see below).
Experiment with the Collection of Letters of Andrej Kmeť
Automatic transcription of handwritten text is what historians, linguists, archivists, librarians, documentalists and all others who come into contact with handwritten text have dreamt of for decades. Step by step, automatic transcription of manuscripts becomes a reality. In the background, there is massive international basic research in artificial intelligence and thousands of hours of work.
Of course, Transkribus, is not a substitute for professional and scientific erudition of historians and archivists. Therefore, their reserved attitude is understandable. Artificial intelligence does not compete with experts. It helps them. Automatic transcription is only one step in the scientific work of historians. This is followed by historical research of the text and the context of the transcribed texts and information, editing texts obtained by transcription, identification of entities, generation of keywords and metadata that are discovered in the text (dates, names of people, geographic locations, corporations, etc.).
The goal of more extensive transcription using cutting-edge Transkribus platform is to facilitate reading and make available unique collections of documents, archival units, preserved in the archives usually only in one copy. That is the difference between the occurrence of units in libraries and archives. The archives are unique, authentic original documents, collections, archival units, while libraries hold titles of documents that often come in hundreds to thousands of items. Unique archival materials need to be made available. The path to access leads through their transcription.
After transcription of historical texts and manuscripts, digital content may be edited, rendered, used and made accessible for use on a larger scale also in public information systems and services. In addition, the transcribed original text, for example, in Latin, Hungarian, German or another language can be at least approximately automatically translated in another language. This quite substantially changes the nature of the work of archivists and historians. The result of our work include transcription models of different quality. An overview of the models is provided in the table.
Tab. 2 An overview of experiments with transcription models of Andrej Kmeť's handwritten correspondence
Explanatory notes to the table:
Date: The date the model was created (YYYYMMDD).
Method: Selected handwritting transcription method (HTR+).
ID: The identification number of the model in our collections and among all Transkribus models on the remote server.
Training set: The number of pages and the number of lines that have been manually transcribed and used to train the machine in the Transkribus platform. In total, 211 pages were transcribed for the exercise. Of these, 185 are used for training and 26 for validation. The basic transcription contained 50 pages used to prepare the first model. From the transcription results, more edited pages were added to the training model and further models were created.
Validation set: The number of pages and lines selected from the total number of transcribed pages to verify the training accuracy.
CER accuracy: Percentage of character errors in the input file and in the validation set. For manuscripts, it is practically impossible for manual transcription to be 0.0%.
Number of cycles: The number of cycles (stages) that the machine used for learning (training).
CER/WER: The values reflect the actual practical, user-friendly accuracy or character error rate CER and word error rate WER in the six 2019-2021 models owned by the author. We tested all models on a single, as precisely prepared double page as possible in FINAL quality in the ID 115514 collection. It is a letter from Andrej Kmet to Ľ. V. Rizner (document ID 621673).
The average converted character error rate in six models is 5.0%, and five of them were generated on training sets and pages of different quality, which were mainly in status In Progress. However, for practical transcription of hundreds of other pages, it would be best to use the 36009 model created using 185 pages of the training set and 26 pages of the validation set. It appears that the lowest CER accuracy values in the validation set do not mean that the models that are in the first five lines of the sixth column in Table 2 and not created on the ground truth pages are most suitable for further transcription.
For the final preparation of this model, I used well-prepared pages in ground truth quality. In terms of the accuracy of transcription of other letters by Andrej Kmeť, I consider the results of the model 36009 with CER values of 2.48% and WER 7.73% as the best.
The data provided in the CER/WER column do not reflect the accuracy of transcription when creating a model with pre-prepared files for training (1.87%) and validation (5.79%), but the best values that apply to individual pages. That's why the values are different. The CER/WER of 2.48% and 7.73% are only the best values that refer to one page in a given model, which must be selected randomly from the collection and which is not transcribed in any way in advance. The WER value itself does not make any practical sense, because if we use Tools/Compare text version in Transcribus, we will find that, for example, punctuation, length, caron, dot etc. has a distinctive role in the word, and if it is added to or missing from the transcribed text compared to GT (Ground Truth), then the machine will consider the word to be erroneous, although the text is clearly understandable to the user and does not make it difficult to use. WER values are mostly used in mathematical linguistics, e.g. in machine translation.
We continuously organize and publish the results of document transcription on the Internet through a tool developed by the READ-COOP team called read&search. Public access to documents is possible through the read&search site – https://Transkribus.eu/r/slovakia-state/#/ website, the interface of which we have translated into Slovak. For comparison, we tested all the models listed in the table on a single, most precisely prepared double page in FINAL quality in the ID 115514 collection. It is a letter from Andrej Kmet to Ľ. V. Rizner (document ID 621673). The error rate of words is de facto irrelevant, because an erroneous character (e.g. punctuation) also causes the error rate of a word in most cases. However, for the practical transcription of hundreds of other pages, it will be most appropriate to use the 36009 model, which we created from 185 pages of a training file and 26 pages of a validation file. It turns out that the lowest CER accuracy values in the validation set do not mean that models that are in the table in the first five rows in the sixth column and are not created on the ground truth pages are best suited for further transcription.
For the final preparation of this model, we used well-prepared ground truth quality pages. From the point of view of the accuracy of transcription of Andrej Kmeť's other letters, we consider the results of Model 36009 with CER values of 2.48% and WER values of 7.73% to be the best. In the future, based on further experience, we will consider providing this model of ours for free use for similar manuscript collections.
Collection selection
A collection of handwritten correspondence of Andrej Kmeť, mostly in Slovak, kept in the Library of the Slovak National Museum in Martin, was selected for the experiment after the previous gracious consent of the Museum’s director. Some of the letters are in Latin, Hungarian and parts of the letters are also in German and Czech. This concerns letters written by Andrej Kmeť from 1841 – 1908. In the field of scientific approach to correspondence of scholars in modern times in the spirit of digital humanities methodology, the most comprehensive source of knowledge is undoubtedly the international research initiated and led by Howard Hotson in 2014 – 2018 (Hotson 2019). In this study, we are only interested in correspondence as an extensive set of handwritten materials suitable for experiments with automatic transcription.
Andrej Kmeť and his correspondence is a subject of systematic research by Karol Hollý, who also provides additional resources relating to Kmeť's literary remains (Hollý 2013, 2019).
Scanning
Capturing by scanning, or, more accurately, by photography, took place between 23rd to 30th May 2018 in the Library of the Slovak National Museum in Martin. The ScanTent (scanning tent) equipment and the freely available DocScan application was used for scanning. ScanTent was used with the purpose to verify the entire recommended Transkribus workflow. It is well-known that many archives have scanned some parts of their collections at a more or less good quality. The equipment selected in this case is useful in cases where collections have not been scanned yet. It is known that ordinary scientists and users are not allowed to remove archival material from study rooms. Amateur photography of pages with smartphones or cameras is problematic when it comes to larger files (thousands of pages). Therefore, ScanTent and DocScan are a potential and affordable choice, although with some practical issues (format, focus, quality). It should be noted, however, that in this case it is photography rather than scanning. In the future, I would definitely use a professional scanner for scanning in the highest achievable quality (300 to 600 DPI).
Five full archival boxes were scanned. Some of the letters were on multiple pages, there were also some incomplete pages, blank pages etc. One image can also contain more pages of a handwritten document. In the scanning step, images are created and not actual pages, unless a page is scanned individually. Sometimes it is preferable to scan sheets by pages, individually, because if a sheet is scanned as a double page, then one will have to organise pages in the right order in the image post-processing step. However, in the next step of text segmentation, it is possible to arrange the individual pages as blocks of text in the correct order. The individual pages in Andrej Kmeť's letters did not follow each other, so on the scanned image there were, for example, pages 3 and 1, on the next 2 and 4.
The total scanning time for about 3,000 pages was approximately 15 to 20 hours. Scanning was performed in manual single-page mode by individual sheets, not in series (not with automatic scanning after a page is turned), as the handwritten material is on separate sheets of different formats. A part of the materials comprises original letters, another part consists of photocopies. In particular, original letters are often on brittle paper which requires some conservation and preservation actions. Business cards and similar smaller paper sizes – DocScan required to zoom in on a scanned object, this was resolved by placing a blank A4 page underneath the missing areas of the sheets.
Some sheets were damaged (a missing corner, damaged edges of a sheet). In such cases, the system reported "no page found". This was resolved by using a white sheet as background sheet under the scanned page and its missing parts, then DocScan was capable of focusing.
Some components needed re-scanning, because not enough attention was paid to focusing. DocScan focuses on a sheet's surface in several spots, indicated by red and green markers. When focus is satisfactory, "OK" appears, then one can pull the trigger. For making pictures, we used a Samsung Galaxy 6 mobile phone with the Android operating system, with which DocScan worked at the time. Initially, there were some issues in the download of data from Samsung (Android) to MacBook Air (iOS). DocScan software is also currently available for the iOS operating system. Finally, a Windows PC was used to download images from the Samsung device. We consider the use of the DocScan system and the Samsung mobile phone to be an emergency solution, because in my further work, especially during segmentation, we discovered a relatively large number of blurred parts of pages. Because some parts of the pages were blurred, the segmentation was inaccurate and subsequently not even transcribed. In the future, we recommend using high-quality professional scanners for large valuable collections and capture in the highest achievable quality.
Fig. 4 Handwriting of Andrej Kmeť. Letter to J. V. Rizner
When scanning, the DocScan system can be connected directly to the server and the Transkribus platform (in Innsbruck or Rostock) and then scan and transfer images directly to the Transkribus platform. This option was not used for insufficient connectivity. We considered it necessary to check the accuracy and quality of the scan. Some operations on the Transkribus platform required the use of such tools as Preview, Adobe Acrobat, FileZilla Client v. 3.61.0, ABBYY FineReader PDF 15, Zoner Photo Studio X, and others. We used the tools to adjust the text orientation, eliminate duplicates, arrange pages in the set, merge files, etc.
The scanned digital content (images) was a) prepared for further processing in DocScan software (content identification, metadata), b) uploaded without modification on CD ROM for use in the collection’s owner at the discretion of the management, c) prepared for upload to the Transkribus platform and for further processing in the Transkribus software. Loading to the Transkribus server, segmentation, model generation, and transcription of the handwritten text followed.
The digital content was divided based on the arrangement as found in the archival boxes. Five compact discs (CDs) were recorded and handed over to the director of the Ethnographic Museum of the Slovak National Museum in Martin, dr. Mária Halmová. The collection's custodians can now use and publish the digital content. Furthermore, a CD may be placed in each box. They can decide whether to allow access to the collection on the CD or work with the relatively brittle original paper archival sheets. Gradually, we make the transcribed content available through the read&search software used as "software as a service (SaaS)". We are still exploring the possibilities of optimal preparation of metadata for documents and collections for publication via read&search.
Uploading Digital Image Files
The scanned images can be processed either locally or edited after being imported to the remote Transkribus server. Before importing to the server and before using the Transkribus platform, it is necessary to register, download Transkribus Expert Client. It is also possible to work with Transkribus Lite, in which, however, it is not possible to create custom transcription models. Then one needs to create a private collection, which is available only to the person who created it, unless the person decides to share it with other users. It is possible that a transcriber allows access to certain operations to students, operators, collaborators. It allows access to one's own collection for preparation of training samples, editing after transcription etc. Automatic transcription is carried out exclusively on the remote server using Transkribus Expert Client. Locally, it is possible to work with own documents and collections as needed.
Before importing files, one needs to create an own collection with own files for transcription. A single upload and import of images is possible up to 500 megabytes at a time. If the size of imported images is larger, they can be divided and uploaded in multiple batches. Larger image files can also be uploaded and imported using an FTP client such as WinSCP, also via URL or DFG Viewer METS. Images can be imported as PDFs, JPGs, TIFFs and other formats. The collection of images, created by scanning letters of Andrej Kmeť, was 11.7 gigabytes in size at 300 DPI resolution.
Our experience shows that before importing it is advisable to check the digital images, the quality, sharpness, bleed-through, completeness, page orientation, and so on. After some experience, we also imported large PDF files via faster, simple-to-use WinSCP software.
Segmentation
Having imported the files on the server, an automated process of segmentation must be performed on the server. For segmentation of text and images, the client application must be connected to the server. Segmentation means that the image of the handwritten text of the document, which is still on the server as an image, is automatically divided into blocks, areas, and lines of text. Manual corrections can be made as necessary. These include, for example, arranging, merging and splitting blocks, expanding a polygon, adjusting the base line below a line, segment boundaries, and the like. Segmentation is of key importance to transcription itself. High-quality scanned pages with sharp handwriting are usually segmented flawlessly. However, sometimes it is necessary to carefully check or adjust the manual order of text regions (TR) after segmentation, lines reading order, lines and polygons created by a machine (artificial intelligence).
HTR Machine Training
The Transkribus Expert Client machine is first trained on pages selected for the training set. The machine repeatedly, e.g. in 50 cycles, reads each page of the training set, and gradually identifies characters that cannot be unambiguously identified or that arose due to incorrect transcription of pages in the ground truth set.
The Transkribus system first creates a model on the pages of the training set. Characters that the machine considers to be incorrect are included in the incorrect characters in the training set. In statistics, this is the CER value on training set. The HTR machine must first be trained for a particular hand. As a rule, a learning machine should "see" 100 examples of each character contained in the document, which is usually about 50 pages of the training set prepared manually (Mühlberger et al. [2016]).
After training the model on the pages that have been selected for the training set, Transkribus Expert Client will automatically use the trained model created on the training set pages to validate it on the pages selected for the verification set. A verification (validation) set is used for practical testing of the model. The machine accesses the text in the verification file repeatedly each time, as if it was doing so for the first time and applies the model that it "learned" using the training set. At the end of this process, we have a model for automatic manuscript transcription. The most important value for evaluating the transcription accuracy of the created model is the value that expresses the character error rate in transcription in the validation set. This is the CER value on Validation Set.
Thus, a sample dataset of pages is selected from the collection imported based on a certain algorithm, which is then used for training the machine and setting up of a model for a certain handwriting type. It is necessary to show the machine some correct examples of text. Then, the machine learns the patterns of letters and words in accordance with the training set. If a collection of texts is written with more than one hand, then it will be necessary to select the appropriate size of both training and test sample by each hand. Page selection can be performed using a certain algorithm or automatically so that a batch sample is prepared that contains about 20,000 words. The training dataset is created directly in the Transkribus Expert Client both locally and on the server. Basically, it is necessary to transcribe a manuscript carefully and very precisely in the editor according to the lines, without correcting anything. Text needs to be transcribed using the language used at the time of creation, including all grammatical errors and also by further instructions and manuals that are available for this operation. The author and creator of the transcription model should determine the order of text parts, tagging, selecting and editing keywords, descriptive metadata, and so on. The outcome of transcription is then viewable and can be evaluated on a test set. If the outcome is satisfactory, the remaining files or the entire collection can be transcribed automatically. Simply, once the machine learning process and creation of the model if completed, the model is available to the owner, who can use it or share it with other users and apply it to any document. Correct and incorrect reading data become the basis of the model.
Automatic Transcription
Automatic transcription serves as the basis for scientific editing, in which the text can be modified, corrected, proofread, explicitly enriched with more data, context data, data deciphering, tagging, adding notes, metadata, annotations, corrections of diacritical marks, abbreviations, uppercase and lowercase letters, paleographical processing, ligatures etc. Automatic transcription was made after a run of training and testing. A custom model of transcription was used using HTR+.
Fig. 5 A screen displaying data after automatic conversion using the ID 36009 custom model
The result of learning in the automatic handwritten text transcription of Andrej Kmeť's letters was an excellent CER value of 1.37 % in the training dataset and 1.76 % in the test dataset. The training set contained 29,411 words and 4,573 lines. We used the model for other sheets and corrected them so that they were of ground truth quality.
In the process of familiarisation with the Transkribus Expert Client platform and despite our trials and errors, we made improvements in 2019 from an error rate of 22.81% in 2018 to an error rate of 1.76% with the HTR machine in 2021. Transcription effectiveness improved significantly after the HTR+ machine became available. At first, we only worked with training sets that were not of ground truth quality. The basic transcribed training set had 50 pages. We relatively easily expanded this basic set to 185 pages by transcribing additional pages using the older model. We corrected them and added them to the training set. We tried to correct the new pages as accurately as possible into ground truth quality.
Finally, we created the mentioned model no. 36009 of ground truth quality from the pages, which can achieve good to excellent transcription results depending on quality, images, character sharpness, handwriting quality, and segmentation quality.
Preliminarily, it can be stated that many transcription errors relate to punctuation. A detailed analysis of the causes of inaccuracies will be the subject of further research, as well as research into the correlation between scan quality and segmentation with respect to transcription quality.
Fig. 6 Text segmentation, transcription in the Transkribus editor and the result of automatic transcription
Transcription of Fraktur (Swabacher)
The experiment concerned the application of artificial intelligence to the automatic transcription of Slovak and Czech Fraktur and Schwabacher (Voit 2006). Fraktur is a Gothic typeface that has been used widely used since the 15th century in Czech and Slovak books, newspapers and magazines in the modern age and later, practically until the 1950s.
Fig. 7 Transcription of J. N. Bobula's Jánošík (printed) published in read&serch (besides the text at the top, overlay at the bottom)
As part of teaching the subject of digitisation at the Silesian University at the Institute of Czech Studies and Librarianship, we used the artificial intelligence tools of Transkribus Expert Client to prepare probably the first very successful transcription of Slovak and Czech printed text - Fraktur - the historical newspaper Moravské noviny, Opavský besedník and the Slovak publication titled Jánošík. We prepared transcription models for Slovak and Czech Fraktur scripts (Table 1). In the training set, we achieved an character error rate of 0.39%.. However, a higher value of 0.44% achieved on the validation set (CER on validation set) is decisive for the practical use of this model.
Tab 3 Transcription of Fraktur
From now on, we are able to transcribe Fraktur in Slovak and Czech historical printed materials with an accuracy of about 99%. In our case, the accuracy level is 99.56%. The error rate is 0.44%. The transcription results of the Czech text fracture are available after logging in the Transkribus platform in the FRAKTURA_CZ collection (114429, Owner) and on the Internet in the beta version of the read&search browser.
Fig. 8 Example of segmentation of the Moravské noviny 1849 (Antiqua and Fraktur)
Fig. 9 Example of transcription of the Moravské noviny 1849 using custom model
Fig. 10 Cut-out of transcription and display of text over transcribed text in read&serch
Further research
In further research, it will be appropriate to focus on the following areas: a) selection and standard description of larger Slovak and Slovak-related manuscript collections of European and national significance, b) digitisation of selected historical documents according to the experimental plan to confirm or improve known procedures and values with regard to the subsequent text segmentation process and automated transcription (correlation among various scanning conditions and quality and transcription, c) thorough analysis and description of text segmentation results, d) sharing of digital documents with archives and other institutions that will be able to use them at their own discretion as a replacement for paper documents, e) creation of models, training and analysis of automatic transcription models according to new-age and modern collections and languages (especially Slovak, Czech, Hungarian, Latin, German, Polish), f) verification and evaluation of usability of finished, available transcription models from research in the READ project, g) familiarisation with the best practice of automatic recognition of texts of historical documents in Europe, especially in Germany, Austria, Spain, Hungary, Great Britain, Finland, the Netherlands, Serbia, use of information and experience in Slovakia, h) automatic transcription of a substantial part of the Lauček's manuscript collection and its virtualisation, i.e. a single virtual digital presentation of volumes located in geographically various locations (Slovak National Library in Martin, Slovak National Archives in Bratislava, University Library in Bratislava, Országos Széchenyi Konyvtár in Budapest), i) research into the possibilities of increasing the efficiency of recognition of manuscript texts and texts of historical documents through the Transkribus platform and related tools, j) making transcribed and interpreted collections available to the general public via a digital repository, k) creating documentation that will be used for archives, libraries, academic institutions as well as individuals for automatic transcription of texts, l) building a digital humanities cabinet with a focus on transcription of historical documents.
Conclusion. Effectiveness of the Transkribus platform
Our experience verified by experiments confirms that handwritten materials can be automatically transcribed, the error rate can be very low and the results are excellent. The transcription results are readable and can be exported in various formats such as DOC, TXT, PDF, TEI, METS, further edited, adjusted, corrected, and used.
In the experiment, the accuracy level of 94.21% was achieved on Andrej Kmeť's handwriting with a character error rate (CER) of 5.79%. In transcription of printed Fraktur, the accuracy level was 99.56% with a character error rate of 0.44%.
In terms of perception, understanding and use of transcribed text in general, the authors of Transkribus platform hold that a) if error rate of "words" is counted strictly and if word error rate is up to 30 %, the text is still understandable and usable for humans, b) if error rate of "characters" is counted strictly and if the character error rate is up to 15 %, the text is still understandable and usable for humans.
The Transkribus platform is an excellent tool for patient and conscientious scholars. While it cannot substitute them in any way, they may find it very helpful when fine-tuning transcription by editing and correcting the results. The platform is not, and hardly ever will be, intended merely for "clickers", i.e. users who are accustomed to "clicking" rather than innovating patiently.
List of bibliographic references
KATUŠČÁK, D., I. NAGY, M. BÔBOVÁ, P. KUNC, A. KURHAJCOVÁ, P. MALINIAK, M. MIKUŠKOVÁ, L. NIŽNÍKOVÁ, I. POLÁKOVÁ, B. SNOPKOVÁ a O. TOMEČEK. (2019) SKRIPTOR Projekt APVV-19-NEWPROJECT-17816 (2020–2024). Inovatívne sprístupnenie písomného dedičstva Slovenska prostredníctvom systému automatickej transkripcie historických rukopisov. [Innovative disclosure of written heritage of Slovakia through the automatic transcription of historical manuscripts]. Organizácie: Univerzita Mateja Bela v Banskej Bystrici (zodpovedný riešiteľ doc. Imrich Nagy, PhD) a Štátna vedecká knižnica v Banskej Bystrici – partner (garant prof. PhDr. Dušan Katuščák, PhD).
ADAM MATTHEW DIGITAL, 2018. Handwritten text recognition: artificial intelligence transforms discoverability of handwritten manuscripts, [cit. 2.10.2021]. Dostupné z: www.amdigital.co.uk/products/handwritten-text-recognition.
BÔBOVÁ, M., 2021. Projekt Skriptor, keď stroj sa stáva žiakom. In: Vedecká online konferencia NON SCHOLAE, SED VITAE DISCIMUS, dňa 7. júna 2021 v gescii ŠVK v Prešove.
DROBAC, S., 2020. OCR and post-correction of historical newspapers and journals (Doctoral dissertation). Helsinky: University of Helsinki, 2020. ISBN 978-951-51-6511-4 (paperback), ISBN 978-951-51-6512-1 (PDF), [cit. 10.6.2022]. Dostupné z: https://helda.helsinki.fi/bitstream/handle/10138/319496/OCRandpo.pdf?sequence=1&isAllowed=y.
HODEL T., D. SCHOCH, C. SCHNEIDER a J. PURCELL, 2021. General Models for Handwritten Text Recognition: Feasibility and State-of-the Art. German Kurrent as an Example. Journal of Open Humanities Data, 7, 13. [cit. 1.10.2022]. Dostupné z: https://openhumanitiesdata.metajnl.com/articles/10.5334/johd.46/.
HOLLÝ, K., 2013. Veda a slovenské národné hnutie: snahy o organizovanie a inštitucionalizovanie vedy v slovenskom národnom hnutí v dokumentoch 1863–1898. Bratislava: Historický ústav SAV v Typoset Print s. r. o., 2013.
HOLLÝ, K., 2015. Andrej Kmeť a slovenské národné hnutie: Sondy do života a kreovanie historickej pamäti do roku 1914. Bratislava: Veda, Historický ústav SAV, 2015. 279 s. ISBN 978-80-224-1480-7.
HOTSON, H. a T. WALLNIG (eds.) , 2019. Reassembling the Republic of Letters in the Digital Age. Göttingen: Göttingen University Press, 2019. 470 s. [COST Action IS1310; 2014–2018. ISBN 978-3-86395-403-1. DOI: https://doi.org/10.17875/gup2019-1146. [cit. 1. 10. 2022] Dostupné z: https://www.univerlag.uni-goettingen.de/handle/3/isbn-978-3-86395-403-1.
KATRENIAK, M. (2022). Automatická transkripcia rukopisných historických textov na príklade vybraných kanonických vizitácií. Dostupné z: https://opac.crzp.sk/?fn=detailBiblioForm&sid=BDC2D20A28F62792149F199B8B08.
KATUŠČÁK, D. ,2008. Súčasný stav formovania stratégie digitalizácie na Slovensku. In: Kolokvium knihovních a informačních pracovníků zemí V4+. 6.–8. července 2008, Brno, ČR. Elektronický sborník, s. 30–46.
KATUŠČÁK, D., 2021. Pochybná hodnota za veľa peňazí? In: Kultúrny kyslík. 2021, č. 2, s. 14–17. ISSN 1339-6919. [cit. 3. 10. 2021]. Dostupné z: https://via-cultura.sk/kulturny-kyslik-2-2021/.
KATUŠČÁK, D. a M. KATUŠČÁK., 2011. Základná koncepcia národného projektu digitálna knižnica. In: Knižnica, 2011, 12(2), 6–10. [cit. 2.10.2021] Dostupné z: https://www.snk.sk/images/snk/casopis_kniznica/2011/februar/06.pdf
KATUŠČÁK, D., 2011a.Digitálna knižnica a digitálny archív. Národný projekt. Operačný program informatizácie spoločnosti OPIS2. Implementácia 2010–2015. Martin: Slovenská národná knižnica, 2011. [Kompletný projekt k žiadosti o nenávratný finančný príspevok zo štrukturálnych fondov Európskej únie ca 4000 s.].
KATUŠČÁK, D. , 2011b. Národný projekt digitálna knižnica a digitálny archív. In: Bulletin Slovenskej asociácie knižníc. Bratislava: SAK, 2011. 38 s. [Opis projektu] Dostupné: http://dusan.katuscak.net/2011/12/02/digitalna-kniznica-a-digitalny-archiv-opis2/.
KATUŠČÁK, D., 2011c. Situační zpráva o národním projektu SNK Digitální knihovna a digitální archiv. In: 12. konference Archivy, knihovny, muzea v digitálním světě 2011. Praha: SKIP, 30. listopadu a 1. prosince 2011 v konferenčním sále Národního archivu v Praze, Archivní 4, Praha 4 - Chodovec. [cit. 2.10.2021] Dostupné z: http://old.skipcr.cz/dokumenty/akm-2011/Katuscak.pdf.
KATUŠČÁK, D., 2021. Progress in making available blackletters typefaces and handwritten written heritage using artificial intelligence. Preprint. Researchgate. 2021, 25 s.
KOVÁČOVÁ, K., 2022. [bakalárska práca] Výběr pozoruhodných rukopisných sbírek Jesenicka. [cit. 2.10.2022]. Dostupné z: https://is.slu.cz/th/bum3h/FPF_BP_2022_53474_Kovacova_Klara.pdf.pdf
KIŠŠ, M., 2018. Rozpoznávání historických textů pomocí hlubokých neuronových sítí. Brno, 2018. Diplomová práce. Vysoké učení technické v Brně, Fakulta informačních technologií. Vedoucí práce Ing. Michal Hradiš, Ph.D.
MARTÍNEK, J., L. LENC a P. KRÁL, 2020. Building an efficient OCR system for historical documents with little training data. Neural Computing & Applications 32, 17209–17227 (2020). [cit. 2.10.2021] Dostupné z: https://doi.org/10.1007/s00521-020-04910-x.
MINISTERSTVO KULTÚRY SLOVENSKEJ REPUBLIKY, 2019. Revízia výdavkov na kultúru. Priebežná správa. Október 2019. Kap. 4.4 Projekt digitalizácie, s. 75–78. [cit. 2.10.2021] Dostupné: https://www.culture.gov.sk/wp-content/uploads/2019/12/Revizia_vydavkov_na_kulturu_priebezna_sprava_compressed.pdf.
MINISTERSTVO KULTÚRY SLOVENSKEJ REPUBLIKY, 2020. Revízia výdavkov na kultúru. Záverečná správa. Júl 2020. Kap. 4.9 Digitalizácia kultúrneho dedičstva, 132–139. [cit. 2.10.2021] Dostupné: https://www.culture.gov.sk/wp-content/uploads/2020/10/Revizia_vydavkov_na_kulturu_-_zaverecna_sprava_compressed.pdf.
MÜHLBERGER, G.,2016. READ (Recognition and Enrichment of Archival Documents) – 2016–2019. [Projektová štúdia]. [cit 6.10.2021.] Dostupné z: https://www.academia.edu/22653102/H2020_Project_READ_Recognition_and_Enrichment_of_Archival_Documents_-_2016-2019.
MÜHLBERGER, G., L. SEAWARD, M. TERRAS, S. ARES OLIVEIRA, V. BOSCH, M. BRYAN, S. COLUTTO, H. DÉJEAN, M. DIEM, S. FIEL, B. GATOS, A. GREINOECKER, T. GRüNING, G. HACKL, V. HAUKKOVAARA, G. HEYER, L. HIRVONEN, T. HODEL, M. JOKINEN, P. KAHLE, M. KALLIO, F. KAPLAN, F. KLEBER, R. LABAHN, E.-M. LANG, S. LAUBE, G. LEIFERT, G. LOULOUDIS, R. McNICHOLL, J.-L. MEUNIER, J. MICHAEL, E. MüHLBAUER, N. PHILIPP, I. PRATIKAKIS, J. PUIGCERVER PÉREZ, H. PUTZ, G. RETSINAS, V. ROMERO, R. SABLATNIG, J.-A. SÁNCHEZ, P. SCHOFIELD, G. SFIKAS, C. SIEBER, N. STAMATOPOULOS, T. STRAUSS, T. TERBUL, A.-H. TOSELLI, B. ULREICH, M. VILLEGAS, E. VIDAL, J. WALCHER, M. WEIDEMANN, H. WURSTER a K. ZAGORIS, 2019. Transforming scholarship in the archives through handwritten text recognition: Transkribus as a case study. Journal of Documentation, 75(5), 954–976. Dostupné z: https://doi.org/10.1108/JD-07-2018-0114.
MÜHLBERGER, G., J. ZELGER a D. SAGMEISTER, 2014. User-driven correction of OCR errors: combining crowdsourcing and information retrieval technology. In: ANATONACOPOULOS, A. & K. U. SCHULZ. (Eds.), DATeCH’14: Proceedings of the First International Conference on Digital Access to Textual Cultural Heritage, Madrid, Spain, 19–20 May 2014 (s. 53–56). New York, NY: Association for Computing Machinery. Dostupné z: https://doi.org/10.1145/2595188.2595212.
MÜHLBERGER, G., S. COLUTTO a P. KAHLE [2016, Preprint] Handwritten Text Recognition (HTR) of Historical Documents as a Shared Task for Archivists, Computer Scientists and Humanities Scholars. The Model of a Transcription & Recognition Platform (TRP). Dostupné z: https://www.academia.edu/8601748/Preprint_Handwritten_Text_Recognition_HTR_of_Historical_Documents_as_a_Shared_Task_for_Archivists_Computer_Scientists_and_Humanities_Scholars_The_Model_of_a_Transcription_and_Recognition_Platform_TRP_?bulkDownload=thisPaper-topRelated-sameAuthor-citingThis-citedByThis-secondOrderCitations&from=cover_page
MÜHLBERGER, G., 2002. Digitising instead of mailing or shipping: a new approach to interlibrary loan through customer-related digitisation of monographs. Interlending & Document Supply, 30(2), 66–72. Available at: https://doi.org/10.1108/02641610210430523.
NAGY, I., 2021. Možnosti aplikácie metódy digitálnej transkripcie historických rukopisných textov pri sprístupňovaní archívnych fondov = The Possibilities of application the method of digital transcription of historical manuscript texts in the process of accessing the archival fonds. In: Slovenská archivistika. Bratislava: Ministerstvo vnútra Slovenskej republiky, 2021, 51(2), 53–67. ISSN 0231-6722. Available at: https://www.minv.sk/swift_data/source/verejna_sprava/odbor_archivov_a_registratur/archivnictvo/slovenska_archivistika/SA%202-2021,%20roc.%2051.pdf.
POOLE, A. H., 2017. The Conceptual Ecology of Digital Humanities. In: Journal of Documentation, 2017. 73(1), 91–122. [accessed on 03-10-2021]: Dostupné z: https://www.academia.edu/27862789/The_Conceptual_Ecology_of_Digital_Humanities.
STROBEL, P. B., S. CLEMATIDE a M. VOLK, 2020. How Much Data Do You Need? About the Creation of a Ground Truth for Black Letter and the Effectiveness of Neural OCR. In: Proceedings of the 12th Conference on Language Resources and Evaluation (LREC 2020), pages 3551–3559 Marseille, 11–16 May 2020 c European Language Resources Association (ELRA).
ŠTUDENTSKÁ grantová súťaž SGS/5/2022 (SGS SU Opava). Tvorba modelu automatické transkripce historického rukopisu s využitím umělé inteligence. Řešitel: prof. PhDr. Dušan Katruščák, PhD., Ing. I. Kyselová, PhD., od októbra 2022 aj K. Kováčová. KOVÁČOVÁ, K. a I. KYSELOVÁ, 2022. Robot čte rukopisnou kuchařskou knihu z roku 1667? In Študentská vedecká konferencia. Slezská univerzita v Opavě, April 5, 2022.
TOMEČEK, O., 2021. Metales Banskej Bystrice z roku 1820. Reambulácia juhozápadného úseku mestských hraníc spoločných so susedným teritóriom rodiny Radvanských = Metales of the town Banská Bystrica from 1820. Perambulation of the southwest part of town borderline common with neighbouring domain of Radvanský family / Oto Tomeček. In Acta historica Neosoliensia : vedecký časopis pre historické vedy. Banská Bystrica: Vydavateľstvo Univerzity Mateja Bela – Belianum, 2021, 24(2), 112–133. ISSN 1336-9148. Available at: https://www.ahn.umb.sk/tomus-24-num-2-tomecek-o-metales-banskej-bystrice-z-roku-1820-reambulacia-juhozapadneho-useku-mestskych-hranic-spolocnych-so-susednym-teritoriom-rodiny-radvanskych/.
VOIT, P., 2006. Encyklopedie knihy: starší knihtisk a příbuzné obory mezi polovinou 15. a počátkem 19. století. Praha 2006. Švabach – Encyklopedie knihy. [cit. 2.10.2022]. Dostupné (časť šwabach): Švabach – Encyklopedie knihy. Available at: https://www.encyklopedieknihy.cz/index.php/%C5%A0vabach.
Acknowledgements
PhDr. Mária Halmová, Mgr. Viera Varínská ,and PhDr. Anna Peťová, for their help in scanning the manuscripts of Andrej Kmeť in the Ethnographic Museum in Martin.
Oľga Kuchtová from Banská Štiavnica for her help in finding out information about the life and conditions of Andrej Kmeť's work in Prenčov. Mgr. Mária Bôbová, PhD., State Scientific Library in Banská Bystrica, for assistance and cooperation in manual transcription and page segmentation for the training model and transcription of Andrej Kmeť's letters. Lucie Valjentová, a student of librarianship from the 4th year of the Institute of Czech Language and Library Science of the Silesian University in Opava, for her help in transcribing the Czech Fraktur texts. Aleš Drahotušský for providing newspapers from the Digital Library of the State Scientific Library in Ostrava.
Notes
1 ORCID: 0000-0001-7444-1077. Silesian University Opava. Faculty of Philosophy and Science in Opava; Institute of Czech Language and Library Science. State Scientific Library in Banská Bystrica.
2 The study is the output of the project APVV-19-0456 SKRIPTOR – Innovative disclosure of the written heritage of Slovakia through a system of automatic transcription of historical manuscripts.
3 OCR – Optical Character Recognition
4 READ Recognition and Enrichment of Archival Documents, a project implemented in 2016-2019 under the Horizon 2020 programme. [accessed on 02-10-2021]. Available at: https://cordis.europa.eu/project/id/674943.
5 Dušan Katuščák was one of the three evaluators of the READ project for the European Commission.
6 Transcribus. A comprehensive platform for digitizsation, AI-powered text recognition, as well as transcription and retrieval of historical documents – from any location, any time, and in any language. In Transkribus Lite, it is possible to use the Transkribus Expert Client collections in the browser of PCs and smartphones. Many of the features from the Transkribus Expert Client can also be used in Transkribus Lite. The platform integrates tools developed by research groups across Europe, including the For Pattern Recognition and Human Language Technology group of the Technical University of Valencia and the CITlab University Rostock group. As of October 2022, Transkribus had more than 94,000 users, 40 million images, 20 million recognized pages. The platform was developed in the context of two EU projects, tranScriptorium (2013-2015) and READ (2016-2019).
7 SKRIPTOR. Project APVV-19-NEW PROJECT-17816 (2020-2024 Inovatívne sprístupnenie písomného dedičstva Slovenska prostredníctvom systému automatickej transkripcie historických rukopisov. [Innovative access to written heritage of Slovakia through the automatic transcription of historical manuscripts]. Research organizations: Matej Bel University in Banská Bystrica (principal investigator doc. Imrich Nagy, PhD); State Scientific Library in Banská Bystrica – partner (guarantor prof. PhDr. Dušan Katuščák, PhD).
8 The research was previously funded as part of the tranScriptorium project. This project has received funding from the European Union's Seventh Framework Programme for Research and Technological Development under grant agreement No 600707.
9 If you are interested in transcribing individual shorter documents, you can try using one of the publicly available transcription models with a similar font, print or handwriting.
10 HTR – Handwritten Text Recognition
11 HTR+ – Handwritten Text Recognition. Transkribus' HTR+ software cannot start automatic transcription immediately, but must first be trained in a specific font and handwriting.
12 In Slovakia, it was an extraordinary and unprecedented national project of mass digitization and conservation in the European context under the auspices of the Slovak National Library (SNK) in Martin called Digital Library and Digital Archive 2012–2015, initiated and authored by Dušan Katuščák (Katuščák et al. 2008, 2011a, 2011b, 2011c, 2021 and others). The project was partially implemented on the basis of a contract between the SNK and the Office of the Government of the Slovak Republic of 7 March 2012 on the provision of a non-refundable financial contribution in the amount of more than EUR 49 million. A unique infrastructure has been built: 20 scanners, including 10 digitizing robots and semi-automated machines, a digital archive for the long-term preservation of digital content, the Slovakiana platform for access to digital documents, and 73 new jobs have been created. The aim was to digitize about three million documents and in fact the entire Slovak library collections, books, newspapers, magazines, anthologies, etc. The project is unique in integrating mass industrial digitization and industrial preservation of deteriorating acidic paper. After substantial management changes in 2012, only about 10% of the planned volume was digitized by 2021 and a total of about 60 million euros were used in the SNL. Mass deacidification of paper is not done, so paper as a carrier further degrades irreversibly (irreversible thermodynamic process). Digital documents are not available online. The state of digitization is partially critically described in the analyses of the Ministry of Culture of the Slovak Republic (MKSR, 2019 and MKSR, 2020).
13 PyLaia is a tool for handwritten text recognition that is supported in addition to the CITlab-HTR+ engine. The two engines work quite similarly, and so the results are usually similar in character error rate (CER). The only difference is that in PyLaia users can set several parameters by themselves. The network structure of PyLaia can also be changed– which is an opportunity for those familiar with machine learning. Modifications to the neural network can be made through the Github repository. HTR+ will usually give better results with curved or inverted lines, but it's possible that PyLaia will soon be able to keep up with this. HTR+ is required if it is necessary to use Text to Image tool as this has not been implemented in PyLai yet. Documents that have been transcribed using the PyLaia model can be searched using the full-text search (Solr) in Transribus.
14 CER (Character Error Rates) is a measure of character errors (compares for a given page the total number of characters (n) including spaces with the minimum number of insertions (i), substitution (s) and deletion (d) of characters that are required to get the result of Ground Truth. These are therefore errors compared to the exact text. The formula for calculating CER is as follows: CER = [ (i + s + d) / n ]*100. Every small mistake in the transcription is a statistically complete error. This means that any missing comma, "u" instead of "v", extra space, or even a capital letter instead of a lowercase letter are included in the CER as an error.
15 READ-COOP. [accessed on 01-10-2022] Available at: About us – READ-COOP (readcoop.eu). In October 2022, the association had 113 members from 27 countries. Slovakia was the only member country from Central and Eastern Europe at that time.
16 Manual transcription: 10–15 euros/page; automatic transcription – Transcribus: ca 0.12 € – 0.14 €/page. Calculated by: Transkribus Credits & Pricing – READ-COOP (readcoop.eu).
17 In 2017, the author worked with the version of Transkribus Expert Client v1.3.7. Version 1.22.0 was available in October 2022.
18 HITEXT. In 2022, the Silesian University in Opava prepared a proposal for an applied research project with the acronym HITEXT in the NAKI III program. The project is being assessed in 2022. In addition, we are addressing the issue as part of education and in the student grant competition project in 2022.
19 Project of the Slovak Research and Development Agency - APVV-19-NEWPROJECT-17816 (2020–2024). Inovatívne sprístupnenie písomného dedičstva Slovenska prostredníctvom systému automatickej transkripcie historických rukopisov. [Innovative disclosure of written heritage of Slovakia through the automatic transcription of historical manuscripts].
20 KWS (The Keyword Spotting) is a powerful search tool that helps find similar images of words in documents. The main advantage is that there is no need for documents to be definitively transcribed. It simply launches some text transcription model, and then the documents can be searched immediately. KWS reliably finds words and phrases (variants of text images). This tool will show the pages containing the specified keyword and display a preview snippet. In addition, it provides an image between values of 0 and 1 (0 = lowest and 1 = highest) to evaluate the quality of the search results.
21 I remember how much effort and time Pavol Vongrej had to spend in the past to transcribe 20,400 verses of the manuscript work of Mator Michal Miloslav Hodža, or Viliam Sokolík to transcribe part of the correspondence between A. Kmeť and V. Rizner. In 1991, in cooperation with Ing. Ján Mišík, I tried to use a character recognition system for automatic transcription of handwritten cataloguing records from the old catalogue of the Slovak National Library (Matica slovenská). As a result, the IRIS OCR transcription efficiency was approximately 35/40% and the transcription was unusable. I published signal information about working with the Transkribus platform in 2018 in a blog and in a Facebook status. I was surprised by the declared interest in this job. This is understandable, because many historians, linguists, librarians, educators are increasingly educated in the use of new technologies in their work and understand that innovations that make their work easier are important.
22 WER – Word Error Rates
23 The transcription states are: New (newly uploaded documents), In Progress (automatic change of status after page editing), Done (page transcribed), Final (page transcribed and checked), Ground Truth (100% correctly transcribed page). This means that work with each individual page is recorded, and different states can be assigned to the page version, depending on how much progress has already been made on them.
24 Petr Voit is an excellent expert in writing. In his works, there are examples of variants of the typeface of Czech historical prints, which definitely need to be examined from the point of view of transcription.
25 There are several types of the Gothic script. For example, the French textura with a very sharp fracture and a slim structure, the Italian wider and rounder rotunda with milder arch breaks, the mixed type – bastarda, in Germany, the Swabacher script – the font of wider, more oval shapes, and Fraktur – the script of narrower and more pointed shapes with ornamental features. With the invention of the printing press (in 1450 by Johann Gutenberg), this typeface became very widespread, especially in German-speaking countries.
26 Martin Lauček (May 12th, 1732 – †February 9th, 1802) was a Slovak Protestant priest, translator and religious writer. He is the author of the monumental manuscript work Collectanea containing about 24 volumes and about 20,000 pages. Collectanea is an invaluable source of knowledge and information on the history of the Protestant Church and a source on the history of Protestantism. Our goal is to collect all available volumes and create one virtual publicly available digital collection. Next, we will analyze the texts and try to have them automatically transcribed and published for everyone.
KATUŠČÁK, Dušan. Umelá inteligencia pomáha sprístupňovať písomné dedičstvo. Knihovna: knihovnická revue. 2022, 33(2), ,,,,,. ISSN 1801-3252.
]]>
Keywords: Teplice, church music, thematic catalogue, collection of sheet music, composers, choir-masters, contrafacta, Gellert, 18th century, 19th century
]]>
Keywords: document, medium, document theory, communication models, IFLA LRM
Introduction
This study is a loose continuation of our review study presenting major document theories (Kučerová 2021). We will complement the perspective of document through the lens of scientific theories with the point of view applied in the reference conceptual models of social communication.
We will look into document in the framework of social communication. It is evident that the key role of documents is to facilitate communication in society, and in the current stage of development of information and communication technologies documents are often a precondition, without which communication would not be possible at all. Therefore, we believe it is useful to define document in the context of social communication. In our opinion, developing a model is the most promising method of the research methods profiled in social communication and it is applicable in the field of information science. It can be stated that models are among the scientific research methods that not only effectively interconnect empirical and theoretical knowledge within a given discipline, but are also a highly effective tool for interdisciplinary communication of knowledge and cooperation of scientific disciplines to address complex problems, thanks to their emphasis on a concentrated and simplified representation of a phenomenon being examined.
The aim of the study is to assess whether and how models of social communication can contribute to the formation of the document theory. Using the results of the analysis of selected models, we will try to design our own working model of document. While we applied the method of literature research in the previous article, this study is based on the method of conceptual analysis of communication models and on conceptual modelling.
The paper is divided into four parts. The first part defines the conceptual and theoretical framework of the study and characterizes the methods applied. The second part documents the course of the analysis of communication models: the requirements for the definition of the document are summarized, three selected communication models are briefly described, and the result of their conceptual analysis is presented in the form of derived concepts and their working characteristics. In the third part, we offer the definition of the term document through a model in the form of a class diagram in UML and its partial verification on real-life cases. The fourth part is devoted to discussion and consideration of possible further research directions.
1 Conceptual and Theoretical Framework of the Study
Documents pervade all spheres of practical and theoretical human activity, and therefore the scope of disciplines that can contribute to the understanding of the concept of a document is virtually unlimited. In order to achieve the set goal, however, it was necessary to adopt certain restrictions: 1) we will view the document as a part of communication in society and 2) we will narrow the conceptual and terminological basis employed down to the disciplines that form the theoretical background of the social communication models analysed.
In the first section of this chapter, we will define the concept of social communication for the purposes of our study. In the following section, we will explain why we have decided to use the term "document", or why we consider it relevant even in the current development stage of information and communication technologies. The third section is devoted to the description of the methods used, i.e., conceptual analysis and conceptual modelling.
1.1 Social Communication
In this part, we will set out the basic outline of thinking about social communication, which we will apply in our study. In Part 2, we will observe how this outline is further developed in the analysed models, which complement it with other important aspects.
Communication generally involves transmission through space (transfer) or time (preservation, transmission), allowing connection or sharing in order to access a resource. The process of communication always takes place in a certain context, it has a defined starting and ending point and an entity that is made available by transmission or sharing.
Social communication is a specific type of communication whose context is formed by society and the starting and finishing points are people. Connecting people and sharing messages is considered a condition for the existence of a company and any joint activity and cooperation. The connection can be direct (for example, a face-to-face conversation) or indirect (for example, an online conversation via Skype or a communication between the author and the reader through a book). It is clear that documents play an important role in indirect communication.
A certain terminological problem is represented by an entity made available during social communication, for which different terms are used in specific contexts and discourse communities. In the models we have selected for analysis, we will encounter the terms message, communication, and content. It can be concluded that in the same sense in which these terms are used in social communication, the term information is usually used in information science[1]. Although each of these terms has its own specifics, we will consider them synonymous for the purposes of our study. For the sake of uniform nomenclature in this study, we consider it necessary to prefer one of them and then use it consistently throughout the text.
Since definitions of a document applied in information science usually include the term information[1], this term is preferred. However, one may object to its arguing that not everything that is communicated in society is information, and not all documents serve their users as a source of information.[2] The group of "non-informative" includes a large part of artistic creations and entertaining documentaries (dance music, board games, poetry...), as well as so-called performative documentaries (for example, advertisements whose aim is not to inform about goods, but to get the customer to buy them).
After considering the applicability of each term for the purposes of this study, we decided to prefer the term content. The basic outline of thinking about social communication is therefore defined as the transfer of content between people within society.
1.2 Terminological Considerations: Why a "Document"?
The starting point of our reasoning is determining the need to find an apt designation for the term, which we have so far preliminarily characterised as a tool of indirect communication of content. This term assumes a sufficiently broad and expandable extension to cover all past, present and future types of means of communication. At the same time, it is necessary for the name to have a sufficiently specific intension that prevents including among its instances any entities that do not serve social communication. The fact that we are far from a consensus on such a term is eloquently evidenced by the note to the entry document in the ISO 690 standard (2021, 3.13): "In some professional usage, documents are referred to as 'medium', 'title' or 'item'. In library practice, the terms 'publication', 'resource' and 'information resource' are also common."
In some fields, the issue of finding an optimal term is resolved by adopting terms that originally denote narrower terms limited to a certain type of communication media. These terms are then used to convey two meanings: 1) in the original specific meaning, and 2) in an artificially expanded extension covering other types, such as images, sound recordings, performances, databases, etc. For this purpose, both "traditional", relatively semantically stable terms and "modern" terms are used, which are generally understandable thanks to the mass spread of information and communication technology. The most frequently used terms are text, which is used mainly in literary science and other humanities disciplines (Beard 2008, Lund 2010) and book, a traditional term for librarianship. Just to name a few, let us recall that the first three Ranganathan's laws of library science are worded as follows: "Books are for use; Every reader his/her book; Every book its reader" (Ranganathan 1931) apply to all types of materials in libraries. Paul Otlet also considered it useful to supplement his broadly focused Treatise on Documentation with a subtitle A Book about a Book (Otlet 1934). A similar broadening of meaning is automatically assumed for the terms bibliography, bibliographic description or bibliographic control. Other terms with such broadened extensions include publication, record, or in Patrick Wilson's words, "writing and recorded speech" (Wilson, 1968, p. 6) and data, or collections of data (database, dataset or data set).
The second method of dealing with the broad extension of an entity being defined is to use terms denoting general umbrella terms such as material, work, piece of work, creation, medium, title, item and currently probably the most widespread term source/resource, which are able to encompass all types of communication tools, but also include entities other than communication media. An example is the definition of a resource in the Internet standard RFC 3986, which defines a generic syntax for URIs, in which a resource is considered to be any concrete or abstract entity identifiable by a URI. Also, in the language of RDF (Resource Description Framework) for describing resources in a semantic web , anything that is described in this language, or that can have a property, is referred to as a resource. Robert Glushko explains that "resource has an ordinary sense of anything of value that can support goal-oriented activity" (Glushko, 2016, p. 36). In this way, the term resource is close in meaning to the concept of asset, which is "anything that has value" according to ISO 690 (2021, 3.3).
Fig. 1 Alternatives to the term "document"
In Figure 1, the three overlapping ovals schematically illustrate the semantic range of alternative concepts to the concept of document: the concepts of text, book, publication, record, and data, located in the central oval, have a narrower scope, and the concepts of work, item, piece of work, material, medium, creation, title and resource in the outer ring exceed the meaning of the term "document". In fact, the relationship among these concepts is, of course, much more complex, as their meaning often overlap, at times to the level of synonymy. Also, the understanding of their meaning often varies, depending on the specific context and discourse community using them.
We will briefly discuss the relatively frequent term information resource, which is used mainly in the discourse community of information science. The adjective "information", seemingly specifying the general term resource, brings about another issue – even if we were to disregard the fact that it is determined by the highly ambiguous and difficult-to-define concept of information and would incline towards the common understanding of information as meaningful information concerning reality, such a specification in the sense of what we have mentioned in section 1.1 is, on the contrary, too narrow and excludes numerous entities communicated in society.
Compared to the alternative concepts mentioned above, the concept of document seems more appropriate. We agree with Hana Vodičková, who expressed such opinion in 2007 when she was considering Czech equivalents for the English term manifestation from the FRBR model (Vodičková 2007). We believe that the document theories by Suzanne Briet, Paul Otlet or Michael Buckland, which we presented in the review study (Kučerová 2021), convincingly demonstrate that the concept of document has a sufficiently broad extension to cover all types of social communication tools. For these purposes, there is no need to artificially expand its extension, as is the case with the metonymic (pars pro toto) use of the concepts of text, book, publication, record, data, and information resource. At the same time, the concept of document has a sufficiently specific intension that enables exclusion of entities that cannot be considered tools for communicating content. This is its advantage over the concepts from the second, general group, which have such a wide-ranging extension that they can be used to designate practically anything. In addition, the concept of document is characterized by its semantic power to cover electronic and multimedia resources without the need for any terminological modifications as in the case of e-books, hypertext, online resources, big data, or new media. It seems that thanks to its extension and intension, the concept of document may readily include media that will be involved in the communication environment in the future.
1.3 Methodology of Conceptual Analysis and Conceptual Modeling
In the above-mentioned review study (Kučerová 2021), we divided document theories by their prevailing methods into theories using the method of categorization, the method based on specification of properties, and the method of specification of aspects. We will now add the method of modeling to the three generally used methods. We have dealt with the issue of conceptual modeling in detail in our paper (Kučerová 2018), here we will only give a brief summary.
A model is a deliberately created representation of an object or phenomenon or event (the so-called original) having correspondence to the same in essential properties. A conceptual model is a type of model with a purpose of semantic representation of the original through concepts and their relationships. A distinction is made between subjective (mental) conceptual models created during human thinking and objective conceptual models in which concepts are explicitly expressed in a formal semiotic system. Objective conceptual models are usually expressed textually (e.g. in the form of classification schemas, thesauri, metadata schemas, ontologies) or graphically (e.g. using semantic networks, entity and relationship diagrams, or class diagrams), or a combination of textual and graphical notation. A conceptual reference model is a conceptual model at the highest level of abstraction, which expresses a consensus on the meaning of basic concepts in a domain, thus enabling communication within that subject area. It provides a general framework and conceptual basis for the creation of specific (e.g., domain, implementation, technology or data) models, standards, or application profiles.
Conceptual analysis is such an analysis of a phenomenon under examination resulting in a representation of the reality analysed by means of concepts. Anything can become the subject of analysis, including concepts. Models that are an outcome and a tool of knowledge of a phenomenon can also become an independent source of knowledge and can therefore be subjected to conceptual analysis. This is also the case of our study, in which the concepts included in social communication models are analysed and interpreted. From the wide range of possibilities of using models in research (knowledge of the original, design or creation of the original, influencing the original, experiments, hypothesis testing, etc.), we will choose a conceptual analysis of selected models, which will be directed to the selection of concepts applicable in the creation of a document model. This corresponds to the choice of the models analysed: all three models can be categorized as reference models, whose function is, among other things, to serve as a source for the creation of specific domain models. We will divide the procedure into three steps: 1) we will determine the criteria of the analysis using a systematic approach, 2) we will search for terms corresponding to the set criteria in the models of social communication, and 3) we will design our own conceptual document model using the concepts obtained by the analysis of social communication models.
To design the conceptual model, we will use the form of a class diagram in the unified modeling language (UML). In this diagram, concepts are represented through classes, in which elements having the same properties are grouped. Classes are connected by three types of semantic relationships: the relationship of association represents a semantic connection, a relationship of partitive hierarchy connects the whole and its parts, and a relationship of generic hierarchy connects a class-type with its subtypes. This type of relationship is based on common characteristics – the "child" class at the lower level shares characteristics with the "parent" class at the higher level, and usually differs from the latter by its specific characteristics. The generic relationship hierarchy allows transitivity or transfer of properties, which means that a property once defined at a parent level becomes a property of all entities at child levels. In the opposite direction, it is an abstraction – towards the superordinate level, the individual characteristics of the subordinate entities are omitted, leaving only those that are common to the whole group. This achieves an effective capture of the modeled phenomena without duplication and redundancy, thereby a significant simplification of the model.
2 Analysing Models of Communication
The first part of this chapter defines some criteria of the analysis, the second part describes the selected models, and the third part presents the result of their conceptual analysis.
2.1 Criteria for Analysis: A Systematic Approach to Document Definition
In this part, we will set out the criteria for conceptual analysis of the selected social models of communication. We will not be interested in how successfully a model represents social communication in the analysis, but in what parts of the model can be used for theoretical reasoning about document. Therefore, we will focus on the criteria applicable to defining a document.
Given the different ways of defining a document, it will first be necessary to decide what type of document definition we aim for. In addition to the classical Aristotelian definition through the determination of the nearest genus and specific differences, alternative types of definitions can also be commonly encountered in the professional environment. Enumerative definitions, or definitions by listing elements represented by a concept, occur in practice in the form of numerous lists of document types. Descriptive definitions in the form of a list of properties of defined entities are well known in the library environment; bibliographic description rules explicitly specify which properties of a document are to be described, i.e., populated with values during the cataloguing process. Metaphors and metonymy are another popular tool for defining a document, detailing a defined object in the form of analogy (a document as... sign, function, medium, thing, etc.). In all these cases, however, the integration of the entity defined into the context is missing, and metaphorical definitions also lack a definition of specific properties.
In the conceptual analysis of communication models, we will focus on those components that would allow us to reach a definition of a document that meets the requirements of the classical Aristotelian definition. We will try to capture the specific differences and the context in which documents are incorporated in social communication as fully as possible using a systematic approach.
The Table 1 below summarizes the basic categories for the definition of document, which we will use as criteria in the conceptual analysis of communication models. The categories are grouped into three basic facets that cover 1) the document as a whole, 2) the components (structure) of the document, and 3) the properties of the document.
| 1. What is a document? |
Objectively (what it „really“ is) – gist, essence, substance | |
| Subjectively (as a subject perceives it) | ||
| 2. What components make up a document (structure)? | Document elements | |
| Relationship of elements in a document | ||
| 3) What are the properties of a document? | Purpose | transmision of content in space |
| transmission of content in time | ||
| access to content, content sharing | ||
| Function i.e.what (what processes) | can be done with a document | |
| can a document "do" | ||
| Attributes | of a document's content | |
| forms of a document's content | ||
| of material carrier | ||
| Relationship, i.e. context | cognitive context | |
| ontological context | ||
Tab. 1 Facets following document definition
The content of the first facet shows that it is possible to note two different options for document definition already at the basic level of understanding of a document as a system, where we perceive it holistically as a whole defined in relation to its surroundings. The objective method is based on the Aristotelian idea that it is possible to reveal the truly existing gist, substance, or essence, of a phenomenon subject to examination. The subjective method specifies a document by how it appears to an observer. This phenomenological method[1] of knowing the world through what a subject perceives and feels is concretized in the context of digital products and services as user experience. The question of which of these methods to prefer is becoming more relevant for a digital document: is its essence what the user perceives and experiences, for example, through a computer display in the form of an individually customizable user interface, or is it some digital objects, data, and programs that physically constitute it, or merely some algorithms that make it possible to create it?
The second and third facets include categories that are the result of a systemic analysis of the document. In accordance with the systematic approach, we will consider its purpose to be the most important of the document’s characteristics listed in these facets, which we will establish axiomatically as facilitating any type of indirect communication of content.
The classic system analysis procedure distinguishes between structure and function. A structural definition of document views a document as a thing (see Buckland, 2017, p. 22); it establishes what a document is, what elements (component parts) it is composed of, and what their relationships are. A functional definition views a document as a process or as an event in its life cycle. We then define the functions of the document as processes that make it possible to achieve the specified purpose. They are divided into two groups: processes or events influencing the document (what can be done with the document) and processes by which the document influences its users (what the document "does").
For the purposes of this study, we will add another dimension of analysis specific (not only) to documents – the division into content and form.[1] Such a division is based on the Platonic distinction between the material and the ideal represented by pairs of various names: matter and consciousness, soul and body, denoting and being denoted as a form and a meaning of the sign in Saussure's concept, work and expression in the IFLA LRM model, etc. Just as structure and function form a unity in reality, content and form are inextricably linked to each other. However, within the framework of system analysis, which is a logical analysis, it is possible to treat them separately and focus on specific cases of their interaction.
A content definition of document focuses on the meaning conveyed by the document (subject, topic, aboutness of the message). Form is commonly understood as the external arrangement ("appearance") of content. However, the internal components of content can also be arranged – in this aspect, form is getting closer to the concept of structure. While content is definitely abstract, form can be divided into two types – the abstract content form expressing (encoding) a message (e.g., image, motion, sound) and the concrete form or material carrier, which is a concrete physical object, on which or by which the abstract content and form are recorded, transmitted, or shared (e.g., paper, electromagnetic waves). It can be stated that content and content form defined in this matter make up the structure of the message, and the material carrier forms the infrastructure for its communication. The starting point for the categorization of document attributes will therefore be a triadic division of the document into content, content form, and material carrier.
We will examine the relationships of the document to related entities on two levels. A cognitive (gnosiological, epistemological) level allows us to define the relationship of the concept of document to the important concepts, with which it is semantically related (e.g., an information resource, a medium). An ontological context consists of the environment, in which the document exists, such as information environment (infosphere), social communication system, bibliographic universe, library, corporate information system.
2.2 Characteristics of Models
In this section, we will concentrate on how social communication is portrayed by its models. Social communication is an intensively researched area and a considerable number of models have already been created in this research. The models we considered for the analysis include the Semantic Web model[1], the Open Document Architecture (ODA) model (ISO 8613), or the popular Laswell model of social communication ("Who says what to whom and with what effect?"), the CIDOC Conceptual Reference Model of cultural heritage information, the reference model of the Open Archival Information System (OAIS), or the abstract model for Dublin Core Metadata Initiative (DCMI) Abstract model.
For our study, we have chosen two models of social communication that we deem most significant, developed in the mid-20th century and widely accepted and discussed outside the disciplines within which they were originally created: the Shannon-Weaver general model of communication and the Jakobson linguistic model of communication. For our needs, it is relevant that neither was created empirically, but both were derived from scientific theories. They are therefore supported by highly abstract scientific disciplines (mathematical information theory, linguistics and semiotics), which allows their applicability even in the current communication environment, which is dramatically different from the communication environment at the time of their creation.
The third selected model is the IFLA LRM reference conceptual model of bibliographic information with roots in the 1990s. Its core is a generalization of historically accumulated experience with the description of documents in the domain of memory, collection-holding and cultural institutions. It has contributed to the development of the bibliographic information theory by its multifaceted view of the document through the entities work, expression, manifestation, and item, which offers a way of resolving the document’s content-form relationship. The specificity of the model lies in its focus on the meta-level of information about these entities, metadata, rather than the "primary" entities participating in the communication process. Although it is not directly related to any of the theoretical scientific disciplines, the IFLA LRM model is currently accepted as the most important model in information science and widely applied in practice.
Each of the selected models focuses on a certain part or an aspect of social communication. The discourse universe of the Shannon-Weaver model is based on the technical aspects of communication, it is optimized for long-distance communication using technical means. Jakobson is interested in direct linguistic communication, in which he emphasizes the poetic function of language. The IFLA LRM model covers the so-called bibliographic universe[1] and focuses on communication in time, which is indirect in nature and mediated by communication media.
Nevertheless, these specifics of the individual models, which make it impossible to unify them directly, can also be seen as an advantage, allowing the application of the principle of complementarity proposed for document definition by the neo-documentalist school (see Lund 2004). Again, the aim of this study is not to evaluate the selected models, but to use the results of their analysis to construct a working document model.
2.2.1 Shannon-Weaver Model of a General Communication System
Figure 2 shows a model of a general communication system as it was presented in 1949 by its authors – American mathematicians and computer science pioneers Claude Elwood Shannon (1916–2001) and Warren Weaver (1894–1978). They developed the diagram as an illustrative aid to understand the essence of Shannon's mathematical theory of communication, which, in addition to the entities mentioned in the model, includes the commonly used concepts of information, entropy and redundancy (Shannon and Weaver 1949).

Fig. 2 Model of a general communication system (Source: Shannon and Weaver, 1949, p. 98)
The model consists of the following components and the processes implemented by them: Information source selects a message to be communicated from a set of available information.[1] According to Shannon and Weaver, the content (semantics) of a message is a matter of the context, in which the information source is located. However, this context is not shown in the diagram. A transmitter encodes a message so that it can be communicated over a transmission channel in the form of a signal. The channel (shown by a blank square in Figure 2) is a noise source and the reason why the signal received usually differs from the signal transmitted. A receiver decodes the received signal and forwards the message to a destination.
Of the three levels of communication named by the authors according to the problems solved as the level of technology, semantics and efficiency (i.e., pragmatics), the model presents the technical level only. Nevertheless, the authors indicate in the introductory remarks the ambition to capture with their model a truly general problem of communication at a machine level, and of human, social communication.
"The word communication will be used here in a very broad sense to include all of the procedures by which one mind may affect another. This, of course, involves not only written and oral speech, but also music, the pictorial arts, the theatre, the ballet, and in fact all human behavior. In some connections it maybe desirable to use a still broader definition of communication, namely, one which would include the procedures by means of which one mechanism (say automatic equipment to track an airplane and to compute its probable future positions) affects another mechanism (say a guided missile chasing this airplane). " (Shannon and Weaver, 1949, p. 95)
The aim of communication so defined is therefore not a mere passive transmission of a message, but "influence", i.e., a change in the behaviour of the recipient caused by the message. This corresponds to the generally accepted idea of two interconnected aspects of a document – a document as a report on reality and a document as a process of influencing reality.
2.2.2 Jakobson's Linguistic Model of Communication
The linguist Roman Jakobson (1896–1982) was one of the founders of the Prague Linguistic Circle and is one of the most prominent representatives of functional structuralism. The following statement can be considered a manifesto of Jakobson's systematic approach to language:
"There is no doubt that for every linguistic community, for every speaker, there is a unity of language, but this all-encompassing code is a system of interrelated subcodes; Every language contains several parallel structures, and each of them is characterized by a different function." (Jakobson, 1995, p. 77)
In his model of constitutive factors of a speech event (the act of verbal communication) and the associated functions of language, Jakobson combines Shannon's cybernetic approach with the semiotic approach of the Austrian psychologist Karl Bühler (1879–1963). Bühler defines three functions of the linguistic sign: in relation to objects and states of things, the representational function is manifested (German. Darstellung), in relation to the sender of the message, the sign has an expressive function (German. Ausdruck), and in relation to the recipient of the message, an appeal (challenge) function (German. Appell). (Bühler 1934) In his lecture Linguistics and Poetics at the 1958 Style in Language conference, first published in a revised version in 1960 (Jakobson 1960), Jakobson arrived at six key factors in language communication. He characterises them as follows:
"The ADDRESSER sends a MESSAGE to the ADDRESSEE. To be operative, the message requires a CONTEXT referred to ('referent' in another, somewhat ambiguous nomenclature), seizable by the addressee, and either verbal or capable of being verbalized; a CODE, fully, or at least partially, common to the addresser and the addressee (or in other words, to the coder and decoder of the message); and, finally, CONTACT, a physical channel and psychological connection between the addresser and the addressee, enabling both of them to enter and stay in communication." (quoted by Jakobson, 1995, p. 77)
Figure 3 shows that each of these structural elements is assigned a corresponding function of language. According to Jakobson, at least one function of language is manifested in each speech event, usually there are several, and usually one of them dominates.
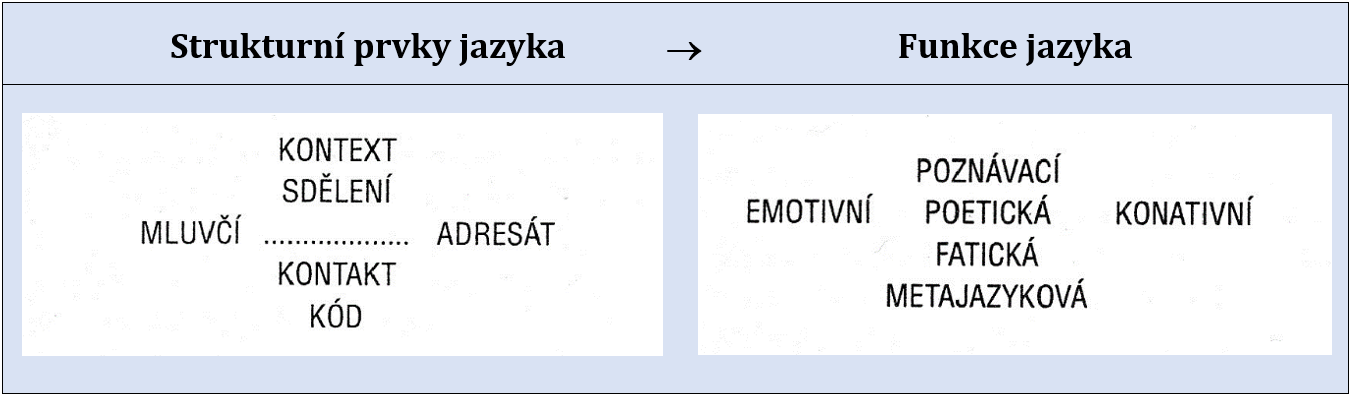
Fig. 3 Linguistic Model of Communication (Source: Jakobson, 1995, pp. 78, 82)
The addresser is associated with an emotive function, which roughly corresponds to Bühler's expressive function. Its task is to express the speaker's state, attitude or emotions related to communication, for example by means of interjections. The term context already occurs in the Shannon-Weaver model, and is also analogous to what Bühler refers to as "objects and states of things." Jakobson assigned it a cognitive function of language, for which it also uses semiotic terms referential and denotative. Jakobson assigned the addressee a conative function, which is similar to the appellative function in the Bühler's model and affects the addressee, typically through performative speech acts (e.g., orders, incantations, or curses). As in the Shannon-Weaver model, this model also reflects the dual role of communication – to predicate something through the cognitive function and to influence something through the conative function.
The message is Jakobson's interpretation of Saussure's concept of parole (utterance); in his model, he assigned it a self-referential poetic function that seeks the meaning of the message in itself. "The set (Einstellung) toward the message as such, the focus on the message for its own sake, is the poetic function of language." (quoted by Jakobson, 1995, p. 81)
In the model, the term contact refers to the transmission channel, which is a technical condition for communication. It is associated with a phatic function that informs the speaker and the recipient that communication is actually taking place. This enriches the idea of communication with the concept of interaction and feedback. Code is a term taken from cybernetics and in Jakobson's conception it is an interpretation of Saussure's concept of langue (system of language). A metalingual function that corresponds to it in the model ensures the encoding and decoding of the message communicated.
2.2.3 IFLA LRM Conceptual Model of Bibliographic Information
The IFLA Library Reference Model (IFLA LRM) was developed by the International Federation of Library Associations and Institutions (IFLA) and was adopted as an IFLA standard in 2017. It takes the form of an entity-relational model that consolidates the three previous models of bibliographic records (FRBR – Functional requirements for bibliographic records), name authorities (FRAD – Functional requirements for authority data) and subject authority (FRSAD – Functional requirements for subject authority data). Figure 4 shows all 11 model entities and their most important relationships, as presented in the English edition of the standard.
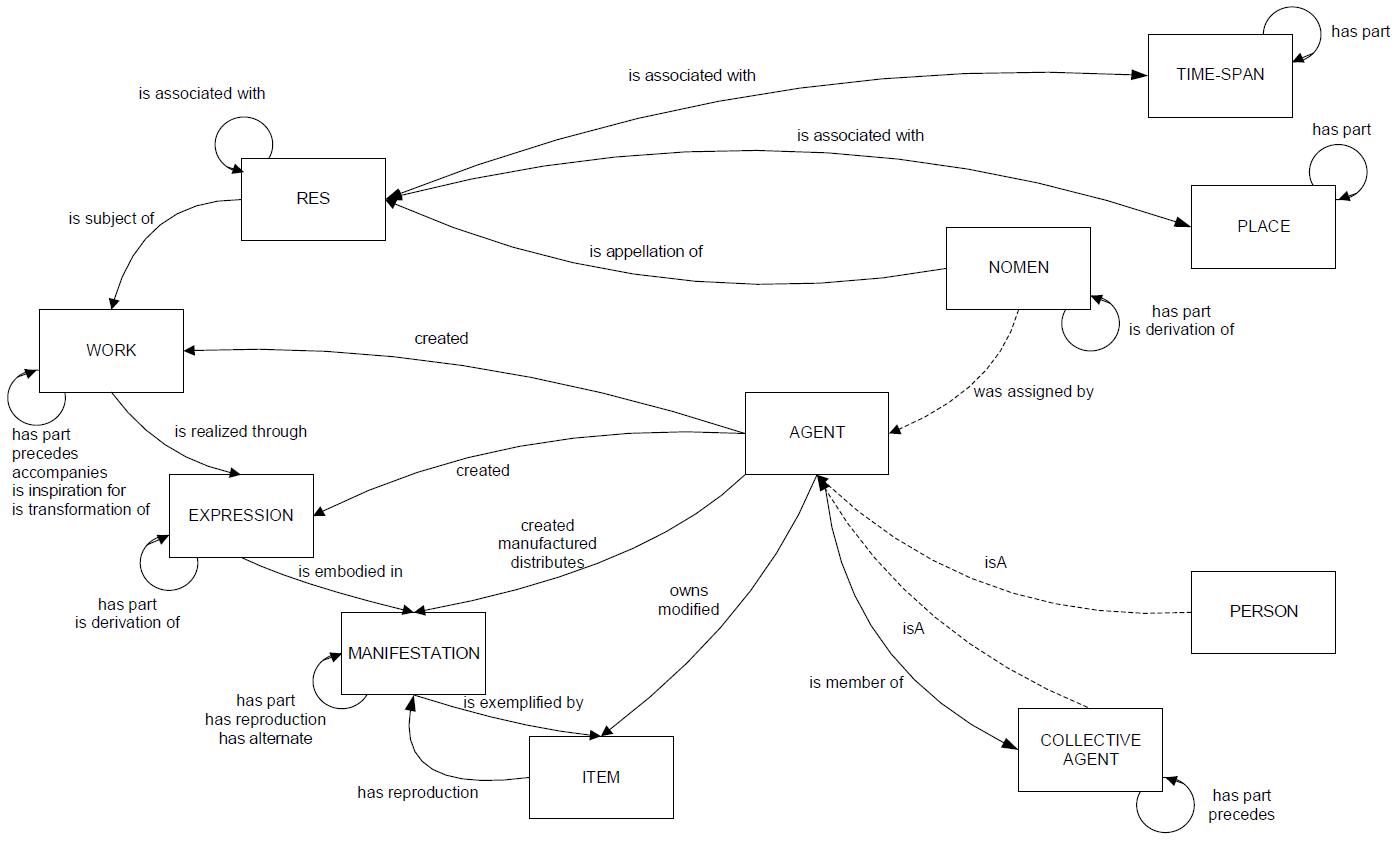
Fig. 4 IFLA LRM (Source: IFLA, 2017, p. 86. Available at: https://repository.ifla.org/handle/123456789/40)
There is a generic relationship hierarchy applied in the model. Only some of the relationships are shown in Figure 4 and therefore we present their structure (the so-called backbone taxonomy) for illustration in the UML notation in Figure 5. In addition to the generic relationship hierarchy, Figure 5 also shows selected associative relationships, which are mentioned in the model’s description below.
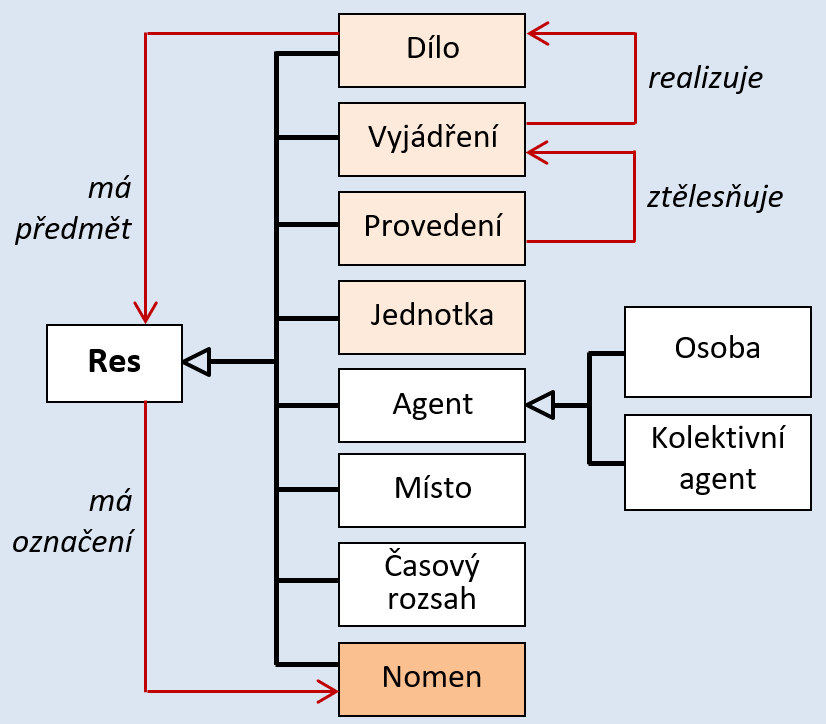
Fig. 5 IFLA LRM backbone taxonomy
The entity res (from the Latin word for thing, LRM-E1) is at the top level of the hierarchy, comprising all entities within the universe of discourse. It fulfils a dual role: 1) it generalizes the characteristics of the entities in the model, and 2) it allows the content (subject, theme, aboutness) of a document to be expressed through the relationship of association between the instances of the entity work and res (res is subject of work / work has as subject res, LRM-R12). This addresses the relationship between a document and its content in the model.
The entity nomen (from the Latin word for name, LRM-E9) has a specific semiotic purpose in the model: it makes it possible to clearly distinguish a thing described from its designation. The relation of appellation (LRM-R13) can associate the entity nomen with any other entity, and since a relationship is defined with one-to-many cardinality, each entity can have multiple appellations.
The entity agent (LRM-E6) with subclasses person (LRM-E7) and collective agent (LRM-E8) generalizes all individual and group entities that can have any intentional relationship to bibliographic entities.
The core of the model comprises four disjoint bibliographic entities: work (LRM-E2), expression (LRM-E3), manifestation (LRM-E4), and item (LRM-E5). Each entity shows a different view of a document. A work represents the content dimension of a document, the expression represents the form of the content, and manifestation and item are entities oriented towards the dimension of a material carrier.
The model’s entity work represents the "intellectual or artistic content of a distinct creation". The adjectives "intellectual" and "artistic" convey an effort to add an artistic, cultural, emotional dimension to the understanding of the content (which Roman Jakobson would probably identify as the poetic function). Expression is defined as " intellectual or artistic content of a distinct creation". The authors of the model emphasize that they use the term "sign" in the meaning used in semiotics, i.e., as something representing something else; specifically, an expression represents a work for the user. Manifestation is understood in the model as "a set of all carriers that are assumed to share the same characteristics as to intellectual or artistic content and aspects of physical form. That set is defined by both the overall content and the production plan for its carrier or carriers". An item is an entity representing "an object or objects carrying signs intended to convey intellectual or artistic content".
The IFLA LRM model accentuates the interlinkage and interdependence of content and form of documents, with their abstract representation divided into four entities in the model, but which in fact form a whole (the content is perceived through form). The unity of content and form is modeled in several ways: by means of the relationship of the entities res and nomen linking the designated content and the designating form, by means of the relationships of realization and embodiment, and by means of a representative expression attribute.
The associative relationships of realization (work is realized through expression, LRM-R2) and embodiment (expression is embodied in manifestation, LRM-R3) interconnecting the entities work, expression, and performance, express their close connection in terms of time. "A work comes into existence simultaneously with the creation of its first expression" (IFLA, 2017, p. 21) The same applies to expression that "comes into existence simultaneously with the creation of its first manifestation" (IFLA, 2017, p. 23). In other words, "no work can exist without there being (or there having been at some point in the past) at least one expression of the work" (IFLA, 2017, p. 21) and " no expression can exist without there being (or there having been at some point in the past) at least one manifestation" (IFLA, 2017, p. 23).
A representative expression attribute (LRM-E2-A2) enables to choose from various expressions of the same work, which will be considered representational or canonical, and to incorporate its formal attributes (for example, the language in which the work was written by its author) directly into the characteristics of the work. This construction consequentially disrupts the declared disjoint relationship of entities and leads to their overlapping. The authors of the model justify this solution by the fact that even though a work is defined as content, users often identify it by its formal properties.
Unlike the two models described in the previous sections, which mention the context related to the content of the message without further specifying it, the IFLA LRM models its structure through entities place (LRM-E10) and time-span (LRM-E11), which generalize all spatial and temporal characteristics of entities in the bibliographic universe.
2.3 Conceptual Analysis of Models of Communication
This section presents concepts that have been derived from the models presented in section 2.2. The aim of the analysis is not to complete the description of the models, for the purposes of the study we selected only those concepts that we consider relevant in terms of defining the concept of document.
Although all models of communication use their own terminology, their common features are evident at the conceptual level. We tried to capture them in Table 2, in the rows of which we placed the concepts corresponding to each other. In the introductory group, concepts representing "active" human or technological elements of the communication process are presented. The following are some concepts that we have grouped together in accordance with the document definition criteria set out in Section 2.1 based on whether they refer to the content dimension of a document, the form dimension of content, or the material dimension. For IFLA LRM, some concepts are supplemented with statements that characterize their mutual relationships.
| Shannon Weaver model | Jakobson's model | IFLA LRM | |||
|---|---|---|---|---|---|
| Information source | Addresser | Emotive function | Agent | ||
| Transmitter (encodes) | |||||
| Destination | Addressee | Connative function | |||
| Reciever (decodes) | |||||
| Message | Message | Poetic function | Work | Work is the content of a creation | content |
| Context | Cognitive function | Res | Work has subject res | ||
| Time-span | Res has temporal and spatial characteristics | ||||
| Place | |||||
| Signal | Code | Metalingual function | Expression |
Expression realizes Work Expression is a (semiotic) sign Res has appellation Nomen |
content form |
| Channel | Contact | Phatic function | Manifestation |
Manifestation embodies Expression Item exemplifies Manifestation Manifestation is a carrier of (encoded) content |
material carrier |
Tab. 2 Comparison of concepts from individual models
Of course, the comparison is based on similarity rather than equivalence; it certainly cannot be claimed that the concepts listed in one row correspond to one another fully. For example, Jakobson defines his contact not only as involving a Shannonian "physical channel", but also a "psychological connection" between the addressor and the addressee; a work from the IFLA LRM model certainly cannot be identified exclusively with the poetic function of a message conveyed through language.
For the purpose of constructing our own document model, we then synthesized the semantically corresponding concepts from the individual models. We have divided the concepts into two groups: the first includes abstract concepts (classes, so-called universals) that do not have temporal or spatial characteristics, the second includes terms that denote concrete concepts representing physical objects that exist in time and space (so-called particulars). The result comprises the seven concepts listed in Table 3.
| Abstract concepts (universals) | Concrete concepts (particulars) | |
|---|---|---|
| Content | ||
| Medium | Content form | |
| Context | ||
| Material carrier | ||
| Information source | Document | |
Tab. 3 Conceptual apparatus for creating custom document model
In order to be able to use these concepts for the construction of the document conceptual model, it is necessary to specify their meanings and mutual relations. The characteristics listed below are prepared exclusively for this purpose and are not claimed to be of general application.
In the case of the concept of content, we will stick to an intuitive understanding of its meaning, which in our model will represent what is being communicated. It corresponds to the concepts that are grouped in the category of "content" in Table 2: message in the Shannon-Weaver model, message and context in the Jakobson model, entity work together with the contextual entities res, time span and place in the IFLA LRM model.
We have chosen the abstract concept of medium as an umbrella for the concepts of signal, transmitter and receiver from the Shannon-Weaver model, code in the Jakobson model, and the entities expression, manifestation and item in the IFLA LRM model. The concept of medium is hierarchically divided into three types: abstract content form and abstract context (see the concepts of the same name in the Shannon-Weaver and Jakobson models and the concepts of time-span and place in the IFLA LRM model) and concrete material medium including the channel from the Shannon-Weaver model, contact from the Jakobson model, and manifestation and item from the IFLA LRM model.
The usual meaning given to the concept of medium is based on its etymology: something in between, in the middle, that is, a medium or an environment. In the case of communication, the medium is located between the source and the recipient of the message and enables so-called indirect communication, based not on direct contact, but on the content mediated by the medium. Together with Richard Müller and his co-authors, we will understand the medium as any means enabling the communication of content in the dialectical unity of the means and the environment (context): "It turns out that at the most general level, we can ultimately distinguish between two hardly compatible meanings of the concept of medium, which we can aptly describe as instrumental and environmental – answering the questions With what? In what?" (Müller and Chudý, 2020, p. 568) Our working definition of the concept of medium will therefore include both the material infrastructure of communication and its context, and the form that allows the content of the message to be expressed.
In accordance with the prevailing terminology, we designate a whole that is created by combining the content communicated and the medium as an information source. We therefore understand the concept of an information source as an abstract expression of the unity of content and form. The dialectical unity of the semantics of a message and its communication format is, of course, also a characteristic feature of the concept of information, which in this sense forms a pillar of the conceptual apparatus of information science. Again, the question arises whether it would not be more appropriate to denote such an abstract concept as information. In this matter, we will accept the opinion of Patrick Wilson, who, in his essay on the subject of bibliographic control, came to the conclusion that what is "controlled", or processed bibliographically, is not information as such, but an entity that he refers to as text that can (yet does not have to) be used as a source of information. He argues that the meaning that an information source acquires for the user cannot be identified with the explicit meaning of the individual statements from which it is created. "What a text says is not necessarily what it reveals or what it allows us to conclude." (Wilson, 1968, p. 18)
The specific term document, derived from the term information source, roughly corresponds to the entity of manifestation from the IFLA LRM model. We will try to define its characteristics using our own model in the following section.
To create our own document model, we have chosen the form of a class diagram in UML language in notation according to the ISO 24156-1 (2014) standard, which regulates the use of UML in terminological work. The structure of the model consists of classes represented by a rectangle to represent concepts, and lines or arrows to represent their relationships to each other. A relationship of association is represented by a simple line, in the case of an asymmetric relationship by a line ending with an arrow. A generic hierarchical relationship is depicted by means of an arrow ending in a triangle pointing from a child class to a parent class. A partitive hierarchy is represented by an arrow ending in a diamond, which points from class-part to class-whole.
To make it easier to navigate the model, we have divided it into two parts, which are connected by the classes of document and metadata. The first part expresses the relationship of the document to other concepts, the second part of the model focuses on the granularity of documents and their typology.
3.1 Document and Its Context
The diagram in Figure 6 is divided into two levels, separated by a dotted line, in accordance with the nature of the concepts covered. In the upper part, there are abstract concepts represented by abstract classes that have no concrete instances (or their instances are concrete classes), and in the lower part there are concrete concepts (see Table 5 in Section 2.3).
Fig. 6 Relationship between document – medium – information source
The most general classes in the hierarchy indicated by the diagram are content and medium. In accordance with the working definitions we have formulated in section 2.3, we consider content to be what is communicated, and medium to be what, how, and where is communicated.
In our model, the medium class serves for a logical (and, as already mentioned, impracticable) separation of content and form of communication. The three aspects, or specific types of media, are represented by the abstract classes form, content and context, and the concrete class material carrier.
In our model, the class information source is also understood as an abstract class that has no physical instances. In the diagram, it is shown as a whole consisting of two components –content and content form, which is a specific type of medium. The relationship of association that connects the classes information source and context expresses the influence that the environment, in which it exists, has on the information resource.
In addition to the classes representing concepts derived from communication models, an abstract class metadata is added in our model. Its inclusion is motivated by the nature of the IFLA LRM model, which is also sometimes referred to as a conceptual model of bibliographic metadata. The relationship between information source and metadata is of two types. On the one hand, metadata is a specific type of information source, which is represented by the symbol of the family hierarchy, and on the other hand, it is linked to the information source by an association relationship. The associative relationship of metadata to an information source can have various semantics, the most common being the following types of relationships: 1) metadata represents a property of an information source (e.g., title, language, date of creation), and 2) metadata enables to perform operations on information sources (e.g., identify, find or select a relevant resource).
The concept of document is modeled as a specific type of information source. The generic hierarchical relationship, which connects it to the information source, allows all the properties and relationships of an information source to be transferred to the class document by inheritance. Like an information source, a document is therefore a unity of content and content form and is influenced by context. In addition, it is connected by the relationship of the partitive hierarchy with a material carrier. A document is a whole, a material carrier forms its integral part. A material carrier as such is the physical concretization of what applies to its generic concept of medium on an abstract level.
3.2 Document and Its Granularity (Macro- and Microstructures)
The diagram in Figure 7 intends to show a document no longer in relation to related concepts, but through the relationships of the whole-part hierarchy in order to present the generalized way of its (micro)structuring and incorporation of documents into larger (macro)structures. In addition, two important types of documents are added to the model – collections and data. All the concepts mentioned in this diagram are concrete, and it is assumed that they are anchored in time and space and that physical instances exist. This is also the case of the class called metadata element, which is a specification of the abstract metadata class from the previous diagram in Figure 6.
Fig. 7 Granularity of documents
The document class has two different partitive relationships represented in the diagram. The first relationship component part links a document as a whole to the class document element that represents its part. A document element can be any component smaller than the document itself and simultaneously larger than its basic building block (e.g. bit, pixel). According ISO 690 (2021, 3.7), a component part of a document is an "entity provided by a creator to form part of a host document" (for example, a name index in a book). A highly abstract and formally sophisticated system for defining document component parts is contained in the ISO/IEC 8613 standard for open document architecture . It distinguishes between the content elements, which make up the architecture of the document's content, and the elements of the document's form, distinguishing between logical and visual (layout) elements. Today, markup languages (e.g., HTML) are most commonly used to define elements of digital documents. The existence of elements in a document leads to the creation of partial relatively independent microstructures of the document, which is also perceived as a separate and integral unit of content.
The second partitive relationship of the document in our diagram is a recursive relationship called aggregates. We understand this relationship in the same way as in the IFLA LRM model, in which an aggregate is defined as a manifestation embodying multiple expressions (IFLA, 2017, p. 93). An aggregated manifestation includes (embodies) either multiple expressions of different works (e.g., in an anthology or proceedings) or multiple different expressions of the same work (e.g. in a multilingual edition). Such a division leads to the formation of macrostructures, in which it is possible to recognize several different separate units of content.
The aim of our model was not to create a comprehensive typology of documents. However, we consider it useful to display two important types of documents in the model – collections and data, and to clarify their relationship to the concept of document. A collection is a set of organized, discrete documents. In the IFLA LRM terminology, it is a set of items for which various designations are used in practice, e.g., collection, stock, set, corpus, database, repository. In the ISO 690 (2021, 3.6) standard, it is defined as " any set of one or more information resources, assembled on the basis of some common characteristic, for some purpose, or as the result of some process". Despite the intuitive notion of a collection as a whole and documents as its parts, the relationship between a document and a collection is not defined in our model as an aggregation relationship (a collection is not an aggregate), but as an association relationship — a document is placed in a collection. At the same time, as Jonathan Furner (2016, pp. 299–303) and Michael Buckland (2017, pp. 48–49) have made clear, a collection can be viewed as a document. This fact is expressed in the diagram by the generic relationship of the hierarchy between the mentioned classes – a collection is a specific type of document. Thus, the document-collection relationship is another case of indirect recursion in our model.
The concept of data is currently very frequently used, and because the volume of data communication in society grows constantly, it is sometimes perceived as an equivalent to the concept of document. A relatively widespread idea is again the intuitive idea of a document as a whole composed of data. In our model, however, data is understood as a specific type of document, i.e., content, form and material carrier are attributed to data. The class dataset in our model presents a specific type of collection in which a set of organized data is located. A metadata element is a specific type of data that has a form shared with data. At the same time, a metadata element is a specific type of metadata, to which it is also linked by a generic hierarchy relationship. Thanks to this polyhierarchy, it is possible for metadata elements to share general data properties and simultaneously an association relationship of metadata with information sources or documents.
3.3 Verification of Model’s Applicability
A modeling method usually includes a phase of testing a model being designed. In addition to logical accuracy, the applicability of the model for a practical purpose for which it was created is also verified. In the case of our working document model, we decided to corroborate whether it allows to represent specific categories of documents currently used in the cataloguing practice of libraries. For such testing, typologies contained in the controlled vocabularies of two international standards for document description – ISBD (International Standard Bibliographic Description) and RDA (Resources Description and Access) – were used, which are conceptually based on the IFLA LRM model.
When designing a typology in a class diagram (i.e., a list of subclasses of a class), it is important to clearly define a criterion of division, most often based on a suitable attribute of a class under segmentation. Because a class can have more such attributes, it is also possible to create multiple typologies for one class. A technical solution then consists in adding attributes to the appropriate classes in the model; for these attributes, it is then possible to develop value vocabularies to denote specific types. To test our model, we have chosen document typologies based on their formal attributes. These are represented in the model by the abstract class Content Form and the concrete class Material Carrier.
In the two commonly applied classification criteria for categorizing the forms of content, it is possible to distinguish an objective and a subjective method of document definition, which we have characterized in Section 2.1: objective categorization is based on the type of signs that express content (e.g., data set, text), subjective categorization is focused on human senses by which signs are perceived (hearing, taste, smell, touch, vision). Specific document typologies based on the semiotic systems used to express content include the ISBD content form value vocabulary and the RDA content type value vocabulary . The typology of documents according to the human senses for content perception is available in the value vocabulary for ISBD content qualification of sensory specification .
Various criteria can also be used for the typology of material carriers. In addition to the usual "objective" typology of materials and objects that form the physical basis of medium (e.g., audio cassette, microfiche, volume), it is also possible to encounter a typology of means or devices, through which the content on a medium is accessible to the user (e.g., a computer, microscope). A division according to type of recording capturing the dichotomy of analogue and digital documents is important.
The existing typology of documents according to their carriers is contained in RDA carrier type value vocabulary . Document typology according to the devices needed to access their content is provided by ISBD media type value vocabulary and RDA media type value vocabulary . Capturing the division into analogue and digital documents is enabled by the RDA type of recording value vocabulary . Table 4 shows how to solve the representation of document types in the model. The second column of the content form and tangible medium classes is supplemented with the relevant attributes expressing the breakdown criterion, and the third column contains examples of real controlled vocabularies, the values of which can be used to fill in the attributes.
| Model class | Attribute | Value vocabulary for attributes |
|---|---|---|
| content form |
Signs for content expression |
ISBD content form RDA content type |
| Human senses for content perception |
Content qualification of the ISBD sensory specification |
|
| Material carrier | Carrier | RDA carrier type |
| Device |
ISBD medium type RDA medium type |
|
| Recording method |
RDA type of recording |
Table 4 Typology of forms, contents and material carriers
Of course, the testing carried out cannot be considered exhaustive, but for this small sample, it has confirmed that the designed document model is compatible with the tools for description and typology of documents based on their format, which are common in practice.
4. Summary: Towards a Functional Definition of Document
The document model presented in this study is static, focusing exclusively on the elements and their mutual relationships. The next step towards a systematic view of the document must therefore be to define the functions and assign them to the appropriate model components. The statement addressed to media can apparently be applied to the document: "Consideration of processes [...] would then open the way to the most general description of mediality as something shared by all media [...] Therefore, capturing operations or processes related to media is crucial." (Müller and Chudý, 2020, p. 570) We believe that the functions defined in these models could serve as a basis for conceptual analysis and subsequent transformation of the existing models, in the same way as a static model of a document may be derived from analysing models of communication. A preliminary overview of potentially relevant functions is provided in Table 5.
| Shannon-Weaver model | Jacobson's model | Model IFLA LRM |
|---|---|---|
|
Select message Encode message Transmit signal Decode signal Noise (content distortion) |
Emotive function Connative function Poetic function Cognitive function Metalingual function Phatic function |
Find document Identify document Select document Obtain document Explore, discover document |
Table 5 Document functions in communication models
So far, the overview of functions has taken the form of simple lists, the designation of individual functions is taken verbatim from individual models, and no steps have been taken to compare them. This will require a thorough analysis. It is evident that each set of functions aims at a different dimension of a document: In the Shannon-Weaver model, the functions focus on the communication process itself, the Jakobson model captures the effect that a message communicated has on its recipient, and the IFLA LRM model prescriptively postulates functions that metadata is supposed to fulfil in relation to a document. The model is limited to bibliographic metadata functions corresponding to the requirements of end users and does not include any functions associated with administrative, management or copyright-related work of libraries.
Perhaps a pair of bibliographic control tasks as described by Patrick Wilson could be a unifying platform for looking at these variously defined functions– to describe and to use a document (Wilson, 1968, p. 20), in combination with the three functions of media defined by the media theorist Friedrich Kittler as transmission, preservation and processing of information (Kittler, 1993, p. 8). Further initiatives could be expected from the theory of document acts (Smith, 2012).
Conclusion
This study has aimed to verify the applicability of conceptual analysis of reference models of social communication to the construction of a conceptual document model. That objective has been met by demonstrating that the communication models chosen provide a relevant conceptual basis applicable to that purpose. In addition to the concepts derived from the models using the method of conceptual analysis, the characteristics of their mutual relations in the individual models have also proven to be useful. Given that the models used for the analysis are embedded in a number of theoretical disciplines, this study can also be considered as a contribution to the interdisciplinary interconnection of information science with other scientific disciplines.
The follow-up sub-objective was to use the results of the analysis of the three selected models of communication to construct a conceptual model of the document. The use of the method of model creation and the technique of graphical modeling in the form of a UML class diagram made it possible to approach this task in an illustrative manner that clearly and unambiguously expresses the semantics of the model’s components, including their mutual relations. As the partial probe focused on formal document typologies has shown, the draft model is also ready to test usability for the representation of specific document instances or their partial aspects.
We see the specific contribution of the designed model to the development of document theory in three main areas: 1) a draft solution to the relationship between the concept of document and the related concepts of information, medium, and information source, 2) a draft general method of modeling document granularity, and 3) a draft general method of modeling document typology.
We believe that this study has shown that the method of conceptual analysis and conceptual modeling is a relevant method for the document theory. The first steps in this direction, which we have taken and presented in this paper, can be considered a sort of a preliminary probe into the issue. There are certainly some alternatives to the solutions we have adopted during the conceptual analysis and model construction, which would be appropriate to discuss in a broader research community. Nevertheless, in its current provisional form, they indicate that this method could bring useful results in the future. We can see further possibilities for continuing in this direction, especially when focusing on the functional aspects of a document.
Literature
BEARD, David, 2008. From work to text to document. In Archival science. September 2008, 8(3), 217–226. Available at: https://doi.org/10.1007/s10502-009-9083-4. ISSN 1389-0166 (print). ISSN 1573-7500 (online).
BUCKLAND, Michael Keeble, 2017. Information and society. Cambridge: The MIT Press. 217 p. ISBN 978-0-262-53338-6.
BÜHLER, Karl, 1934. Sprachtheorie: die Darstellungsfunktion der Sprache. Jena: G. Fischer. xvi, 434 p.
FURNER, Jonathan, 2016. „Data“: the data. In: Matthew Kelly a Jared Bielby, ed. Information cultures in the digital age: a festschrift in honor of Rafael Capurro. Wiesbaden: Springer, pp. 287–306. Available at: https://doi.org/10.1007/978-3-658-14681-8_17. ISBN 978-3-658-14679-5 (print). ISBN 978-3-658-14681-8 (online).
GLUSHKO, Robert J., 2016. The concept of „resource“. In Robert J. Glushko, ed. The discipline of organizing: professional edition [online]. 4th ed. O'Reilly Media, chapter 1.3, pp. 36–38. Available at: https://ischools.org/resources/Documents/Discipline%20of%20organizing/Professional/TDO4-Prof-CC-Chapter1.pdf [accessed 2022-09-21].
IFLA, 2017. IFLA library reference model: a conceptual model for bibliographic information [online]. Pat Riva, Patrick LeBoeuf, Maja Žumer, ed. Hague: International Federation of Library Associations and Institutions, rev. August 2017 as amended and corrected through December 2017 [accessed 2022-09-21]. 101 p. Available at: https://www.ifla.org/publications/node/11412.
ISO 690, 2021. Information and documentation – Guidelines for bibliographic references and citations to information resources. 4th ed. Geneva: International Organization for Standardization, 2021-06. ix, 160 p.
ISO 24156-1, 2014. Graphic notations for concept modelling in terminology work and its relationship with UML – Part 1: Guidelines for using UML notation in terminology work. 1st ed. Geneva: International Organization for Standardization, 2014-10. 24 p.
JAKOBSON, Roman, 1960. Linguistics and poetics. In Style in language. Thomas Albert Sebeok, ed. Cambridge (Mass.): MIT Press, s. 350–377. – In Czech: JAKOBSON, Roman, 1995. Lingvistika a poetika. In: Poetická funkce. Miroslav Červenka, ed. Vyd. tohoto souboru 1. Jinočany: H & H, pp. 74–105. ISBN 80-85787-83-0.
KITTLER, Friedrich Adolf, 1993. Draculas Vermächtnis: Technische Schriften. Leipzig: Reclam. 259 p.
KUČEROVÁ, Helena, 2017. Sémantická problematika organizace znalostí. In Organizace znalostí: klíčová témata. Praha: Karolinum, pp. 201–230. ISBN 978-80-246-3587-3 (paperback). ISBN 978-80-246-3597-2 (pdf).
KUČEROVÁ, Helena, 2018. Pojem modelu a pojmový model v informační vědě. In Knihovna: knihovnická revue. 29(2), 5–32. ISSN 1801-3252 (print). ISSN 1802-8772 (online).
KUČEROVÁ, Helena, 2021. Teorie dokumentu: od antilopy k informační architektuře. In Knihovna: knihovnická revue. 32(2), 5–34. ISSN 1801-3252 (print). ISSN 1802-8772 (online).
LUND, Niels Windfeld, 2004. Documentation in a complementary perspective. In: Warden Boyd Rayward, ed. Aware and responsible: Papers of the Nordic-International Colloquium on Social and Cultural Awareness and Responsibility in Library, Information and Documentation Studies (SCARLID). Oxford: Scarecrow Press, pp. 93–102. ISBN 0-8108-4954-2.
LUND, Niels Windfeld, 2010. Document, text and medium: concepts, theories, and disciplines. In Journal of documentation. September 2010, 66(5), 734–749. Available at: https://doi.org/10.1108/00220411011066817. ISSN 0022-0418.
MÜLLER, Richard, Tomáš CHUDÝ a kol., 2020. Za obrysy média: literatura a medialita. Praha: Ústav pro českou literaturu AV ČR: Karolinum. 665 p. ISBN 978-80-246-4688-6 (Karolinum). ISBN 978-80-7658-005-3 (Ústav pro českou literaturu AV ČR).
OTLET, Paul. Traité de documentation: le livre sur le livre, théorie et pratique, 1934. Bruxelles: Editions Mundaneum. 431 p.
RANGANATHAN, Shiyali Ramamrita, 1931. The five laws of library science. Madras: The Madras Library Association; London: Edward Goldston. 458 p.
SHANNON, Claude Elwood a Warren WEAVER, 1949. The mathematical theory of communication. Urbana: University of Illinois Press, 1949. 125 p.
SMITH, Barry, 2012. How to do things with documents. In: Rivista di estetica. 50, 179–198. Available at: https://doi.org/10.4000/estetica.1480. ISSN 0035-6212 (print). ISSN 2421-5864 (online).
STODOLA, Jiří, 2020. Ontologický a sémantický status díla: impulzy literární vědy k promýšlení standardní knihovnické ontologie. In: Knihovna: knihovnická revue. 31(2), 29–44. ISSN 1801-3252 (print). ISSN 1802-8772 (online).
VODIČKOVÁ, Hana, 2007. Malá úvaha o české knihovnické terminologii v souvislosti s novými „pařížskými principy“ pro katalogizační pravidla aneb o FRBR. In Čtenář. 2007, 59(1), 4–8.
WILSON, Patrick, 1968. Two kinds of power: an essay on bibliographical control. Berkeley: University of California Press, 1987, © 1968. 155 p. California library reprint series. ISBN 978-0-520-03515-7.
Notes
1 Note: Definition of the term information is outside the scope of this paper. Please note that when we use the term information in this text, we mean organised meaningful data.
2 For example, see the definition of a document in the terminology standard ISO 5127:2017 (3.1.1.38) and in the ISO 690 standard (2021, 3.13): 'recorded information or a material object, which can be treated as a unit of the documentation process'.
3 Note: For those interested in a more detailed explanation, see Patrick Wilson’s essay (1968, pp. 15–19).
4 Note: The phenomenological approach is also the basis of the diachronic (historical) view of the document, which deals with the question at what stage of its life cycle an object examined was considered a document (Buckland, 2017, pp. 23–24).
5 Note: As we will see below, the dimensions of structure-function and content-form are not completely disjoint, which applies at least to the categories of form and structure.
6 See "semantic web layer cake" on the https://www.w3.org/2007/03/layerCake.png or https://en.wikipedia.org/wiki/Semantic_Web_Stack.
7 Note: The term "bibliographic universe" is not understood uniformly. Most often, it is identified with a set of bibliographic entities (in the IFLA LRM model, these are represented by the entities work, expression, manifestation, and item). Sometimes, however, the entire IFLA LRM model itself is referred to as a model of the bibliographic universe (IFLA, 2017, p. 5). For the purposes of our study, we will use the term bibliographic universe in its first meaning, i.e., as a set of bibliographic entities. It would therefore be more accurate to say that the IFLA LRM model covers the bibliographic universe and its directly related entities.
8 Note: The difference between information and message plays an important role in this model. The authors clearly declare that what is communicated is not information, but news (Shannon and Weaver, 1949, pp. 99–100).
9 Note: Similarly, we can observe overlapping levels of technique, semantics and effectiveness of communication in Shannon-Weaver's model. Jakobson's functions of the linguistic sign are also not considered to be strictly disjoint and are present to varying degrees in every linguistic act.
10 We deal with the issue of content in more detail in (Kučerová 2017). The semiotic and semantic aspects of document are also dealt with by Jiří Stodola (Stodola 2020).
11 Note: Although we preferred the term content to the term information in our study, we do not consider it appropriate to introduce the neologism "content source".
12 Note: The relationship between indirect recursion of metadata and information source is not unusual, in language communication the relationship metalanguage – object language is considered in a similar way.
13 ISO/IEC 8613-1, 1994. Information technology – Open Document Architecture (ODA) and interchange format: Introduction and general principles – Part 1. 1. ed. Geneva: International Organization for Standardization, 1994-12. 77 p.
14 IFLA. ISBD Content Form [online]. Available at: http://iflastandards.info/ns/isbd/terms/contentform.
15 RDA Content Type [online]. Available at: https://www.rdaregistry.info/termList/RDAContentType/.
16 IFLA. ISBD Content Qualification of Sensory Specification [online]. Available at: http://iflastandards.info/ns/isbd/terms/contentqualification/sensoryspecfication.
17 RDA Carrier Type [online]. Available at: https://www.rdaregistry.info/termList/RDACarrierType/.
18 IFLA. ISBD media type [online]. Available at: http://iflastandards.info/ns/isbd/terms/mediatype.
19 RDA media type [online]. Available at: https://www.rdaregistry.info/termList/RDAMediaType/.
20 RDA type of recording [online]. Available at: https://www.rdaregistry.info/termList/typeRec/.
KUČEROVÁ, Helena. Teorie dokumentu a modely komunikace. Knihovna: knihovnická revue. 2022, 33(2). ISSN 1801-3252.
]]>
Keywords: old maps, old globes, old atlases, map digitisation, globe digitisation, map collections
Ing. Milan Talich, Ph.D. / Výzkumný ústav geodetický, topografický a kartografický, v.v.i. (Research Institute of Geodesy, Topography and Cartography, v.v.i.), Ústecká 98, 250 66 Zdiby
Libraries, as well as archives, museums and other memory institutions, should provide access to books as well as to other documents. In addition to magazines, newspapers, photographs or music media (to name a few), these documents also comprise cartographic works - maps, including multi-sheet map series, atlases and globes. At the same time, libraries should provide for the interconnection between the paper and digital worlds of documents. And it is not enough for libraries to only lend these documents; other services are needed for their survival and future development. Libraries thus play a role of information, community and especially educational institutions.
However, education and literacy skills also include the “ability to read a map”. It means learning to see things in a spatial context, which is essential for the ability to structure events, information and knowledge in terms of space and position - and then to make decisions with the support of spatial information. This skill is not innate and it needs to be learned from childhood on. A map is an essential tool in this learning process. Those who do not learn this skill are less well versed in spatial contexts and can therefore be expected to be less successful in life. Moreover, old maps add another dimension to this ability - an awareness of development and time contexts.
Today’s readers want the required documents right away - as soon as possible and preferably from the comfort of their homes. Moreover, when it comes to (old) maps typical readers do not know which particular map to ask for. They usually come with a request such as “I want a map from a certain region, with a certain detail resolution and from a certain time period”. How to meet such a requirement if the library owns thousands or tens of thousands of old maps? The solution comes in the form of specialised search services for quick finding of relevant maps according to the above criteria. However, this requires not only their cataloguing including the specific data needed, but also digitisation and access to the digitised format. However, mere digitisation and subsequent free online access to view old maps is no longer enough for readers-users. They want to preserve and make full use of the potential of old maps, i.e. cartographic works, with all their specific properties - for example for measuring lengths, directions, areas, etc. And that is not all. User requirements are increasing; users are asking for some kind of added value to make their work with digitised old maps easier and, in particular, to obtain more information than is possible with the traditional use of paper maps. Digitisation, which in the mid-1990s was seen only as a tool for protecting resources and making them available, is now turning into a new service tool for readers - map users.
Old maps, plans, map atlases as well as globes are undoubtedly part of our cultural heritage. They are part of our history, visually depicting the situation at the time of their creation and complementing other historical sources. They are also important evidence of the skill, state of knowledge and artistic maturity of our ancestors.
Due to the process of their creation, maps are, unlike other historical documents, unique works. From a cartographic perspective, the oldest maps (among them also pictorial relief maps) are considered pictures or sketches rather than real maps. However, from the beginning of the 18th century, some maps started to be made on the basis of accurate geodetic measurements as well as mathematically defined map projections. Such maps could thus be used to accurately measure lengths, determine directions and calculate surface (area). It should be noted that each map has its own positional accuracy, which is based on the mapping method, instrumentation and map scale used. Maps, plans and globes are therefore works that have their cartographic properties - and only if we know these properties and, more importantly, preserve them during digitisation, we can make a full use of their information potential. At the same time, we should bear in mind how much efforts were required to create every single map with the above cartographic properties. Hundreds to thousands of people participated in their creation as it was at first necessary to address complex theoretical issues of how to project the Earth’s surface in the map plane (paper), how to build the necessary geodetic bases using measurements and calculations, including geodetic point fields (thousands of trigonometric and levelling points in the Czech Republic), perform own detailed mapping by field surveys and finally draw a map at the required scale, i.e. to make the final product. A failure to respect the cartographic properties and positional accuracy of a map during its digitisation and online projection turns such a map into a mere pretty picture and all the efforts made by our ancestors as described above are wasted.
There is no need to emphasise the need to digitise and make available archival materials, including maps. Researchers demand convenient and fast access to information. This paper should provide staff of memory institutions, especially libraries, with clear information on how to help readers find and use old maps, and advise what principles to follow when digitising their own map collections. At first, you will find an overview of major map collections in the Czech Republic with a special focus on the Chartae-Antiquae.cz Virtual Map Collection1.
Fig. 1 A section of a manuscript map of the town of Hlinsko dating back to 1731, State Regional Archive in Zámrsk. Available at http://www.chartae-antiquae.cz/maps/19248
The most extensive map collection in the Czech Republic is the collection of the Central Archive of Surveying and Cadastre (ÚAZK), which amounts to over 500,000 map sheets. The archive houses a rich collection of cadastral maps, other large map series, as well as a collection of various old maps, plans, atlases and globes. The most valuable and at the same time the most frequently used map resource is the “Stable Cadastre, Its Maintenance and Renewal (1824–1955)”, which consists of:
However, it should be noted that indication sketches are not part of these resources of ÚAZK as they are physically stored in the National Archive in Prague (for Bohemia), in the Moravian Regional Archive in Brno (for Moravia) and in the Regional Archive in Opava (for Silesia). They are therefore part of the relevant holdings of these archives, while their data (raster images) are available for viewing on the ÚAZK website on the basis of mutual inter-archive agreements. ÚAZK continuously digitises their map resources and makes maps available at archivnimapy.cuzk.cz. This is where you can find imperial obligatory imprints, original maps of the stable cadastre, indication sketches, maps from the 3rd Military Survey, topographic maps in the S-1952 coordinate system, all successive editions of the State Map derived 1 : 5,000 (SMO-5), maps of real estate records as well as maps and plans from the collection until 1850. The holdings therefore consist mainly of large multi-sheet map series. The digitisation of the entire map collection should be completed by the end of 2020.
Another large map collection is owned by the Military Geographic and Hydro-meteorological Institute of General Josef Churavý (VGHMÚř). There are about 150,000 mainly military maps in the collection, which consists predominantly of special-purpose and general maps from the 3rd Military Survey, Czechoslovak military maps as well as nationality and tourist maps. Some sheets are archived in several copies.
In addition to the collection of maps, VGHMÚř also keeps around 730,000 negatives of aerial survey images (ASI) (1936–2010). The digitisation of old military maps is not carried out at VGHMÚř. Historical ASIs are systematically digitised in cooperation with VGHMÚř and the Surveying Office and published in the application called “National Archive of Aerial Survey Images” at https://lms.cuzk.cz/lms/lms_prehl_05.html. It is also possible to order a copy of historical aerial survey images from a period of 1937 to 2002 for a fee at http://www.geoservice.army.cz/historicke-lms.
Fig. 2 Archive of aerial images of Prague at http://app.iprpraha.cz/apl/app/ortofoto-archiv/
In addition, aerial images of various towns and cities from various time periods can be found on the Internet, such as of the capital city of Prague (http://app.iprpraha.cz/apl/app/ortofoto-archiv/), the city of Pilsen (http://gis.plzen.eu/staremapy/), or the city of Karviná (http://uap.karvina.cz/) and the town of Klecany (https://maps.cleerio.cz/klecany). For example, the Cenia map portal has made available an orthophotomap of the entire territory of the Czech Republic from the 1950s (http://kontaminace.cenia.cz/). A historical orthophotomap of the entire territory of Slovakia is available on the map portal of the Technical University in Zvolen (http://mapy.tuzvo.sk/HOFM/).
The Map Collection of the Faculty of Science of Charles University amounts to ca 130,000 maps, 2,000 atlases and 80 globes (http://www.mapovasbirka.cz/). Digitisation is currently underway and around 65,000 documents are available in the electronic catalogue.
Another collection is the Map Collection of the Institute of Geography of Masaryk University in Brno, though not so extensive. It has approximately 18,000 inventory items that are continuously digitised (http://mapy.geogr.muni.cz). Moll’s Map Collection of the Moravian Regional Library in Brno with 12,000 maps, available in a digital format at http://mapy.mzk.cz/ , ranks among minor map collections. The collection of the National Technical Museum amounts to a similar number of about 20,000 maps.
Thousands to tens of thousands of maps can be found in the holdings of individual State Regional Archives, and hundreds or thousands are also preserved in each of their subordinate district archives. In total, the state archives may hold about 300,000 old maps.
Major map collections include the Map Collection of the Institute of History of the Czech Academy of Sciences, Prague City Archives, the National Library of the Czech Republic with its Lobkowicz Collection, and the National Archive in Prague. Old maps can also be found in city museums, scientific, castle and other libraries as well as in heritage institutes.
In the above institutions, the digitisation of maps is carried out using different procedures and different instrumentation. There are also various other methods, software or web applications, to make maps available online, though these provide the user with a not always satisfactory image quality and often limited interactivity. In many cases, the user does not have the opportunity to use all the information potential that is hidden in maps. Therefore, the project titled “Cartographic Sources as Cultural Heritage”, described in more detail in the next chapter, has been implemented. Its ambition has been to show how to properly digitise and make cartographic works accessible to provide the user with appropriate conditions and tools for the maximum utilisation of old maps, including for their own projects. The project also aims at creating and offering the necessary methodologies, technologies and SW tools.
The full name of the project is “Cartographic Sources as Cultural Heritage. Research into New Methodologies and Technologies for Digitisation and Utilisation of Old Maps, Plans, Atlases and Globes.” The project was funded by the NAKI (National and Cultural Identity) Programme of the Ministry of Culture for 2011–2015. Two research institutions collaborated on the project, namely: The Research Institute of Geodesy, Topography and Cartography, v. v. i. (VÚGTK) and The Institute of History of the Czech Academy of Sciences, v. v. i. (HÚ AV ČR) 2.
The name of the project suggests that the solution lies in new methodologies and technologies that make old maps accessible in the Internet environment. The tangible output of this five-year project is (and that is certainly the most interesting for the users) a number of freely available web applications that increase the efficiency of working with old maps. At the same time, a database of digital old maps has come into light. These maps were scanned as part of the project. The map database and web applications are available free of charge at Chartae-antiquae.cz or at a simpler address virtualnimapovasbirka.cz.
The project has gradually been joined by a number of institutions which house map collections that have not yet been systematically digitised. It is worth noting that these are both nationwide institutions and small institutions with only a local reach. They include various state regional and district archives such as the National Archive, various museums including the National Technical Museum, libraries such as the National Library in Prague, the Moravian Regional Library in Brno or the Municipal Library in Prague, church institutions (The Royal Canonry of the Premonstratensian Order in Strahov) as well as private collectors and antiquarians specialising in old maps. All the institutions signed cooperation agreements that also covered reproduction rights to digitised cartographic works and providing their digital copies to third parties.
The project results comprised of various certified methodologies, proven technologies and specialised software are available on the project website at naki.vugtk.cz, where you can also read published articles. Perhaps the most important project output for old cartographic works end users (even though from the project perspective this output might seem rather insignificant) is the Chartae-Antiquae.cz Virtual Map Collection3. This map collection will further be used as a good practice example.
2.2 Chartae-Antiquae.cz Virtual Map Collection
As part of the above mentioned project “Cartographic Sources as Cultural Heritage” a new web portal called Chartae-Antiquae.cz dedicated to old cartographic products has been created. The portal makes available high-resolution old maps, plans, atlases and globes from various map collections from all over the Czech Republic. There are large-scale maps, such as maps of manor farm estates, forest maps, stable cadastre maps or city plans; medium-scale maps such as maps of regions, mountain ranges or tourist maps; and small-scale maps, i.e. maps of states, continents and the world. Approximately 65,000 map sheets are now available in the database, and more maps are gradually being added. More than 75,000 old maps from the above-mentioned institutions have been scanned. The user will find some brief information on each map. A comprehensive and online accessible virtual map collection, one of the largest in the Czech Republic, has thus been created. By making maps available on the map server, via Web Map Services (WMS4 or TMS5) or various web applications, the users have been provided with new tools for analysing old maps. Special attention is paid to providing maps of the 3rd Military Survey via WMS/TMS. For this purpose, it was necessary to perform their georeferencing (placement in the coordinate system) using a special procedure, which required a mathematical derivation of a new type of elastic coordinate transformation using the collocation method (see footnotes 6, 7)6, 7. In addition to the above maps, the collection also provides access to 150 old atlases and 114 virtual 3D models of globes, which can be projected into a 2D plane.
The portal with its maps is gradually becoming an important source of information used by historians, cartographers, surveyors, landscapers, environmentalists, water managers, urban planners, architects, students, as well as researchers, the general public and lovers of old maps. It is important to note that the maps come from various map collections in the Czech Republic, of which the vast majority do not - and in the near future will not - have the funds to digitise them. Furthermore, they are very often large-scale maps (very detailed), which can be used for detailed studying of landscape transformation, population settlement, urban planning, road and water network development, etc. These detailed maps, which come abundantly from state regional and district archives, are often not found in any other memory institutions and their content is therefore unique to users.
The number of visitors to the portal accounts for about 100 to 120 thousand sessions per year, the portal has currently about 160 thousand users of which about 32 thousand return to its website regularly. About 30% of visits are from the Czech Republic, the rest from abroad.
3. Access to Digitised Old Cartographic Works
A careful consideration of answers will result in designing several web applications, which can be described using the below mentioned ones taken from the Chartae-Antiquae.cz portal. These reflect the most common readers’ demands for an advanced sophisticated way of working with digitised maps. For more information on trends in reader demands, see footnote 8 8.
The users need to be able to navigate through the database comprising thousands of scanned maps and to find the one that interests them. Traditionally, a library database can be searched by keywords (map author, year of publication, title, etc.). If the user does not know any keyword or is interested in maps from a certain locality, the library database will not help them much. Therefore, we have a geographic search. Even though the users can enter the name of a town or village, and/or coordinates of the place they want to see on the old map in the search field, they mainly enter the following three basic parameters:
The result of the search is a list of maps found, including previews, metadata and links to view the relevant full-resolution map in the Zoomify format, i.e. a raster image of the map. The application for viewing raster images of maps then allows you to quickly scroll and zoom-in the maps in the map web browser to the tiniest detail. This is something the user will certainly appreciate, especially when it comes to large-sized maps.
Fig. 3 A geographic search for maps in the vicinity of Pardubice with the indication of the year of publication (1450–1899) and map scale limitation to 1 : 200,000
However, more demanding researchers demand such access to maps that enables use of their cartographic properties. This requires that the digitised raster images of old maps be georeferenced, i.e. placed in the current coordinate system, taking into account their cartographic projection. Georeferencing is a relatively complex task as each map needs an individual approach, and proper and accurate georeferencing requires knowledge of mathematical cartography and respect for the cartographic projection of the old map concerned.
Georeferenced maps are published on the Chartae-Antiquae.cz portal according to the Web Map Service (WMS)9 or Tile Map Service (TMS)10 standards administered by the OGS (Open Geospatial Consortium )11. The use of standards guarantees that all users can display the maps in desktop GIS software or in their own web applications and to tile them together or, more precisely, view them as overlays on other map layers that are also provided in the WMS/TMS format, including by another party.
If the respective map found on the portal is georeferenced, it can be displayed directly on the portal in the georeferenced map viewer. This viewing can be done together with other maps, including their simple comparison by making the layers transparent. It is also possible to copy the link for providing the relevant map in the WMS format for use in the user’s GIS or in other web applications.
Fig. 4 Viewing the found map in Zoomify with metadata, a link to the viewer of the georeferenced version of the same map and its WMS address for use in one’s own GIS
The Web Map Services (WMS/TMS) are used not only for publishing individual commonplace maps, but mainly for publishing important large multi-sheet map series, where preferential georeferencing is useful. Figure 5 shows an overview of map series published on the Chartae-Antiquae.cz portal. Over time, more and more are being added. Maps can be viewed not only in a non-georeferenced format (Zoomify) but mostly in a georeferenced format in the viewer (via) WMS/TMS, as well as in the texture format on a 3D terrain model.
Old globes, which are cartographic products as well, can also be digitised. There are basically two options: you either digitise an old surviving globe or you digitise the globe (meridian) strips from which the globe was created. However, the strips have been preserved only exceptionally and, by contrast, globes matching the preserved strips often no longer exist. It is thus even possible to make a virtual reconstruction of old globes where only the relevant strips have been preserved. In both cases, the goal is to create an accurate 3D georeferenced model of a globe and a 2D map created by unrolling the globe on to a flat surface. The procedure is shown in Fig. 6.

Fig. 5. Map series on the Chartae-Antiquae.cz portal
Fig. 6 A schematic outline of two basic tasks of globe digitisation
The strips are digitised by their scanning and subsequent processing of the resulting raster images. A photogrammetric method is used to digitise real old globes where a 3D model of the globe is created by putting together the photographs scanned on a digitising device. The resulting model should be in such high-resolution that all the details are legible. Its legibility is often better than that of the original.
Fig. 7 An example of part of the list of digitised globes
The Chartae-Antiquae.cz portal now offers access to 114 models of old globes both in 3D and in 2D formats. In addition to the actual models, each globe is provided with photos and metadata with annotations - see Fig. 7. 3D models are displayed in the Cesium application. If the graphics card of the user’s PC does not support the Cesium application (applies only to older PCs), it automatically uses Google Earth to show the model. Individual models are displayed as georeferenced layers, so it is possible to compare them with each other by making them transparent. It is also possible to compare the models with the current vector layer showing the landmass and state borders, or with aerial photographs. Comparing two or more globes with each other can be very interesting for users. It is thus possible to trace back, for example, the history of discovery routes and “the state of mapping” of the world at that time, or to see the geodetic data used by the relevant globe author. Fig. 8 shows the method of making the globes accessible on the portal. (For more on digitising globes, see footnotes 12, 13, 14) 12, 13 and 14.
Spatial Information Sciences, Volume XLI-B5, 2016, XXIII ISPRS Congress, 12–19 July 2016, Prague, Czech Republic. DOI: 10.5194/isprsarchives-XLI-B5-169-2016. Available at: https://www.int-arch-photogramm-remote-sens-spatial-inf-sci.net/XLI-B5/169/2016/ .
Fig. 8 A 3D model of W. J. Blaeu’s globe from 1630 with a vector layer on the left. Globe close-up on the right.
In addition to the above mentioned task of digitising old globes the result of which is a 3D model of the globe we can, after its successful completion, work reversely. This involves creating printing masters for old globes replicas using these digital 3D models. A schematic drawing of the task is shown in Fig. 9. It is possible to create either printing masters for globe strips to be glued to a sphere of a certain size to create faithful replicas, or printing masters for paper fold-ups, which may come in several types based on the chosen polyhedron that is to replace the sphere. (For more on the reverse task, see footnote 15)15.
Fig. 9 A scheme of the reverse task of globe digitisation, i.e. the creation of printing masters for their replicas. The upper picture shows how to create a faithful replica of a globe sphere from strips, the lower picture shows how to create a paper fold-up.
Old atlases are available on the portal in their own viewer. Like globes, they have annotated metadata. At present, 150 old atlases are available there. You can search among them by atlas title, author or date of issue.
Fig. 10 A viewer of old atlases
To utilise the added value of properly digitised old maps it is necessary to create special map applications. As an example of good practice, we will again use the Chartae-Antiquae.cz portal, which offers various map web applications to users.
Georeferenced old maps already go beyond paper map possibilities and provide the users with new tools for such work with maps that would not be possible with paper maps. The first big advantage is the possibility to compare two or more different maps. With MapComparer, the user can compare maps from different time periods, maps of different scales and different cartographic projections, which may also come from different map collections. And if they remained in the source paper format they could not be placed on one table next to each other. Viewing of such maps is enabled by MapComparer, a web application available on the portal’s website and the very first web application for comparing old maps at the time of its creation (2012). Only later, following its example, similar applications began to emerge, including on a commercial basis - see, for example, http://www.georeferencer.com/compare#. MapComparer offers two types of map comparing.
The first compares maps in one large map window where the map sources are “opened” and changes in both maps can be compared with the help of a transparency tool. MapComparer can open any map sources found in the portal database - for example, the 3rd Military Survey 1: 25,000 (1876-1880) map or the current orthophoto (aerial image) map and/or maps of the 2nd Military Survey 1: 28,800 (1836–1852). Using the scroll bar, you can make individual maps more transparent and compare changes. You can also add any other maps provided by the WMS, Zoomify or as your own raster image from your PC.
When comparing more than two maps, this method is less practical and confusing for users. Therefore, MapComparer is equipped with a map viewing function in two to four map windows. In each window you can run (display) a different map and visually compare up to four maps at once. Zooming and panning a map in one window also synchronously pans maps in other windows so the user still compares the same location at the same scale and on the same screen. However, the user can upload other maps to each window using multiple layers, which can be opened or closed or made more transparent. Thus they can compare, for example, 10 maps at a time, both visually and by making them transparent.
Fig. 11 The city of Most on four different maps in MapComparer. The 2nd Military Survey (1836–1852) at the top left, the 3rd Military Survey 1 : 25,000 (1874–1938) at the top right, the 3rd Military Survey 1 : 75,000 (1923–1928) at the bottom right and a contemporary orthophoto with selected layers of the ZABAGED map.
Several map series that are most frequently used for tracking changes on old maps are already present in the application as built-in layers. However, the user can add other maps that are provided by anyone via the WMS to the application, such as cadastral maps, geological maps, maps of archaeological sites, etc. In the map window, the user can upload a map that is not provided by the WMS, but is displayed on the website via Zoomify, or a map stored on the user’s computer. However, these maps are not georeferenced and must be controlled separately in the application. It is important to emphasise that to use all these features, the user only needs a web browser and does not have to have any GIS of their own or specialised software.
Searching for map symbols on the map can be useful as an application. The portal has an application for searching map symbols in special-purpose maps of the 3rd Military Survey (1: 75,000). These maps have very rich map legends. From the user’s point of view, however, these maps are very confusing due to substantially dense drawings including hatches. For the purpose of fast search, a special application has been developed where the symbols are already automatically searched by the machine method of object recognition in the raster image. The
user only checks the appropriate map symbol in the legend and these symbols are immediately highlighted on the selected map sheet - see Fig. 12.
Fig. 12 Automatic search for churches, chapels and crosses around Lysice near Boskovice
Two more applications are available on the portal for more advanced work with maps. The first one converts the map raster image from Zoomify format into a georeferenced format that allows that map to be provided by the WMS service. Therefore, it also contains its own georeferencer (a software application for georeferencing), as georeferencing is required for this conversion. An example of online map georeferencing provided in Zoomify is shown in Fig. 13. This application therefore allows the user to georeference any map provided in the Zoomify format and then display it using a Web Map Service (WMS) e.g. in the already built-in viewer. However, it should be noted that large multi-sheet map series should not be georeferenced simply by using an online georeferencer. No such tool yet provides sufficient accuracy of the resulting georeferencing and, above all, does not provide matching of adjacent map sheets. In these cases, it is necessary to use more complex mathematical methods, which also respect the map projection properties and perform the matching of all map sheets in a seamless raster. (An example of a more complex georeferencing of a multi-sheet map series is described, for example, in footnotes 16 and/or 17)16 17.
Fig. 13 An online georeferencer of maps in Zoomify
Fig. 14 A view of the map provided by WMS/TMS in a 3D map format – an example of the 3rd Military Survey
The second application enables to display the WMS or TMS layer in a 3D map. The application is therefore used to display the already digitised maps provided in the WMS or TMS format in a 3D map (3D model). In order to display a map in a 3D format, the application uses the Cesium library, which uses WebGL (Web Graphics Library). Viewing is therefore not possible in older web browsers. One can pan, rotate, tilt or zoom-in the resulting 3D map model as well as to change the lighting direction by setting the date and time. An example of a map display in a 3D model is shown in Fig. 14.
Detailed instructions for use are available for both applications. Again, it is important to emphasise that the user only needs a web browser to use all these features and does not need any GIS of their own or specialised software.
The previous paragraph described the possibility of georeferencing with subsequent map display provided by the standardised WMS service. This also allows a map to be displayed in users’ map applications (in their GIS). This added value compared to paper maps is perhaps - especially for its generality and versatility - the most important of all mentioned so far. If old maps, or where appropriate, their raster images are provided in a georeferenced format in a standardised way (i.e. WMS/TMS), this will allow individual users to create their own applications using this data for special purposes.
As the range of users of old maps is huge and the maps can be used in almost all fields of human activity, it is generally not possible to envisage all user needs in advance and create appropriate tools accordingly to utilise old maps as input background data. Much more efficient, and, in terms of the possibility to support the utilisation of this data, more promising is to make old maps available to users in the above mentioned standardised way, which will also allow the use of cartographic properties of maps. Then, it will only be up to the users to ensure the optimum use of the provided data in their own applications for their own needs and at their own costs.
The next section will not cover detailed technical requirements for the digitisation of old maps. It will rather mention a few principles to be observed at any time, given their importance and experience as well as the above mentioned facts. These principles should also be known to librarians and staff of other memory institutions that own map collections and should be requested from the companies that digitise map collections.
When digitising maps or other documents, it should also be borne in mind that permanent preservation of digital copies is a bigger problem than permanent preservation of paper (printed) documents. Data formats are complex and are constantly evolving, which entails higher costs of the necessary reinvestments into hardware and software. Increasing demands on the quality of raster images of old maps, i.e. on higher scan resolution - dpi, thus result in higher demands on data storage capacities. As the costs of accurate certified cartometric digitisation of large maps are considerable, all data must be well backed up, which again means higher hardware costs.
It is also necessary to take into account the issue of copyright law. Copyright protection continues to be valid for 70 years after the author’s death (or, where appropriate, 70 years after publication, if it is an employee work where the copyright holder is an organisation). These works cannot be made freely available unless a licence agreement has been concluded with the author to make them available. Digitisation is thus used to protect only these works, which is certainly not enough. In addition, if the digitised products are made available by an institution other than their owner, i.e. other than the map collection owning the original paper maps, a special contract must be concluded for this purpose, taking into account the reproduction rights owned by the relevant map collection. Both of these cases also apply to the Chartae-Antiquae.cz Virtual Map Collection where (with a few exceptions) copyrighted maps are not accessible. In the vast majority of cases, there are only older maps, i.e. free-to-reproduce works. Moreover, contracts have been concluded with the holders of all map collections from which the digitised maps come, taking into account the reproduction rights to the accessible maps.
Scanning of old maps created on the basis of cartographic projections should not be carried out in a way that would prevent the preservation of their cartographic properties. The most important thing is to achieve the highest possible positional accuracy of individual pixels in the raster image. This can only be achieved by using precision cartometric scanners, the positional accuracy of which is regularly checked (certified).
This control measurement, during which the tested scanner takes a raster image of the control grid with subsequent evaluation, is provided by the Office for Surveying and the Czech Surveying and Cadastre Office (ČÚZK) then issues the appropriate certificate for cartometric or orientation scanning according to the achieved accuracy. The testing is governed by Guidelines No. 32 for the scanning of cadastral maps and graphic documentation of earlier land records,18 which provide further details, including the purpose and principles of testing the scanners in accordance with ČÚZK regulations. Scanning of a control square grid is performed (50 mm grid with the size of 700 mm × 550 mm) on non-shrinkable material (astralon plastic foil) measured on a digitiser with a guaranteed accuracy of 0.05 mm. To obtain the certificate, the tested scanner must meet the following requirements:
However, when evaluating these at first glance seemingly very strict requirements, it must be taken into consideration that, for example, a maximum permissible position deviation of only 0.4 mm for orientation scanning will result in a size error of four metres in the actual point position in a map with a scale of 1: 10,000. Further details on the testing of cartometric scanners are given, for example, in footnote 1919.
It clearly follows from the above that the optical resolution of the scanner should be at least 400 dpi in both directions. It is even strongly recommended to use higher resolution, i.e. 600 or 800 dpi, based on the experience acquired. It should be borne in mind that in order to use the above applications, it is necessary to perform georeferencing of raster images of old maps. However, this requires the resampling of these raster images as part of the process of their transformation, which naturally degrades the quality and readability of the image. The only solution is to have the original raster images in the highest possible resolution and thus have a certain “backup” to enable various operations with these images. Moreover, if we want to use digitised maps in applications that automatically process their raster images (we can use the previously mentioned application for searching map symbols as an example) it becomes apparent that even 400 dpi may not be enough because the error rate of graphical search algorithms increases sharply. And in fact the original non-geo-referenced, i.e. non-resampled (highest quality), raster images are used. In other words, 300 or 400 dpi is enough for a mere viewing of non-georeferenced maps on the screen. But if we want to use maps in a more sophisticated way, which is a clear requirement of today’s readers, we need at least 600 dpi or more. Given the amount of money that needs to be invested in the digitisation of old maps, scanning below 600 dpi can be considered wasted money in terms of future prospects. Over time, maps scanned in this manner will have to be rescanned with higher parameters. The main reason will be the growing demands of readers on using digitised maps in various applications.
To maintain colour fidelity, scanning should be performed at a colour scale of at least 24 bits, including the colour ICC (International Color Consortium profile)20 profile, which has been approved as the international ISO 15076-1: 2005 standard (Image technology colour management – Architecture, profile format and data structure)21. This colour profile is characterised by the colour gamut (achievable colour area in a particular colour space) and the properties of the reproduction device or medium. The information can then be used to accurately reproduce or display colours on a printer, monitor, plotter or another device. ICC profiles are used mainly in DTP applications where they are used for conversion between RGB and CMYK colour spaces and to ensure colour matching when reproducing colours.
The actual scanning is usually followed by basic editing of the scans - raster images. They consist in the trimming of the paper edge or map frame, rotating (straightening) of the image or, where appropriate, in removing paper shrinkage. If a proper software automated tool working on the basis of object recognition in raster images (paper edges, map frame, etc.) is used for trimming, the experience with multi-sheet map series shows that it is possible to increase the scanning performance, including pre-processing of scans, up to ten times23 and/or 24.
A common issue that also needs to be addressed when digitising maps is how to deal with duplicate occurrences of the same map. It means that the same map appears in a map collection in multiple copies or it is held in the collections of various institutions, and therefore appears multiple times in the summary virtual collection of digitised maps.
It is important to remember that maps are treated differently from ordinary documents. While the content of an ordinary text document is always the same regardless of the print or (usually) edition, this is not the case with maps. The reader obtains the same written information from different copies of the same book. However, it follows from the above that with maps specific factors come into play, such as paper shrinkage, damage to a map sheet including by drawing notes, staining it with coffee, cutting it into sections and mounting it on canvas for convenient folding, ripping a map sheet, additional overprints of nomenclature in another language, additional reprint of another coordinate grid, additional colouring of the content or content changes for different editions of the same map (“content update”). Also, the condition of each copy of the same map is different. It is apparent from all the above that all copies of old maps need to be digitised and that we cannot speak about “duplications in the catalogue”, as librarians are used to doing.
The purpose of the paper has been to provide librarians and staff of other memory institutions with clear information on how to help readers in certain specific areas, such as old maps. At the same time, the aim has been to provide information on the most important principles that need to be observed when digitising map collections to enable their owners to demand adherence of these principles from digitisation companies. Another useful source of literature is referred to in footnote25 and an example of an advanced sophisticated web application for working with old maps is referred to in footnote26.
In addition to the necessary overview of the largest map collections in the Czech Republic, made available at least in part on the Internet, we have used the Chartae-Antiquae.cz Virtual Map Collection as a good practice example to present various web applications that provide added value for digitised map users, compared to original paper maps. The portal of this Virtual Map Collection thus serves as an expert knowledge system for working with old maps. This gives users a powerful tool for their work. The digitised old maps that have been made available can be used in many fields of human activity, for example for the reconstruction of historical landscape and settlement structures, for various history studies, but also for the purposes of spatial planning to trace back the original condition.
REFERENCES:
AMBROŽOVÁ, Klára, Jan HAVRLANT, Milan TALICH a Ondřej BÖHM, 2016. The process of digitizing of old globe. In: The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, Volume XLI-B5, 2016, XXIII ISPRS Congress, 12–19 July 2016, Prague, Czech Republic. DOI: 10.5194/isprsarchives-XLI-B5-169-2016. Available at: https://www.int-arch-photogramm-remote-sens-spatial-inf-sci.net/XLI-B5/169/2016/ .
ANTOŠ, Filip, Ondřej BÖHM a Milan TALICH, 2014. Accuracy testing of cartometric scanners for old maps digitizing. In: 9th International Workshop on Digital Approaches to Cartographic Heritage, Budapest, 4–5 September 2014, 8pp. Available at:
http://naki.vugtk.cz/media/doc/publikace/antos_et_all-acuracy_testing.pdf .
ANTOŠ, Filip, Ondřej BÖHM a Milan TALICH, 2011. Automatické zpracování prvního vydání Státní mapy 1 : 5 000 – odvozené pro vystavení na internetu, In: 19. Kartografická konferencia, kartografia a geoinformatika vo svetle dneška, ed. L. Gálová, R. Fencík, Bratislava, 8. – 9. 9. 2011, pp. 16–25.
ČESKÝ ÚŘAD ZEMĚMĚŘIČSKÝ A KATASTRÁLNÍ. Pokyny č. 32 Českého úřadu zeměměřického a katastrálního ze dne 28. dubna 2004, č.j. 1014/2004-22 pro skenování katastrálních map a grafických operátů dřívějších pozemkových evidencí, ve znění dodatku č. 1 ze dne 15. 2. 2005 č.j. 613/2005-22, dodatku č. 2 ze dne 8. 3. 2005 č.j. 1503/2005-22, dodatku č. 3 ze dne 7. 4. 2006 č.j. 1223/2006-22, dodatku č. 4 ze dne 16. 5. 2006 č.j. 2321/2006-22, [cit. 15. 3. 2019]. Available at: https://www.cuzk.cz/Predpisy/Resortni-predpisy-a-opatreni/Pokyny-CUZK-31-42/Pokyny_32.aspx
DF11P01OVV021 – Kartografické zdroje jako kulturní dědictví. Výzkum nových metodik a technologií digitalizace, zpřístupnění a využití starých map, plánů, atlasů a glóbů. (2011–2015, MK0/DF). https://www.rvvi.cz/cep?s=jednoduche-vyhledavani&ss=detail&n=0&h=DF11P01OVV021 [cit. 15. 3. 2019].
HAVRLANT, Jan, Klára AMBROŽOVÁ, Milan TALICH, Ondřej BÖHM, 2017. Digital models of old globes created from globe segments. In: 17th International Multidisciplinary Scientific GeoConference SGEM 2017, www.sgem.org, SGEM2017 Conference Proceedings, ISBN 978-619-7408-03-4, ISSN 1314-2704, 29 June – 5 July, 2017, Vol. 17, Issue 23, 473–480 pp, DOI: 10.5593/sgem2017/23/S11.058, https://sgemworld.at/sgemlib/spip.php?article9485 .
HAVRLANT, Jan, Milan TALICH a Klára VACKOVÁ, 2018. The creation of cartographic data for replicas of old globes. In: 18th International Multidisciplinary Scientific GeoConference Surveying Geology and Mining Ecology Management (SGEM), Volume 18, Issue 2.3, Sofia, 2018, pp. 623–633, ISSN 13142704, DOI: 10.5593/sgem2018/2.3/S11.079,
https://sgemworld.at/sgemlib/spip.php?article12691 .
MEZINÁRODNÍ STANDARD ISO 15076–1:2005 (Image technology colour management – Architecture, profile format and data structure). Dostupné z: http://www.iso.org/iso/catalogue_detail.htm?csnumber=40317, ISO 15076–1:2005 Image technology colour management -- Architecture, profile format and data structure. Part 1: Based on ICC.1: 2004–10, [cit. 15. 3. 2019].
TALICH, Milan, 2012. Trendy výzkumu možností využívání starých map digitálními metodami. Kapitola v knize: Krajina jako historické jeviště. K poctě Evy Semotanové. Praha: Historický ústav (eds. Chodějovská, E.; Šimůnek, R.), pp. 373–386, ISBN 978-80-7286-199-6. Available at: http://naki.vugtk.cz/media/doc/publikace/Krajina_Talich.pdf .
TALICH, Milan, Klára AMBROŽOVÁ, Jan HAVRLANT a Ondřej BÖHM, 2015. Digitization of Old Globes by a Photogrammetric Method. Lecture Notes in Geoinformation and Cartography 2015. Cartography – Maps Connecting the World. 27th International Cartographic Conference 2015 – ICC2015. Editors: Claudia Robbi Sluter, Carla Bernadete Madureira Cruz, Paulo Márcio Leal de Menezes. Springer International Publishing. pp. 249–263. DOI: 10.1007/978-3-319-17738-0_17, ISBN: 978-3-319-17737-3, ISSN 1863-2246.
TALICH, Milan, Filip ANTOŠ a Ondřej BÖHM, 2011. Automatic processing of the first release of derived state maps series for web publication. In: 25th International Cartographic Conference (ICC2011) and the 15th General Assembly of the International Cartographic Association, Paris, France, 3 – 8 July 2011, section “C3-Digital technologies and cartographic heritage”. ISBN 978-1-907075-05-6. Available at: http://naki.vugtk.cz/media/doc/publikace/co-268.pdf .
TALICH, Milan, Ondřej BÖHM a Lubomír SOUKUP, 2018. Classification of digitized old maps. In book: Advances and Trends in Geodesy, Cartography and Geoinformatics, Eds: Molcikova, S., Hurcikova, V., Zeliznakova, V., P. Blistan. ISBN 978-0-429-50564-5, CRC PRESS-TAYLOR & FRANCIS GROUP, April 2018, 197–202 pp, DOI: 10.1201/9780429505645-32,
https://www.taylorfrancis.com/books/e/9780429012891/chapters/10.1201%2F9780429505645-32 .
TALICH, Milan, Lubomír SOUKUP, Jan HAVRLANT, Klára AMBROŽOVÁ, Ondřej BÖHM a Filip ANTOŠ, 2013a. Georeferencing of the Third Military Survey of Austrian Monarchy. In: Proceedings of the 26th International Cartographic Conference, Dresden, Germany, 25–30 August 2013, pp. 898–899, International Cartographic Association, ISBN 78-1-907075-06-3, Available at: https://icaci.org/files/documents/ICC_proceedings/ICC2013/_extendedAbstract/266_proceeding.pdf .
TALICH, Milan, Lubomír SOUKUP, Jan HAVRLANT, Klára AMBROŽOVÁ, Ondřej BÖHM a Filip ANTOŠ, 2013b. Nový postup georeferencování map III. vojenského mapování. Kartografické listy, 21(2), 35-49. Bratislava: Kartografická spoločnosť Slovenskej republiky v spolupráci s Geografickým ústavom Slovenskej akadémie vied a Prírodovedeckou fakultou Univerzity Komenského v Bratislave, Slovensko. ISSN 1336-5274.
TALICH, Milan, Eva SEMOTANOVÁ a kol., 2015. Kartografické zdroje jako kulturní dědictví. Výzkum nových metodik a technologií digitalizace, zpřístupnění a využití starých map, plánů, atlasů a glóbů. Elektronická publikace, Praha: Historický ústav AV ČR, vol. 64, ISBN 978-80-7286-262-7, p. 114. Available at: http://naki.vugtk.cz/media/doc/katalog_2015.pdf .
VIRTUÁLNÍ MAPOVÁ SBÍRKA CHARTAE-ANTIQUAE.CZ. Virtuální mapová sbírka [online]. [cit. 2020-03-15]. Available at: http://www.chartae-antiquae.cz .
Notes
1 http://www.chartae-antiquae.cz, Virtuální mapová sbírka Chartae-Antiquae.cz. [cit. 15. 3. 2019].
2 DF11P01OVV021 – Kartografické zdroje jako kulturní dědictví. Výzkum nových metodik a technologií digitalizace, zpřístupnění a využití starých map, plánů, atlasů a glóbů. (2011–2015, MK0/DF).
https://www.rvvi.cz/cep?s=jednoduche-vyhledavani&ss=detail&n=0&h=DF11P01OVV021 [cit. 15. 3. 2019].
3 http://www.chartae-antiquae.cz, Virtuální mapová sbírka Chartae-Antiquae.cz. [cit. 15. 3. 2019].
4 http://www.opengeospatial.org/standards/wms, The OpenGIS® Web Map Service Interface Standard (WMS), [cit. 15. 3. 2019].
5 https://en.wikipedia.org/wiki/Tile_Map_Service, Tile Map Service (TMS), [cit. 15. 3. 2019].
6 TALICH, Milan, Lubomír SOUKUP, Jan HAVRLANT, Klára AMBROŽOVÁ, Ondřej BÖHM a Filip ANTOŠ. Georeferencing of the Third Military Survey of Austrian Monarchy. In: Proceedings of the 26th International Cartographic Conference, Dresden, Germany, 25–30 August 2013, pp. 898–899, International Cartographic Association, ISBN 78-1-907075-06-3, Available at: https://icaci.org/files/documents/ICC_proceedings/ICC2013/_extendedAbstract/266_proceeding.pdf.
7 TALICH, Milan, Lubomír SOUKUP, Jan HAVRLANT, Klára AMBROŽOVÁ, Ondřej BÖHM a Filip ANTOŠ. Nový postup georeferencování map III. vojenského mapování. Kartografické listy, 21 (2), Bratislava, Kartografická spoločnosť Slovenskej republiky v spolupráci s Geografickým ústavom Slovenskej akadémie vied a Prírodovedeckou fakultou Univerzity Komenského v Bratislave, Slovensko, 2013, pp. 35–49, ISSN 1336-5274.
8 TALICH, Milan. Trendy výzkumu možností využívání starých map digitálními metodami. Kapitola v knize: Krajina jako historické jeviště. K poctě Evy Semotanové. Praha: Historický ústav, 2012 - (eds. Chodějovská, E.; Šimůnek, R.), pp. 373–386, ISBN 978-80-7286-199-6. Available at: http://naki.vugtk.cz/media/doc/publikace/Krajina_Talich.pdf.
9 http://www.opengeospatial.org/standards/wms, The OpenGIS® Web Map Service Interface Standard (WMS), [cit. 15. 3. 2019].
10 https://en.wikipedia.org/wiki/Tile_Map_Service, Tile Map Service (TMS), [cit. 15. 3. 2019].
11 http://www.opengeospatial.org/, The Open Geospatial Consortium, [cit. 15. 3. 2019].
12 TALICH, Milan, Klára AMBROŽOVÁ, Jan HAVRLANT a Ondřej BÖHM. Digitization of Old Globes by a Photogrammetric Method. Lecture Notes in Geoinformation and Cartography 2015. Cartography – Maps Connecting the World. 27th International Cartographic Conference 2015 - ICC2015. Editors: Claudia Robbi Sluter, Carla Bernadete Madureira Cruz, Paulo Márcio Leal de Menezes. Springer International Publishing. pp. 249–263, 2015, DOI: 10.1007/978-3-319-17738-0_17, ISBN: 978-3-319-17737-3, ISSN 1863-2246.
13 AMBROŽOVÁ, Klára, Jan HAVRLANT, Milan TALICH a Ondřej BÖHM. The process of digitizing of old globe. In: The International Archives of the Photogrammetry, Remote Sensing and
14 HAVRLANT, Jan, Klára AMBROŽOVÁ, Milan TALICH, Ondřej BÖHM. Digital models of old globes created from globe segments. In: 17th International Multidisciplinary Scientific GeoConference SGEM 2017, www.sgem.org, SGEM2017 Conference Proceedings, ISBN 978-619-7408-03-4 / ISSN 1314-2704, 29 June – 5 July, 2017, Vol. 17, Issue 23, 473–480 pp, DOI: 10.5593/sgem2017/23/S11.058, https://sgemworld.at/sgemlib/spip.php?article9485 .
15 HAVRLANT, Jan, Milan TALICH a Klára VACKOVÁ. The creation of cartographic data for replicas of old globes. In: 18th International Multidisciplinary Scientific GeoConference Surveying Geology and Mining Ecology Management (SGEM), Volume 18, Issue 2.3, Sofia, 2018, pp. 623–633, ISSN: 13142704, DOI: 10.5593/sgem2018/2.3/S11.079,
https://sgemworld.at/sgemlib/spip.php?article12691 .
16 TALICH, Milan, Lubomír SOUKUP, Jan HAVRLANT, Klára AMBROŽOVÁ, Ondřej BÖHM a Filip ANTOŠ. Georeferencing of the Third Military Survey of Austrian Monarchy. In: Proceedings of the 26th International Cartographic Conference, Dresden, Germany, 25–30 August 2013, pp. 898–899, International Cartographic Association, ISBN 78-1-907075-06-3, Available at: https://icaci.org/files/documents/ICC_proceedings/ICC2013/_extendedAbstract/266_proceeding.pdf
17 TALICH, Milan, Lubomír SOUKUP, Jan HAVRLANT, Klára AMBROŽOVÁ, Ondřej BÖHM a Filip ANTOŠ. Nový postup georeferencování map III. vojenského mapování. Kartografické listy, 21 (2), Bratislava, Kartografická spoločnosť Slovenskej republiky v spolupráci s Geografickým ústavom Slovenskej akadémie vied a Prírodovedeckou fakultou Univerzity Komenského v Bratislave, Slovensko, 2013, pp. 35–49, ISSN 1336-5274.
18 https://www.cuzk.cz/Predpisy/Resortni-predpisy-a-opatreni/Pokyny-CUZK-31-42/Pokyny_32.aspx , Pokyny č. 32 Českého úřadu zeměměřického a katastrálního ze dne 28. dubna 2004, č.j. 1014/2004-22 pro skenování katastrálních map a grafických operátů dřívějších pozemkových evidencí, ve znění dodatku č. 1 ze dne 15. 2. 2005 č.j. 613/2005-22, dodatku č. 2 ze dne 8. 3. 2005 č.j. 1503/2005-22, dodatku č. 3 ze dne 7. 4. 2006 č.j. 1223/2006-22, dodatku č. 4 ze dne 16. 5. 2006 č.j. 2321/2006-22, [cit. 15. 3. 2019 ].
19 ANTOŠ, Filip, Ondřej BÖHM a Milan TALICH. Accuracy testing of cartometric scanners for old maps digitizing. In: 9th International Workshop on Digital Approaches to Cartographic Heritage, Budapest, 4–5 September 2014, 8pp. Available at:
http://naki.vugtk.cz/media/doc/publikace/antos_et_all-acuracy_testing.pdf
20 http://www.color.org/, International Color Consortium, [cit. 15. 3. 2019].
21 http://www.iso.org/iso/catalogue_detail.htm?csnumber=40317, ISO 15076–1:2005 Image technology colour management -- Architecture, profile format and data structure. Part 1: Based on ICC.1: 2004–10, [cit. 15. 3. 2019].
22 https://en.wikipedia.org/wiki/Thin_plate_spline, Thin plate spline. Wikipedia, the free encyclopedia, [cit. 15. 3. 2019].
23 ANTOŠ, Filip, Ondřej BÖHM a Milan TALICH. Automatické zpracování prvního vydání Státní mapy 1 : 5 000 – odvozené pro vystavení na internetu, in: 19. Kartografická konferencia, kartografia a geoinformatika vo svetle dneška, ed. L. Gálová – R. Fencík, Bratislava, 8. – 9. 9. 2011, pp. 16–25.
24 TALICH, Milan, Filip ANTOŠ a Ondřej BÖHM. Automatic processing of the first release of derived state maps series for web publication. In: 25th International Cartographic Conference (ICC2011) and the 15th General Assembly of the International Cartographic Association, Paris, France, 3 – 8 July 2011, section „C3-Digital technologies and cartographic heritage“. ISBN: 978-1-907075-05-6. Available at: http://naki.vugtk.cz/media/doc/publikace/co-268.pdf .
25 TALICH, Milan, Eva SEMOTANOVÁ a kol. Kartografické zdroje jako kulturní dědictví. Výzkum nových metodik a technologií digitalizace, zpřístupnění a využití starých map, plánů, atlasů a glóbů. Elektronická publikace, Praha 2015: Historický ústav AV ČR, vol. 64, ISBN 978-80-7286-262-7, pp 114. Available at: http://naki.vugtk.cz/media/doc/katalog_2015.pdf .
26 TALICH, Milan, Ondřej BÖHM a Lubomír SOUKUP. Classification of digitized old maps. In book: Advances and Trends in Geodesy, Cartography and Geoinformatics, Eds: Molcikova, S.; Hurcikova, V.; Zeliznakova, V.; Blistan, P., ISBN: 978-0-429-50564-5, CRC PRESS-TAYLOR & FRANCIS GROUP, April 2018, 197–202 pp, DOI: 10.1201/9780429505645-32,
https://www.taylorfrancis.com/books/e/9780429012891/chapters/10.1201%2F9780429505645-32 .
Ing. Petra Vávrová, Ph.D., Mgr. Jitka Neoralová, Dana Hřebecká, Ing. Kristýna Kohoutová, MgA. Anna Kulíčková, Bc. Marie Matysová, Daniela Popelková, Tomáš Blecha / Odbor ochrany knihovních fondů, Oddělení vývoje a výzkumných laboratoří, Národní knihovny České republiky (Division of preservation of library collections, Department of development and experimental laboratories of the National Library of the Czech Republic), Klementinum 190, 110 00 Prague 1, Czech Republic
Introduction
Bookbinding represents a rich source not only of textual and visual information, but it is also a physical document of art and craft creation of a binder, contemporary trend of technology of production, and last but not least a document of history of proper existence reverberating in defects from wear and tear and from natural decomposition of materials. Technology of making books and their damages are often hidden beneath layers of materials, and it is possible to find them out without invasive intervention only with difficulty. By the help of through illuminative technology making use of X-rays, it is possible to penetrate not destructively below the surface of outer layers to inner structures and structural elements of bookbinding. Within the frame of the grant project of the Ministry of Culture NAKI II with name "Utilization of imaging methods for study of hidden information in books", the workplace of the Department of development and experimental laboratories of the National library CR (hereinafter also NL CR) was equipped with an x-ray box, a part of which is an X-ray source and digital detector of flat panel type. Information on used technologies, materials, and their conditions are fundamental also for historic, artistic and scientific understanding of bookbinding.
Box arrangement for digital radiography – x-ray system – contains shielded lead box, in which x-ray generator is placed for lower energy of 120 kV, and a flat digital detector making possible an active view and adjustment of image on recording in connected computer. Images are processed in original software X-Test, which controls at the same time the source of radiation, processes images, and saves the record in a form of static images and also videos. The box itself is equipped with electronically controlled sliding table, allowing moving in the horizontal and vertical directions.
This equipment was purchased for detailed testing of possibilities and limitations of X-ray in a survey, which focused on visualization of hidden elements, layers, or damages in layers of bookbinding materials. Possibilities of bookbinding survey in situ are very limited. It is impossible to penetrate to most parts of the binding structure without violation of upper layers. Recycled materials often occur in binding in historic collections, as cut parchment foils, sheets of books, letters, spoiled print waste, and other materials, which may be older than the specimen itself. It is possible to find them in a book back part beneath coating, on covers, as flaps, whole pasted papers of the covers, or endpapers. It is thus possible to obtain locked up information of priceless value of historic and also modern bindings just by the help of radiography.
For survey of book collections, X-rays of energies in order of values of tens keV is used first of all with respect to material composition (paper, textile, wood, leather, parchment, and in smaller extent also metal). The surveyed object is placed between the source of radiation and radiation detector in position enabling to obtain image of a given element of bookbinding, whereas taking of photographs proceeds inside the closed, radiation shielding box. The object is radiographed by radiation produced by X-ray tube housed in the upper part of the box, and image is photographed by image detector (flat, or flat panel) placed in the lower part of the box. Grades of grey in the obtained image represent higher or lower measure of x-ray absorption in the given part of the object. Darker shades correspond to materials more absorbing radiation (especially metals), lighter areas represent materials less absorbing radiation (paper, textile, leather, etc.). Another factor determining total quantity of absorbed radiation (and therefore also shade of grey in the image) is also thickness of radiographed material. Last but not least the grade of grey depends also on graphic adjustments, which were performed after acquisition of the image for the purpose of provision optimum visibility of details of X-rayed elements.
A part of the tasks of project NAKI being studied is research of utilization of x-rays for study of books with the use of x-ray box, which the workplace was equipped with within the frame of the project.
Materials typical for books are paper, textile, wood, leather, parchment, and in smaller extent also metals, but also plastics or bones occur. With respect to different physical properties of these materials, different setting of equipment is needed for optimal displaying the elements of bookbinding manufactured of them, their structure and possible defects. It especially concerns suitable setting of electric current and voltage on X-ray tube, distance of X-ray tube from the detector, and distance of X-rayed object from the detector. Selection of suitable position of the book is also fundamental (or for obtaining complex information step by step, more positions of the same books), and suitable construction, which keeps the book in required position and also the distance from the detector, including suitable materials of this construction.
No less important is also subsequent graphic adjustment, again corresponding to the element of bookbinding, which we want to display, and its material. Here it concerns especially sharpening the image, adjustment of brightness, contrast, gamma correction, exposition, levelling the image, for clarity also e.g. cleaning of book background, rotation, and cut off. Insufficient visibility of the required element on the image is possible to compensate using graphical adjustments.
Settings of selected parameters of the equipment placed in the National library CR, and also found internal structures of bookbinding, which are not visible without destruction of the book are presented in the following chapters. This visualized information will then make easy for restorers or conservators to decide, which steps will be or will not be necessary to carry out for preservation of the book, or how to care about the book.
Within the frame of project NAKI II with the name "Utilization of imaging methods for study of hidden information in books" an X-ray unit was purchased on the basis of selection procedure IXS1203 with the following parameters:
|
Parameter |
Value |
|
maximum voltage |
120 kV |
|
current of a closed lamp within the range |
0.05-0.3 mA (36 W) |
|
Focus |
0.05 mm |
The source has adjustable voltage serving for generation of X-rays.
Flat digital detector XRD 1622 AP14 with active surface of size 41 x 41 cm. Detector resolution 2048×2048 pixels (pixel size 200 lm), energy corresponding to voltage range 20 kV- 15 MV. The digital detector scans images in 16-bit depth, at the speed of 1 image/sec. The image itself is an average of eight images. A control computer is equipped with software for processing photographs and control of source of radiation. The software X-test was developed by the supplier, company Testima spol. s r.o.. It makes it possible to acquire static images and videos. More precise adjustments are carried out in software Photoshop.
Procedures of graphic adjustments of images acquired by the help of x-ray will be described in detail in separate paper, now under preparation.
Voltage applied on X-ray tube affects shape of energetic spectra of photons produced by X-ray tube, i.e. photons of what energies are produced, and in what proportion, but it also affects a total number of produced particles.
While using higher voltage on X-ray tube, formation of larger amount of photons occurs, and at the same time mean energy of these photons increases, and also maximum possible energy of each of produced photon. With increasing photon energy, simultaneously typically increases half-thickness, i.e. material thickness through which half of photons passes from bunch of photons of given energy.
With increasing material thickness it is therefore reasonable to select higher voltage in taking of photographs, so that sufficient particle number passed through this thicker material layer, and the image is then sufficiently light.
With increasing proton number Z of an element, half-thickness drops down for photons of particular unchanging energy. To achieve similar lightness of the image, and so that structures in material are perceptible, i.e. sufficient particle number passes through the material, it is then necessary to increase energy of passing through photons, i.e. increase voltage, with increasing proton number of an element, or effective proton number of material. On the other hand, structures formed of materials with low effective proton number are advisable to be displayed when using lower voltage, so that sufficient inhibition of a bunch in material occurs, and structures are recognizable in the image.
Voltage is adjustable within the limits of 40 – 120 kV in case of the apparatus.
For materials typically used in book manufacturing, the following can be stated on the basis of preliminary results: When displaying details of parts of a book, which are formed of paper, textile (including gauze, threads, etc.), leather or parchment, or thin layer of wood, it is advisable to set lower voltage from the given range. In case of thin layers of these materials, it is most suitable to use voltage of 65 – 70 kV. For thicker layers, e.g. wooden book covers, higher voltage, approximately 70 – 80 kV is more suitable because of necessity to radiate material through. For metals it is necessary to use high voltage (usually 120 kV) – if these are not in a very thin layers.
In addition to material of the component under examination, it is necessary to take into account also materials, which overlay the component – voltage must be big enough so that sufficient number of photons passes through the whole object to obtain a high-quality image. When placing a book to be X-rayed, it is necessary to observe that the component of bookbinding is displayed in the image under angle suitable for easy interpretation of the image. When setting the apparatus, but also suitable position of the book, when taking of photographs, it is necessary to consult within a cross-disciplinary team (specialist in the field of bookbinding, book designer, physicist).
By the help of x-rays passing through, it is possible to display presence of materials, and also proper structure of the material (textile structure, year rings of wood). In some cases the internal structure in the image needs to be suppressed so that complication in interpretation of other elements of bookbinding, which are overlapped by this material in the image, does not happen.
In most materials used for book manufacturing the internal structure is not visible in the image, when using our settings of the apparatus (usually because the structure is too small or too low-contrast in the image). When determining the material, it is therefore necessary to orientate oneself especially according to the extent of material darkness in the image in comparison with other (known) materials visible in the image. For example, formations in cardboard book cover may appear all likewise distinctive and dark at voltage 65 kV, however, while using voltage 100 kV, it is easy to distinguish, in which cases it concerns only more expressive inhomogeneities, and in which cases it concerns metal inclusions, because metal is in contrast to inhomogeneities also at higher voltages always expressively visible in the image.
At the same applied voltage, but higher current, the energy spectrum of produced particles has the same shape, however, the amount of produced particles increases. Whereas smaller quantity of particles is generally produced at lower voltages, than at higher ones and identical current, to achieve similar average darkness of the image, it is necessary to increase current with decreasing voltage while preserving values the of other parameters.
If it is possible, it is advisable to set current already while acquiring images so that the obtained image is reasonably light. Unfortunately, especially when using low voltage, this possibility is limited by maximum adjustable current, which is given by technical possibilities of the apparatus.
In case of the apparatus used in NL CR and its setting in the laboratory, current is adjustable within the limits 0 – 300 A. To achieve sufficient lightness of images at voltage of about 60 – 80 kV, the highest adjustable current 300 A is used. Especially at voltage 60 – 65 kV, number of photons impinging on detector is in such a case low, i.e. the images are very dark. When using higher voltages, no matter whether due to thicker material layers, or materials with higher effective proton number, it is advisable to correct current so that suitable lightness or darkness of the image is achieved in the area of interest.
With respect to divergence of bunch of x-ray photons, the image is acquired with certain magnification, when placing the book to non-zero distance from the detector, whereas this magnification increases with the object distance from the detector.
If the specimen is placed directly on the detector, it is advisable that the detector is covered with a layer of protective material, which prevents the detector from contamination and scratching in case of sharp components of the object to be radiographed. It is important to use a thin layer of material, which has the greatest half-thickness possible for photons of applied energies, i.e. the largest part of bunch of photons possible passes through it without changes. At the same time this material should not have visible internal structure so that overlapping of book components under examination does not occur in the image, which would make interpretation of the image more difficult. Polyester film Melinex was assessed as the most suitable from materials of thickness of 75 µm, which is inert to bookbinding materials, and does not change parameters of the image.
Similar demands apply also on construction material, which holds the book in required position and required height above the detector, as on protective material. With respect to book weight, however, higher demands are applied on strength of the bookbinding material, which wholly or from part eliminate some materials suitable for protection of the detector. It is necessary to fasten the book outside the area displayed on the image. In such a case it is possible to use also materials heavily absorbing X-rays.
The main reasons, why to change the distance of X-ray tube from the detector, are size changes of radiated parts of the detector, and possibility of pronounced enlargement of distance of the X-rayed object from the detector.
With respect to divergence of bunch of photons produced by X-ray tube, enlargement of diameter of circular radiated part of the detector, i.e. the part of the detector, where the image is formed, occurs with increasing distance of X-ray tube from the detector. This phenomenon, when increasing the distance of X-ray tube from the detector, is advisable to utilize in the event that we require the image of the whole book, dimensions of which exceed the radiated part of the detector. First of all, with respect to divergence of bunch of photons with increasing distance of X-ray tube from the detector, particle number impinging on radiated part of the detector on a unit of area declines, therefore, it is necessary to use higher current, or higher voltage, or both, at greater distance of X-ray tube from the detector to obtain similarly light image.
Increasing the distance of X-ray tube from the detector makes possible to locate the object to greater distance from the detector, whereby recording of a larger part of the subject may be achieved, or at taking of photographs of the whole object "in parts", a necessary number of images is reduced for make-up the image of the entire object. The disadvantage is a darker image, and necessity to increase current, while it may not be possible to sufficiently increase current for low voltage. In such a case it is necessary to increase voltage, which may reflect on lowered contrast in the area of the structures composed of lighter elements.
The distance of X-ray tube from the detector is in case of our apparatus at present adjustable within the limits of 49 – 92 cm.
To display fine structures formed of lighter elements (e.g. textile, etc.), it is advisable to X-ray with the largest magnification possible. However, it is necessary to take into account also changes, which were made during taking of photographs, as voltage setting for achieving acceptable (and to the suitable form graphically customizable) lightness of the image.
The results of radiography of bookbinding are obtained images, which are then basis for graphical work at investigation of book collections by the help of the x-ray system. Each image can be defined as a square with visible visual field of X-ray, therefore, the object under examination is inscribed into a circle, borders of which are black. The required resulting image can be found inside the circle, and in its first form it is very dark. A great number of images acquired at different settings is supplied for graphical adjustment. The largest number of items of important information remains preserved with such a procedure, which subsequently may be highlighted in a graphic programme.
An image saved in format .tiff makes it possible to preserve high quality of the image, and at the same time it is compatible with Adobe Photoshop programme. The performer can it directly open, and further also continue in saving it to the format after its modification, because its main advantage is preservation of layers of modifications, to which it is possible to return later.
The first part of systematic evaluation was carried out so far of what materials and elements of bookbinding are viewable by the help of the equipment, and in case of successful displaying - what setting at taking of images and what graphic modification are most suitable for the given material and element. A part of this subject is also systematic investigation focused on the type and material of the structure: what construction and which materials are suitable for holding the book in required position, and distance from the detector during taking of images, so that minimal possible interference of the image fixation system itself occurs. Examples of various settings of the apparatus and graphic modifications for different materials, or parts of the book, are given in Figs. 1 and 2.
Fig. 1, 2 A book at two various settings of the apparatus, images are also graphically modified in a different way. Damage of covering cloth in the area of folding on the upper edge of the book (it is unsticking and tucking up) can be seen on the first image. Details of metal pins are better visible in the second image (Fig. 2). In both cases the book is placed 36 cm above the detector covered with a foil, X-ray tube 49 cm from the detector, current 300 A; irradiation time for image acquisition is 1 s. The first image (Fig. 1): voltage on X-ray tube 75 kV; graphic modification: cut off; gamma correction 1.40; exposure -0,50; brightness1 70; contrast1 100; brightness2 50; contrast2 100. The second image (Fig. 1): voltage on X-ray tube 100 kV. Graphic modification: cut off; brightness 70; contrast1 50.
Sämtliche Werke, Anastasius Grün, 19th century
In this chapter concrete examples of application of above-mentioned principles on particular specimens of books are given with a view of setting the apparatus. Selection of the most suitable settings for obtaining optimum images proceeded by visual estimation of several images obtained at slightly different settings selected on the basis of mentioned principles. Modification of images proceeded in collective discussion in cross-disciplinary team – X-ray specialist, conservator, bookbinder, graphic designer. Here it concerns not only optimum extent of image lightness and suitable contrast; as it is obvious, in some cases it is necessary to make a compromise in selection of settings so that all requirements on image are satisfactorily met.
Radiography serves for detection of defects, it is possible to judge degree of degradation of an object as such. An important result is finding the method of the binding structure, condition of structural elements or unpredictable findings, e.g. inserted materials or other elements, secondary repairs or interventions, etc. – it all without damaging the original. Examples of particular results are presented here, acquired by this method with description of internal, hidden binding elements and structures – characteristic elements and defects could not be observable without application of this method.
It has been proved that hidden cavities, metal debris hidden in paper, pins and other metallic objects can be seen on the radiogram, which need not be visible on the surface. In addition to metal chips in paper, stains of iron oxides in paper, wire pins connecting twin sheets in a component, and other hidden metallic objects, there is a number of metallic components, which are visible. Also in the event of visible metallic components, radiography can bring new information. Metallic elements are most often made of iron, brass, or bronze. Elements made of iron may have surface treatment (e.g. surface layer of nickel) in order to increase resistance to corrosion.
Environment of books and book depository is chemically aggressive to metals. Volatile organic compounds, which cause corrosion, may release from paper, textile, parchment, leather, glues, and other materials. Optimum relative humidity in depositories is usually about 50±5 %. This combination is sufficient enough to cause damage to metal elements by corrosion. Metal elements may be of thin material, generally because of reduction of weight and price. If thin metal elements are weakened by corrosion, their strength can fall down so much that they fail to resist to mechanical strain, to which they are subject in books. Corrosion leads to dilution of material, to reduction of its strength, and migration of corrosion products to surroundings. It can be seen on radiogram. Migration of corrosion products can negatively affect the material, of which a book is made. Using X-ray radiation it is possible to observe also material defects in metal elements of bookbinding itself. All these observable phenomena make possible to estimate occurrence of aggravated mechanical properties, or lowered service life – and totally non-destructively. On the basis of this information it is possible to better select the most suitable restorer´s procedure, than without having this information.
Fig. 3 Separate wooden book cover partly coated with a metal plate. In the area, where metal layer is not placed, there are displayed (invisible by naked eye) year rings of wood itself. The book cover was placed directly on the detector covered with a foil, X-ray tube in distance 49 cm from the detector, voltage on X-ray tube 70 kV, current 300 A, irradiation time for image acquisition 1s. Graphic modification: cut off; retouch by the help of tools patch and pointed retouch brush; gamma correction 1.50; exposition +2.00; contrast 100 (application on the internal structure).
Nebeklíč, 19th century.
Fig. 4 Front board of the book. The bard is coated with bone slices, the sculpture is held in place with little metal nails. The book was placed 36 cm above the detector coated with a foil, X-ray tube in distance 64 cm from the detector, voltage on X-ray tube 110 kV, current 300 A, irradiation time for image acquisition 1 s. Graphic modification: cut off; levels: shift of white; brightness -30; contrast 100.
Albacha Posvátní zvukové, P. J. Herčík, 2nd half of 19th century.
Fig. 5 Book back sewn on raised bands. Ligaments themselves are formed of a simple cord. Seal up with strips of gauze is perceptible between the ligaments. Year rings are also well perceptible on wooden boards. The book placed 36 cm above the detector coated with a foil, X-ray tube in distance 49 cm from the detector, voltage on X-ray tube 90 kV, current 300 A, irradiation time for image acquisition 1 s. Graphic modification: cut off; retouch by the help of tools patch and pointed retouch brush; levels: shift of white; brightness 32; contrast 83.
Animadversiones in regulas et usum critices, R. P. Honorato and S. Maria, 1751.
Fig. 6 Book back with false ligaments. Incision for sewing in the backbone is distinctly visible, which is positioned outside placing of strips of false ligaments. The book placed 66 cm above the detector coated a foil, X-ray tube in distance 79 cm from the detector, voltage on X-ray tube 110 kV, current 300 A, irradiation time for image acquisition 1 s. Graphic modification: cut off; brightness 150; contrast 14; levels: shift of white.
Odyssey of Homer, William Cowper, 1855.
Fig. 7 Image of vertically placed book. Clips are fixed to the book cover with bent metal wire. The book placed directly on the detector coated with a foil, X-ray tube in distance 49 cm from the detector, voltage on X-ray tube 120 kV, current 300 A, irradiation time for image acquisition 1 s. Graphic modification: cut off; gamma correction 2.00; exposition +1.50.
Pomněnky ve vínek nebeský, Václav Beneš Třebízský, 19th century.
Fig. 8 Strips of clips of book cover. Damage of the wooden board with leather strips from perforated clips is perceptible in the upper part of the image. Migration of iron corrosion products and also fixation of strips by the help of little nails are perceptible in leather. The book placed directly on the detector coated with a foil, X-ray tube in distance 49 cm from the detector, voltage on X-ray tube 75 kV, current 300 A, irradiation time for image acquisition 1 s. Graphic modification: cut off; levels: shift of white; brightness 33; contrast 100; curves: increasing contrast. Animadversiones in regulas et usum critices, R. P. Honorato and S. Maria, 1751.
In some cases, when displaying units invisible by naked eye, it is difficult to determine their size, especially if there are not displayed any of its components of known sizes in a part of the book shown in the image. This problem can be solved by application of a scale manufactured specifically for purposes of radiography, as it is shown in Fig. 9.
Fig. 9 A hidden element in the front board of the book. The book (together with gauge with smallest division of 2 mm as a scale) placed 66 cm above the detector with coated foil, X-ray tube in distance 79 cm from the detector, voltage on X-ray tube 105 kV, current 300 A, irradiation time for image acquisition 1 s. Graphic modification: cut off; retouch by the help of tools patch and pointed retouch brush; gamma correction 1.50; exposition +1.10; brightness1 20; contrast1 100; contrast2 20.
Za černožlutou oponou (Behind black and yellow curtain), Jaroslav Kunz, 1st half of 20th century.
Non-destructive examination by the help of radiography will help non-destructively detect problematic material and its condition earlier, than serious damage occurs not only in material itself, but of the entire object – a book. Information acquired in this way serves for historical, artistic, scientific understanding of bookbinding. Radiography thus becomes an important tool for obtaining pieces of knowledge on bookbinding and its physical condition without destructive intervention. The method can be generally considered as safe for radiographed materials of bookbinding. Direct displaying follows only dispersion of particles in dependency on chemical composition of the material under examination. Parts of the object, which photons pass through without changes of energy, are shown as light spots in direct displaying (extent of interaction can be judged by comparison with surroundings of the object, where particles have nothing to interact with) – which is mostly just the case of paper and other organic materials, which do not contain heavier elements (other than C, N, O, H). Darker spots represent parts of the object containing heavy elements – classically metals (Fe, Cu …), they present areas, where interaction of primary particles of radiation occurs as well as loss of their original energy. The higher beam voltage, the smaller interaction with the material. A particle, which has kinetic energy high enough, will pass through the material without interacting with it anyhow – without loss of its energy. A particle with lower energy and longer wavelength, typically radiation of light, which the material is capable to absorb, calls up greater response with undesirable manifestations. Radiography thus represents for organic materials smaller stress than investigation in other wavelength of radiation.
In the paper, possibilities of the method are summarized, its parameters, but final evaluation of the method is possible only after research; now detection possibilities are pursued and influence upon radiographed materials. The objective of this paper is to introduce the particular method, not to compare it with other methods or describe them. Comparison of imaging methods will be a part of more extensive work, for example certified methods, as an output of the five-year experimental project. Testing of the effect of x-ray radiation on materials of bookbinding is a part of the partial phase of the five-year experimental project, which is still in progress. At present, possibilities of displaying individual materials are tested, and under what conditions it is possible to obtain relevant information. Examples of particular results acquired by this method are presented in chapter "Typical examples of suitable displaying components of bookbinding" – characteristic elements and defects could not be observable without utilization of this method.
This paper was created within the frame of endowment programme of the Ministry of Culture CR, NAKI II No. DG18P02OVV024 in particular, with the title "Use of imaging techniques for the study of hidden information in bookbinding" (2018–2022).
VÁVROVÁ, Petra, NEORALOVÁ, Jitka, HŘEBECKÁ Dana, KOHOUTOVÁ, Kristýna, KULÍČKOVÁ, Anna, MATYSOVÁ, Marie, POPELKOVÁ, Daniela and Tomáš BLECHA.
Non-destructive survey of internal structure of bookbinding by the help of x-ray radiation. Library: Librarian review, 2020, 31(1), …, ISSN 1801- 3252.
ALFELD, Matthias, et al. A mobile instrument for in situ scanning macro-XRF investigation of historical paintings. Journal of Analytical Atomic Spectrometry, 2013, 28.5: 760–767.
ALFELD, Matthias, et al. Optimization of mobile scanning macro-XRF systems for the in situ investigation of historical paintings. Journal of Analytical Atomic Spectrometry, 2011, 26.5: 899–909.
CREAGH, D. C. and David A. BRADLEY. Radiation in Art and Archeometry. Elsevier, 2000.
DUIVENVOORDEN, Jorien R., et al. Hidden library: visualizing fragments of medieval manuscripts in early-modern bookbindings with mobile macro-XRF scanner. Heritage Science, 2017, 5.1: 6.
FIALA, P., P. KOŇAS, M. FRIEDL, R. KUBÁSEK and P. ŠMÍRA. X-ray Diagnostics of Wood Invaded by Insect [online]. FEEC VUTBR, 2013 [cit. 16. 10. 2019]. Dostupné z: http://www.measurement.sk/M2013/doc/proceedings/303_Kubasek-2.pdf .
HRADILOVÁ, J., D. HRADIL, O. TRMALOVÁ and J. ŽEMLIČKA, J. Metodika pro vizualizaci vnitřní struktury malířského díla s využitím nových metod na bázi rentgenového záření [online]. Laboratoř ALMA, Akademie výtvarných umění v Praze, Ústav technické a experimentální fyziky ČVUT, 2015 [cit. 16. 10. 2019]. (In Czech: Methods for visualization of internal structure of paintings with utilization of new methods on the basis of x-ray radiation [online]. ALMA laboratory, Academy of beaux arts in Prague, Institute of technical and experimental physics, Czech Technical University, 2015 [ref. 16th Oct., 2019]). Available in: http://invenio.nusl.cz/record/203455/files/nusl-203455_1.pdf .
OSTERLOH, Kurt RS, et al. Fast neutron radiography and tomography of wood as compared to photon based technologies. In: Proceedings of DIR 2007 – International Symposium on Digital Industrial Radiology and Computed Tomography, Lyon, France. 2007. p. 25–27.
PIETIKÄINEN, Markku. Detection of knots in logs using x-ray imaging. VTT, Technical Research Centre of Finland, 1996.
POUYET, E., et al. Revealing the biography of a hidden medieval manuscript using synchrotron and conventional imaging techniques. Analytica chimica acta, 2017, 982: 20–30.
REDO-SANCHEZ, Albert, et al. Terahertz time-gated spectral imaging for content extraction through layered structures. Nature Communications, 2016, 7: 12665.
SCHREINER, M. and H. HOLLE. Documentation of Watermarks in Paper [online]. Institute of Sciences and Technology in Art a Institute of Conservation-Restoration, Academy of Fine Arts, Vienna, 2011 [cit. 16. 10. 2019]. Available in: http://www.restauratorenohnegrenzen.eu/erc/Publications/documents/ERC%20Newsletter_1_2011.pdf
TROJEK, T. and D. TROJKOVA. Several approaches to the investigation of paintings with the use of portable X-ray fluorescence analysis. Radiation Physics and Chemistry, 2015, 116: 321–325.
VAN AKEN, J. An improvement in Grenz radiography of paper to record watermarks, chain and laid lines. Studies in conservation, 2003, 48.2: 103–110.
VAN STAALDUINEN, Mark, et al. Comparing x-ray and backlight imaging for paper structure visualization. EVA-Electronic Imaging & Visual Arts, 2006, 108–113.
]]>Ing. Magda Součková, Ing. Petra Vávrová, Ph.D., Ing. Jan Francl / Národní knihovna České republiky (National Library of the Czech Republic), Klementinum 190, 110 00 Praha 1
So-called preventive conservation appears as the most effective from the long-term point of view for protection and preservation of heterogeneous materials of book collections, which is a set of measures leading to prolongation of service life of book collections, or setting such climatic parameters, which will slow or stop degradation processes evoked by external degradation factors (temperature, relative humidity, dust particles, concentration of air pollutants …). Part of preventive conservation is also production of protective cover, or box from alkaline cardboard of archive quality, and subsequent storage in depositories, where there are adjusted suitable climatic parameters for long-term storage of book collections.
Experience of the National Library of the Czech Republic with monitoring of climatic conditions in depositories over the past several tens of years, and development of monitoring methods is summarized in the paper. Brief interpretation of requirements follows for air quality for storage areas of book materials, parameters as temperature and relative air humidity, and light conditions, indoor and outdoor pollutants. Methods of air quality measurement are presented, followed by description of various types of depositories of the National Library CR. Past and present measurements of air parameters in depositories are presented in the end, as well as examples of particular results and their evaluation.
Air or atmosphere is gaseous envelopment of the Earth. It is formed of mixture of gases (78.084 % nitrogen, 20.948 % oxygen, 0.934 % argon, carbon dioxide, neon, helium, hydrogen, methane, krypton, ozone, xenon, and nitrogen oxides), and water vapour, it contains also solid and liquid particles (Leporelo, info, on line).
The National Library CR has in its foundation documents as one of the basic subjects of its activities established protection of book documents and collections, and their preservation in good physical conditions for future generations. Most of conventional book materials is of organic origin, especially paper, parchment, binding leather, and textile, cardboard and wooden book covers, recently also plastics. Indoor air quality of areas, in which book materials are located (depositories, study rooms, exhibition rooms), markedly affects speed of their degradation, and thereby also possibility of their preservation for future generations. Physical characteristics of indoor air are important, i.e. air temperature, relative humidity, light, and chemical parameters such as content and composition of pollutants.
Recommended climatic conditions for long-term storage of archive and book materials are mentioned in standard ČSN ISO 11799 "Information and documentation – Requirements for depositing archive and library documents".
Physical parameters
Generally speaking, lowering temperature and/or decreasing relative humidity prolong service life of book materials. For paper, recommended temperature for stocking is 2–18\°C with admissible daily change ±1°C, relative humidity 30–45 % with admissible daily change ±3 %. For parchment and leather (collagen materials), temperature interval is 2–18°C with admissible daily change ±1°C, relative humidity 50–60 % and admissible daily change ±3 %. Temperature and relative humidity are the most often, and at longest monitored parameters of environment air in book depositories. In the past common thermometers and hair hygrometers were used for their measurement, which indicated current values of the parameters. Thermohygrographs with recorders already recorded temperature and humidity continuously all week long, up to a month, but it was necessary to laboriously evaluate results from the acquired graphic records. At present thermohygrometers with memory are often utilized, or cable and wireless measuring systems, data loggers (data recorders), or systems sensors, which keep results of measurement in their memory as far as to the moment of downloading to PCs. or even send directly measured values to PC, so that it is possible to respond immediately to undesirable changes of climatic parameters in depositories.
Even light markedly harms organic materials, both its ultraviolet part (UV radiation, 400–10 nm), and infrared component (IR radiation, 760 nm–1 mm). The premises should be illuminated by a sources of light without UV radiation or with eliminated UV radiation (UV filters, UV-foils). Recommended illumination level of materials of book bindings should not exceed 50 lx. For illumination in depositories, where continuous operation is not expected, approximately 200 lx above the floor level is recommended. Maximum limit for admissible ultraviolet radiation is 10 μW/lm. For measurement of light intensity luxmeters are used, or data loggers with a function of measurement of light intensity and UV/IR radiation.
Chemical parameters
Generally, pollutants are impurities in environment, which come from natural or man-made sources. They can be defined as reactive chemical substances in gaseous, liquid or solid state (particles), which can be found in environment. Pollutants are formed by both external, and internal sources.
Concentrations of external pollutants depend on local climate, geographic location, type of industry, and transport facilities, used fuel, and all that. Among external pollutants with the highest degradation effect on book materials belong sulphur dioxide and other sulphur substances, nitrogen oxides, and ozone (Hatchfield 2002).
External pollutants also contain small particles: dust and aerosols. Some of these pollutants come also from internal sources: dinitrogen tetroxide from gas ¨boilers, hydrogen sulphide from some utility materials and as human bio-waste, ozone may be produced by activities of xerox or older models of laser printers. Dust is a relatively complex pollutant, which contains particles of sizes of 1 nm–100 µm of various origin, shapes and composition (Morawska, Salthammer, 2003) Fine submicron particles (< 1 µm) contain especially soot and organic substances emitted from transport and local heating, secondary organic particles of ammonium sulphate and nitrate, and also metals from waste incineration and industrial emissions. Particles from smoking or emitted from office equipment contribute to them also in internal environment. Coarse particles (> 1 µm) contain especially mineral particles from dust and emissions from transport and construction activities. In internal environment their source is usually cleaning, construction work, and especially visitors. They contribute especially by mineral dust brought on shoes and dresses, textile grains from clothing, and particles of dead skin. Microorganisms and mildew spores also belong to coarse particles. Various harmful effects correspond also to different origin and composition. Fine particles deposit on all accessible surfaces. Soot and organic materials cause contamination, secondary organic and inorganic particles (they were formed by reaction of primary particles emitted directly to air) may be of acidic nature and contribute to degradation of materials, often with catalytic effects of present metals (ASHRAE 2011). Secondary particles are also hygroscopic, and support thus dampening of surfaces (Seinfeld, Pandis, 2006). Coarse particles deposit only on horizontal surfaces facing upwards. Mineral particles are abrasive, and cause especially mechanical damage, particles from building activities are of alkaline nature. Deposited particles also absorb gaseous pollutants, and are suitable nutritive substrate for growth of microorganisms.
Recommended concentrations of air borne pollutants according to standard ISO/DIS 11799 are mentioned in Table 1. Units SI are given – the values are recalculated to concentrations in SI units.
Table 1 Recommended concentrations of air borne pollutants
Acetic acid, formic acid, and formaldehyde are the most acting internal pollutants on book materials. They are released from wood, some glues, colours, and also from proper book materials (owing to degradation of paper, acetate materials, etc.). Table 2 gives concentrations of these materials in natural environment and concentrations recommend for storage premises for collection objects.
Table 2 Volatile organic compounds from internal sources, which can be found inside buildings (Grzywacz, 2006)
Presence and concentration of contaminating materials can be measured directly by advanced instrumental methods (chemiluminiscence, infrared spectrometry, photometry, and the like.)1, or air samples are taken either actively by suction (Draeger tube, low-pressure cascade impactors)2, or passively. Samples are subsequently evaluated in a laboratory. For long-term measurements in depositories, passive samplers are used, which are located for a longer time in the depository (often for one month), and after it they are evaluated again in laboratory using instrumentally or visually (A-D strips, Purafil coupons, sampler Radiello, dosage meters EWO and MEMORY, etc.)3 (Součková, 2009).
Generally, to achieve higher quality of internal library air, and thus slow degradation of book materials, it is necessary to find out and nominate risks of damage of particular collection materials. Quality of internal air is necessary to determine for that. Further running measurements of climate quality is important for keeping optimum storage conditions as a precaution before speeding degradation.
Measurement of temperature and humidity in depositories of NL CR
The National Library CR located its collections in depositories in three localities. Permanent depository NL can be found in these buildings at present: Klementinum – Prague 1, Hostivař – Prague 15, and Neratovice – Central Bohemia region. These depositories are very different in their essence, no matter whether due to their location, or building type and their age.
Klementinum
It concerns a complex of historical buildings located in the centre of Prague. It originated from 16th century, and it was converted in 1930s for the needs of library. At present, the entire building of Klementinum, including depositories, passes through expansive reconstruction. In Klementinum, about two millions of books (either modern or historic) are located. Whereas it concerns a cultural memory, structural and other modifications are limited there. In the given object, air-conditioned depositories can be found (temperature and relative humidity are conditioned), in partly air-conditioned ones (only relative humidity is conditioned by the help of air *dampers), and no air-conditioned ones (neither temperature nor relative humidity are conditioned). Collections of books are located on stationary and also sliding (compact) bookshelves made of metal or wood (historic). Climatic conditions (temperature, relative humidity) are in a given object permanently monitored either by the help of wireless measuring system Hanwell, or by the help of portable thermohygrometer Commeter S 3120.
*humidifiers
Central depository Hostivař (CDH)
The depository is situated in the Prague suburb in the proximity of incineration plant of communal waste and busy automobile transport in Průmyslová Street. It concerns an object formed of a combination of a new building from 2012, and an older building opened in 1996 after *reconstruction of a manufacturing plant of a one-time state contribution organization Exhibitions from the middle of 20th century. In Hostivař, over 7 million of library collections are located (the new building – 2 millions of library collections, the converted building – 5 millions of library collections). The depositories are situated *in four stories in the new building, and *in three stories in the converted one. The deposit premises in both objects are windowless. Only air-conditioned depositories can be found in the objects (adjusted temperature and relative humidity). The library collections are placed either on mobile metal *racks (new building), or on stationary metal racks (converted building). Air temperature and relative humidity are in both objects permanently monitored by the help of wireless measuring system Hanwell.
*the reconstruction of the exhibition area
*on four floors
*on three floors
*shelves
Depository of reserve collections in Neratovice
The building erected in second half of 20th century is situated in the Central Bohemia in the suburb of Neratovice in flood areas of Elbe, and in the immediate vicinity of Spolana chemical plant. About 300 thousands of book entities were placed there. At present, sorting of collections and partial transport to other depositories is under way. Storage area, in which reserve collections are deposited, is located in three above-ground windowless stories. The depository is partly air-conditioned, only temperature is conditioned by the help of heating and ventilators. Library collections are located on stationary metal racks. Temperature and relative humidity in the depository are permanently monitored by the help of cable measuring system TQS.
Premises, in which library collections are placed, have been and are continually monitored, and in case of need, climatic parameters in them adjusted and regulated. For climate measurement (temperature, relative humidity) in depositories, wireless measuring system Hanwell, cable measuring system TQS, and portable recording thermohygrometers Commeter S 3120 are used. For measurement of light conditions (intensity of illumination, intensity of UV radiation), portable luxmeter Hanwell ULM and combined instruments Elsec 765 C are used. For measurement of dustiness, portable instrument Casella Microdust Pro is used.
Wireless measuring system Hanwell (Klementinum, Hostivař)
Wireless measuring system has been installed in Klementinum since 1998, and in Hostivař since 2017, and it is continuously extended to other storage and working spaces. Wireless measuring system Hanwell is formed of sensors (thermal, humidity, light), which transmit signal (by way of amplifier) in a form of radio waves to receiver in the control unit. Here the signal is transformed to particular values, which are then saved in memory of the control unit, and the measured values are send from there to PC, with installed programme for other evaluation (graphic, tabular, statistical).
Cable measuring system TQS (Neratovice)
Cable measuring system has been installed in Neratovice since 2004. Cable measuring system TQS is formed of sensors (thermal, humidity), which transfer the sensed signals to a module, where they are transformed to particular numerical values and transferred to Internet network, from where it is possible to inspect and evaluate the given values (as graphs, tables) by the help of PC.
Portable equipment for permanent measurement of climate /recording thermohygrometers/Commeter S 3120 (Klementinum, Hostivař)
Portable equipment for permanent climate measurement (temperature, relative humidity) are deployed in storage and working premises in Klementinum and also in Hostivař depositories.
Portable equipment saves measured values in internal memory, and it is possible to download stored data and carry out evaluation (as graphs, tables) by the help of PC with installed software.
Portable equipment for measurement of light luxmeter Hanwell ULM and combined instruments Elsec 765 C
Portable equipment for measurement of light serves for actual measurement of light conditions (intensity of illumination, intensity of UV radiation).
Portable equipment for measurement of dustiness Casella Microdust Pro
Portable equipment for measurement of dustiness serves for actual measurement of dustiness.
In addition to already performed routine measurements of temperature and air dampness, and light conditions in depositories NL CR, measurements of air borne pollutants have been and are as well as at present in progress in selected localities of these depositories.4
The first measurements of air borne pollutants were performed by the Czech Hydrometeorological Institute (ČHMÚ) in years 1991–1992, further in years 2006–2007 as a part of research programme of the Ministry of Culture "Research and development of new procedures in protection and preservation of precious written memories", which was solved in the National Library in years 2005–2011. It was thus possible to compare changes in pollutant concentrations after 15 years. Measurements were carried out using mobile measuring vehicle on the economic yard in premises of Klementinum (outdoor environment), and at the same time using separate measuring instruments for determination of SO2, NOx and O3 in depository of the Department of manuscripts and old printings – DMOP (internal environment). It concerned direct air analysis. It was found that quantity of SO2 in outdoor air compared to year 1992 significantly dropped (roughly six times), concentration of NOx increased both in external and internal environment of Klementinum, and ozone concentration in store room dropped compared to year 1991.
Measurement of concentration of air borne pollutants by direct air analysis is expensive, and therefore, several types of passive samplers were used for other measurements.
Indicator coupons Purafil are plastic bands half coated with a layer of silver, and half coated with a layer of copper, which may be located to environment under examination, and left there for a period of 30–60 days (Purafil 2020). It results in a layer of rust, which will be evaluated in laboratories of company Purafil, and its increase found out for a specific time interval. According to increase of a corrosive product, the monitored environment will be categorized to one of five classes of air cleanness. In depositories of NL CR, coupons were deployed in Klementinum (Slavonic library, so-called Fantovka, Baroque hall, Treasury DMOP, former Klementinum Gallery and cellar), in the depositories in Neratovice and in CDH in ground floor of the central store and in the store room of microfilms. Exposed coupon were evaluated in class C1 and C2, i.e. as fully clean and clean air, only room of Treasury DMOP was ranked to class C3 – medium air cleanness.
Other air quality measurements in NL CR were carried out using dosimeters EWO-G. This type of dosimeter was developed within the frame of European research project MASTER – Preventive Conservation Strategies for Protection of Organic Objects in Museums, Historic Building and Archives (CORDIS 2005). Measuring section of the dosimeter consists of glass platelet coated with a film of organic polymer of constant thickness. The polymer reacts with surrounding environment and becomes less transparent. The change is expressed as change in UV absorption at 340 nm measured using a spectrophotometer. Exposure time is three months, and after evaluation, tested environment is again ranked to classes 1–5. In premises of the National Library CR, four dosimeters in all were deployed. In Klementinum, measurements were carried out in the Treasury room DMOP, in th Baroque hall, and inside display case in former Klementinum Gallery. The last dosimeter was placed in the Central depository Hostivař in storeroom DMOP. The best quality of environment – Class 1, which indicate environment suitable for archives, was also found there. Remaining three measured environments rank to Class 2: suited rather for the needs of museums than depositories for long-term storage. The display case and the Treasury room DMOP at the same time approached Class 1 – suitable for archive storage, while the Baroque hall already was at the upper limit with Class 3 – unsuitable for storage.
Other type of samplers, which were used for measuring gaseous pollutants in depositories of NL CR, and till today they monitor concentration of sulphur and nitrogen oxides in the Baroque hall, are passive samplers of company SVÚOM. In years 2007–2008 they were placed in premises of Klementinum in nine measuring sites (depositories and study rooms), and in CDH on three measuring sites, both indoor and outdoor. The samplers were exposed for one month, and then evaluated in laboratory of SVÚOM.
Identified concentrations of SO2 in outdoor environment of Klementinum and Hostivař were comparable. Concentrations found in individual internal standpoints highly fluctuated. The highest values in Klementinum were found in the Baroque hall (entering of visitors), and in manuscript study room (opening of windows). In Hostivař, outdoor concentration of SO2 was higher than concentration in store room.
Concerning nitrogen oxides, large quantities are produced by automobile transport. One of samplers for measuring external concentrations of NOx was placed in Křížovnická Street at the level of 2nd floor, nevertheless, the values measured with it were higher than values of a sampler placed between ground floor and 2nd floor on courtyard of Klementinum. Values measured in CDH were lower, which again is connected with the building location. Values of NOx in depositories in CHD and in Klementinum are comparable and lower than the values in others premises of interest, routinely accessible to workers and visitors of the National Library CR.
Passive samplers of company SVÚOM have been used since 2012 for continuous measurement of concentration of sulphur and nitrogen oxides in the Baroque hall – Fig. 1.
Fig. 1 Measurement of NOx concentration in the Baroque hall in period 2012–2018 (μg.m3)
Research project "Monitoring and evaluation of internal environment in the Baroque hall of NL CR", supported by Norwegian funds dealt with evaluation of quality of internal environment of the Baroque hall in Klementinum, which serves partly as depository of historical collections, and partly as a section of visit route for public. The Health Institute with a seat in Ústí nad Labem carried out measurements of content of internal pollutants, VOCs (volatile organic compounds) in particular, in the Baroque hall and adjacent premises (a total of five sampling sites, including outdoor air) in July and November 2009, see Fig. 2. Air samples were collected, which were subsequently analysed in laboratory.
Fig. 2 Concentration of acetic acid in the corridor next to the Baroque hall and in adjacent depository (μg.m-3), active sampling, the Health Institute
Found concentrations of acetic acid, especially in closed areas of the depository, highly exceeded the recommended values (Table 3).
Table 3 Concentrations of formic and acetic acids in the Baroque hall, as measured by passive sampler NILU
High concentrations of acetic acid measured by the Health Institute are confirmed by the results of measurement of Norwegian Institute for Air Research – NILU, a partner of the project of Norwegian funds (Table 3).
Other partner of this project of Norwegian funds was the Institute of chemical processes of the Academy of Sciences CR (ÚCHP), which specializes on measurement of air quality in term of concentrations of dust particles and carbon dioxide. It carries out also chemical analyses of particles and measurement of gaseous pollutants using passive samplers. In a link to the study of air quality in the Baroque hall carried out with the use of the grant of Norwegian funds before reconstruction of the hall (2011), ÚCHP elaborated a comparative study in late 2017, which ought to find out, how air quality changed after reconstruction. In measurement in 2008, the Baroque hall was a part of visiting route, and tourists entered it. Measurement of concentrations of dust particles showed that presence of visitors increased concentration of particles up to six times. Increase in concentrations always started with entry of the first visitors, and reached a maximum at the end of opening hours. Particles concentration then gradually dropped to original values owing to their deposition on accessible surfaces (Fig. 3). Identical time course exhibited concentrations of carbon dioxide exhaled by visitors (Fig. 4).
Fig. 3 Time course of numerical concentration of coarse particles of size faction 2.5–20 µm in internal environment of the Baroque hall during measurement in 2008 (Smolík, 2018)
Fig. 4 Time course of concentration of carbon dioxide in internal environment of the Baroque hall during measurement in 2008 (Smolík, 2018)
During measurements in 2017, which were carried out already after reconstruction of the hall, change in opening hours occurred, in the first phase hall was still closed for public (13th Oct. - 13th Doc. 2017), and in the second phase (14th Dec. 2017 - 21st Jan. 2018) visits were already under way. It made possible to find out, to what degree visits affected air quality in the hall. External and internal concentrations of fine dust particles of fraction 0.3–1 µm are compared in Fig. 5. It can be seen from the figure that internal concentrations imitate the external ones, but they are markedly lower, and also that the presence of visitors (opened for visits in 14th Dec.) had virtually no effect on concentrations of fine particles.
Fig. 5 Time record of external (outdoor) and internal (indoor) concentrations of fine dust particles of fraction 0.3–1 µm (Smolík, 2018)
Time courses of external and internal concentrations of particles of fraction 1–2,5 µm are compared in Fig. 6. It can be seen from the figure that external air had very small influence on internal concentrations, because most of particles of this size was almost quantitatively captured by the buildings mass.
Fig. 6 Time record of external (outdoor) and internal (indoor) concentrations of dust particles of fraction 1–2.5 µm (Smolík, 2018)
Fig. 7 shows comparison of external and internal concentrations of coarse particles of fraction 2.5–10 µm. A pronounced effect of visitors, observed also in previous study in 2008, is perceptible from the figure.
Fig . 7 Time record of external (outdoor) and internal (indoor) concentrations of coarse dust particles of fraction 2.5-10 µm (Smolík, 2018)
Measurements of air quality on various levels have been and are in progress in depositories of NL CR . The basis is measurement of relative humidity and air temperature in all types of depositories. The depositories in Hostivař and Neratovice are not equipped with windows, light conditions are then necessary to be monitored preferentially in depositories in the historic building of Klementinum. In the new building of the depository in Hostivař regulation of climatic parameters is at very good level, and only check of possible variations or accidents is desirable.
Most information was found on air quality in the Baroque hall on the premises of Klementinum. It is given by the fact that it concereds both the depository of historic book collection, and the area incorporated into sightseeing route, and therefore accessible to public, even though only in limited extent. The Baroque hall is certainly also an attractive area in light of its historic value. Concentrations of external pollutants (SO2, NOx), internal pollutants (acetic acid), and dust particles were also monitored there. Just measurements performed in the Baroque hall show that entrance of a larger number of persons has a negative influence on air in the depository, and therefore also on condition on historic collections deposited in it.
The paper summarises information gained for several tens of years of monitoring of climatic parameters in various types of depositories in various types of buildings in the National Library of the Czech Republic (NL CR). This summary should serve for inspiration to libraries, how to monitor air quality in depositories, and how so-called preventive preservation minimizes damage of book collections. The costs on preventive preservation are in a result much lower than afterwards costly restoration of damaged pieces.
This paper was prepared within the frame of institutional support of the National Library of the Czech Republic by the Ministry of Culture CR as a research institution (IP DKRVO), Section 7: Protection of library collections.
ASHRAE, American Society of Heating, Refrigerating and Air-Conditioning Engineers, Inc. 2011. Heating, Ventilating, and Air-Conditioning Applications SI Edition, Part 23. Museums, Galleries, Archives, and Libraries, 1791 Tullie Circle, N.E., Atlanta, GA 30329, 2011, ISBN 978-1-936504-07-7.
CORDIS, 2005, available from: https://cordis.europa.eu/project/id/EVK4-CT-2002-00093
ČSN ISO 11799 „Informace a dokumentace – Požadavky na ukládání archivních a knihovních dokumentů", 2006, s. 8–9 (Czech standard ČSN ISO 11799 "Information and documentation – Requirements for deposition of archive and library documents", 2006 pp.8-9(.
ĎUROVIČ, Michal et al. Restaurování a konzervování archiválií a knih. Vyd. 1. Praha: Paseka, 2002. 517 s. ISBN 80-7185-383-6 (in Czech: Restoration and preservation of archival documents and books. 1st edition, Prague, Paseka, 2002, p. 517. ISBN 80-7185-383-6).
GRZYWACZ, C. M., Monitoring for Gaseous Pollutants in Museum Environments, 2006, s. 110. ISBN13: 978-0-89236-851-8.
HATCHFIELD, Pamela. B., 2002. Pollutants in the museum environment. Archetype Publications Ltd., ISBN 1-873132-96-4.
Leporelo.info Atmosféra (Air) available on: https://leporelo.info/atmosfera.
MORAWSKA, L. a T. SALTHAMMER, 2003. Indoor Environment: Airborne Particles and Settled Dust. New York: John Wiley and Sons. ISBN 978-3-527-30525-4.
PURAFIL, 2020, available on: https://www.purafil.com/products/monitoring/passive-monitoring/
SEINFELD, J. H. a S. N. PANDIS, 2006. Atmospheric Chemistry and Physic, second edition. Hoboken: John Wiley and Sons. ISBN 978-0-471-72018-8.
SMOLÍK, J. Kvalita ovzduší v Barokním knihovním sále Národní knihovny v Praze, Klementinum, zpráva 2018, ÚCHP AV (in Czech: Air quality in the Baroque library hall of the National Library in Prague, Klementinum, report 2018, ÚCHP AV).
SOUČKOVÁ, M. Měření polutantů v Národní knihovně České republiky, XIV. Seminář restaurátorů a historiků, Brno 2009, ISBN 978-80-7469-007-5 (in Czech: Measurement of pollutants in the National Library of the Czech Republic, XIV. Seminar of restorers and historians, Brno 2009, ISBN 978-80-7469-007-5).
SOUČKOVÁ, Magda, Petra VÁVROVÁ, Jan NOVOTNÝ, Jana DŘEVÍKOVSKÁ, Hana PAULUSOVÁ, Benjamin BARTL, Lenka BARTLOVÁ, Bronislava BACÍLKOVÁ, Roman STRAKA, Michal ĎUROVIČ, Ludmila MAŠKOVÁ a Jiří SMOLÍK.. Památkový postup „Zlepšení kvality vnitřního ovzduší knihoven a archivů s cílem významně omezit degradaci knihovních a archivních materiálů" NK ČR. 2015. (in Czech: Conservation procedure "Improvement of internal air quality in libraries and archives with the aim of significantly limit degradation of books and archive materials"). Available on: http://www.nusl.cz/ntk/nusl-260952.
Foundation document of the National Library of the Czech Republic, p. 2, available on: https://www.nkp.cz/soubory/ostatni/zrizovaci-listina-nk.pdf.
SOUČKOVÁ, Magda, VÁVROVÁ, Petra a Jan FRANCL. Měření kvality ovzduší v depozitářích Národní knihovny České republiky – metody měření a vybrané výsledky. Knihovna: knihovnická revue, 2020, 31(1), ..... ISSN 1801-3252 (in Czech: Measurement of air quality in depositories of the National Library of the Czech Republic – Measurement methods and selected results. Library: Librarian review, 2020, 31(1), ..... ISSN 1801- 3252.
1 Chemiluminiscence – measurement of light energy emitted in a result of chemical reaction infrared spectrometry – measurement of emission or absorption spectra, wave length of which falls to the region of infrared radiation.
Photometry – spectroscopic analytical method of measurement of light energy absorption by the help of photometers with visual detection.
2 Details on mentioned methods in the Conservation procedure "Improvement of internal air quality in libraries and archives with the aim of significantly limit degradation of books and archive materials"). Prague 2015, available on: http://www.nusl.cz/ntk/nusl-260952
4 Pollutant – a material polluting a certain environment, in our case depositories, or their external neighbourhood.
Draeger tube: designation of a detection tube – trade name, the tubes are used for detection of selected chemical substances, and are designed for orientation determination of harmful gases in air (e.g. oxides of sulphur and nitrogen, ozone etc.).
Passive samplers: Air analysis may proceed either directly, or obtained samples may be analysed. Sample collection is carried out passively or actively. Passive samplers requiring laboratory analyses are simpler for routine measurements. The user only exposes the equipment, seal it, and send it for analysis. Analytical laboratory determines volume of tested air, amount of detected pollutants, and calculates concentrations. In most directly readable samplers the user must take into account duration of exposure, compensate it to deviation from standard duration of exposure, and determine concentrations of pollutants according to colour changse. Because reading of colours is subjective, it may be a source of inaccuracy in results, an experience operator minimizes this problem. Price of passive samplers is relatively low. Qualitative directly readable passive samplers (coupons) are easier for use, less complicated, and cheaper than quantitative laboratory analysable equipment (open-path diffusion tube). Lower accuracy as compared to laboratory analyse may be sufficient for confirmation of polluted environment.
Low-pressure cascade impactors: They serve for determination of size distribution of mass concentration and chemical composition of particles, e.g. of type Berner; they separate particles to ten size fractions. Obtained samples are analysed by gravimetry, ion exchange chromatography (water soluble ions), and PIXE method (Particle Induced X- ray Emission, determination of elements).
A-D strips are coloured paper strips – indicators, which detect and measure relevance of so-called acidity syndrome in film pads or photographic materials manufactured from cellulose acetate. These strips inserted into box with films or negatives change colour according to the extent of acidity – with higher acidity strips change colour from original blue to green-blue, green, green-yellow, up to brightly yellow. The result is determination of damage intensity or degree of degradation of acetate films or negatives, and suitability or unsuitability of their present storage.
Coupons Purafil: filtration material Purafil Select Chemisorbant removes sulphane, sulphur dioxide, dinitrogen tetroxide, and formaldehyde from air. It is formed of ball-shaped, porous granules. The granules are manufactured of aluminium oxide and a bonding agent impregnated with potassium permanganate, which oxidizes gaseous pollutants and thus removes them permanently from environment.
Sampler Radiello is a commercial equipment or a personal monitor (badges), and varies from tubes by geometry. Active surface is closed in a plastic or teflon cover, and physical diffusion barrier is placed 1 mm up to 1 cm above the active surface. It concerns adsorption filling and diffusion body of porous polyethylene of various thickness, porosity, and pore sizes), manufacturer Radiello, Sigma-Aldrich, 2006.
]]>

